文本分类是NLP应用最广的任务之一,可以被应用到多个领域中,包括但不仅限于:情感分析、垃圾邮件识别、商品评价分类...
情感分析是一个自然语言处理中老生常谈的任务。情感分析的目的是为了找出说话者/作者在某些话题上,或者针对一个文本两极的观点的态度。这个态度或许是他或她的个人判断或是评估,也许是他当时的情感状态(就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)。其可以用于数据挖掘、Web 挖掘、文本挖掘和信息检索方面得到了广泛的研究。可通过 AI开放平台-情感倾向分析 线上体验。

本项目开源了一系列模型用于进行文本建模,用户可通过参数配置灵活使用。效果上,我们基于开源情感倾向分类数据集ChnSentiCorp对多个模型进行评测。
情感分析任务中关键技术是如何将文本表示成一个携带语义的文本向量。随着深度学习技术的快速发展,目前常用的文本表示技术有LSTM,GRU,RNN等方法。
PaddleNLP提供了一系列的文本表示技术,如seq2vec模块。
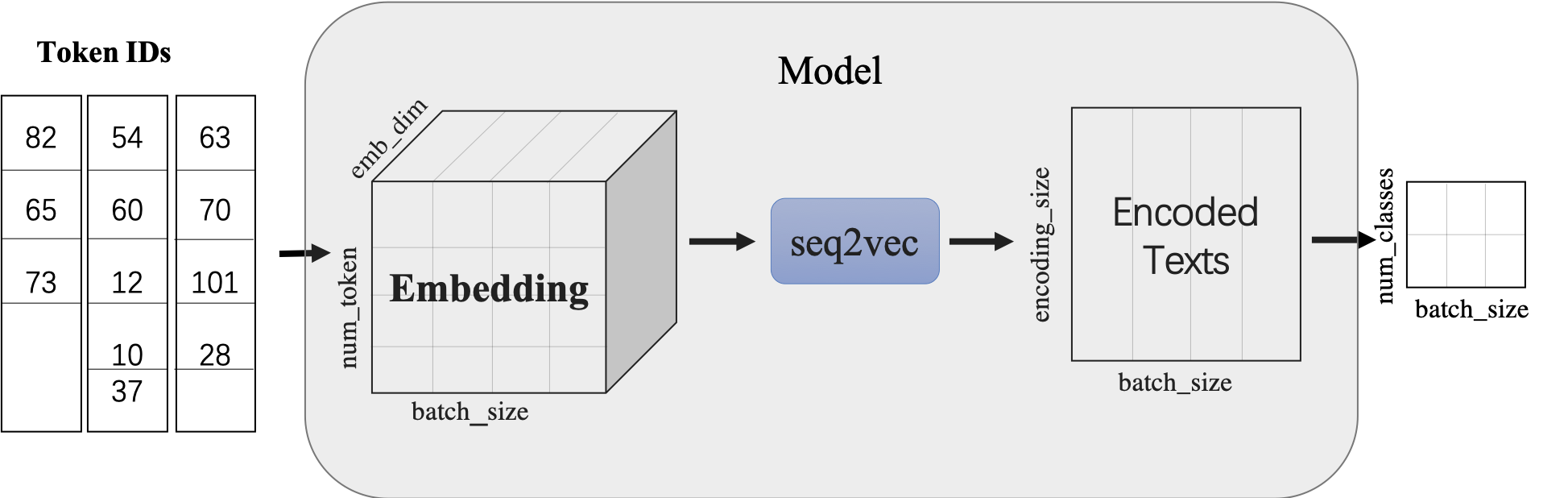
paddlenlp.seq2vec 模块作用为将输入的序列文本表征成一个语义向量。
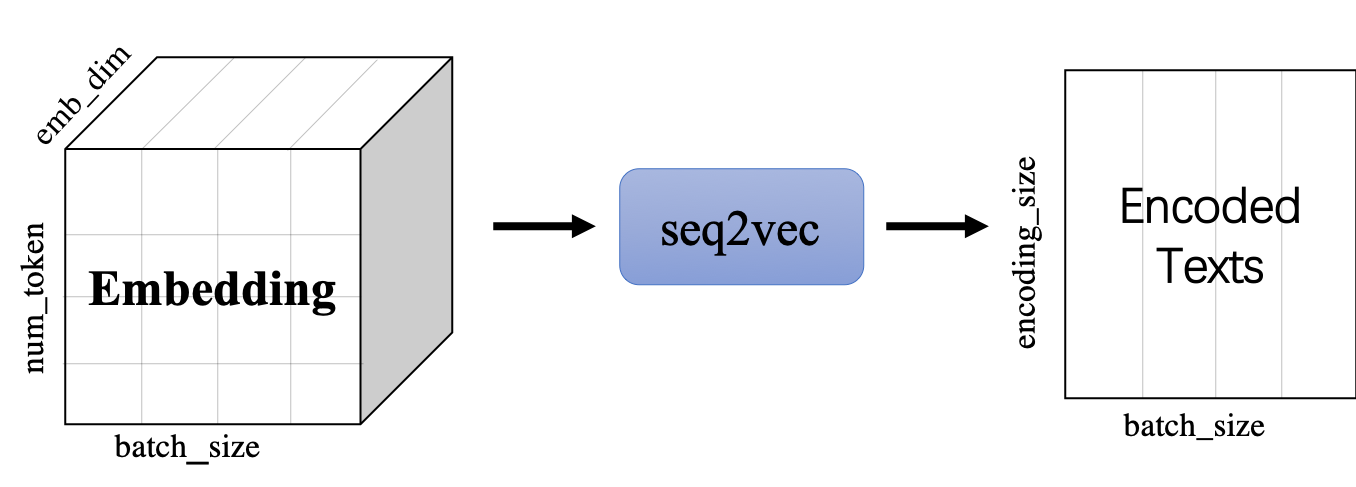
本项目通过调用seq2vec中内置的模型进行序列建模,完成句子的向量表示。包含最简单的词袋模型和一系列经典的RNN类模型。
seq2vec模块
- 功能是将序列Embedding Tensor(shape是(batch_size, num_token, emb_dim) )转化成文本语义表征Enocded Texts Tensor(shape 是(batch_sie,encoding_size))
- 提供了
BoWEncoder,CNNEncoder,GRUEncoder,LSTMEncoder,RNNEncoder等模型BoWEncoder是将输入序列Embedding Tensor在num_token维度上叠加,得到文本语义表征Enocded Texts Tensor。CNNEncoder是将输入序列Embedding Tensor进行卷积操作,在对卷积结果进行max_pooling,得到文本语义表征Enocded Texts Tensor。GRUEncoder是对输入序列Embedding Tensor进行GRU运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。LSTMEncoder是对输入序列Embedding Tensor进行LSTM运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。RNNEncoder是对输入序列Embedding Tensor进行RNN运算,在运算结果上进行pooling或者取最后一个step的隐表示,得到文本语义表征Enocded Texts Tensor。
seq2vec提供了许多语义表征方法,那么这些方法在什么时候更加适合呢?
-
BoWEncoder采用Bag of Word Embedding方法,其特点是简单。但其缺点是没有考虑文本的语境,所以对文本语义的表征不足以表意。 -
CNNEncoder采用卷积操作,提取局部特征,其特点是可以共享权重。但其缺点同样只考虑了局部语义,上下文信息没有充分利用。
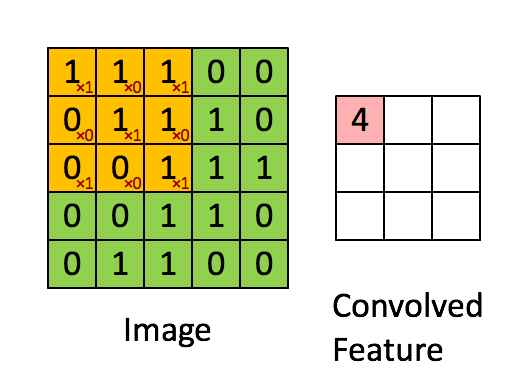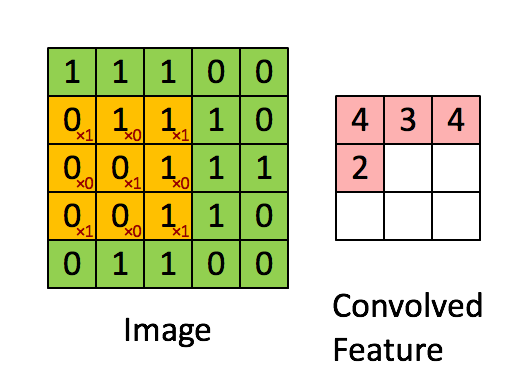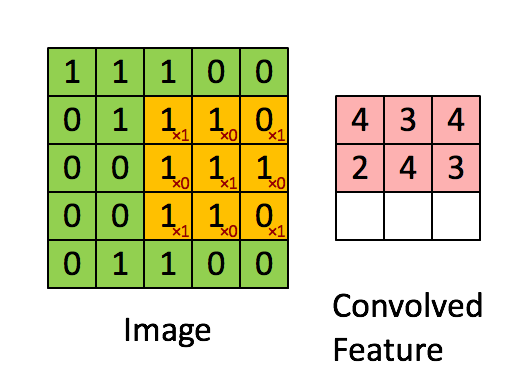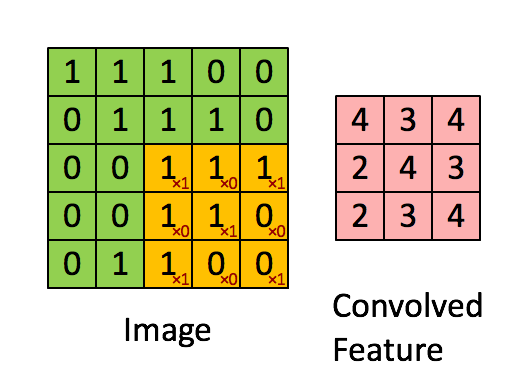
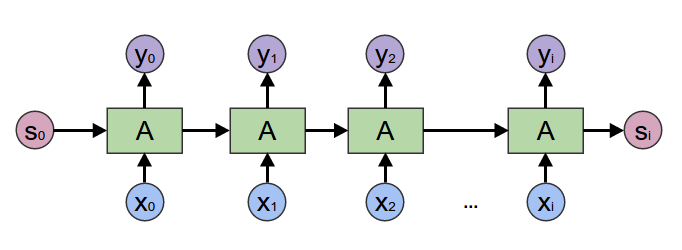
RNNEnocder采用RNN方法,在计算下一个token语义信息时,利用上一个token语义信息作为其输入。但其缺点容易产生梯度消失和梯度爆炸。
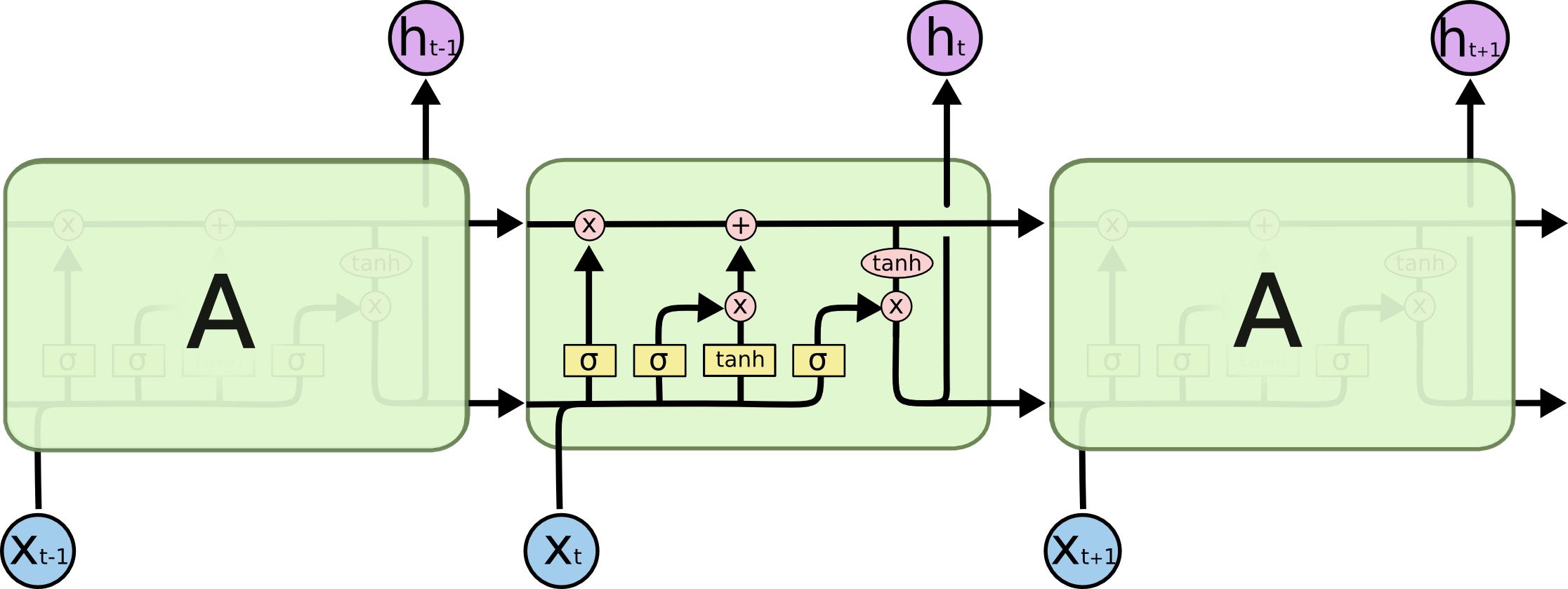
LSTMEnocder采用LSTM方法,LSTM是RNN的一种变种。为了学到长期依赖关系,LSTM 中引入了门控机制来控制信息的累计速度, 包括有选择地加入新的信息,并有选择地遗忘之前累计的信息。
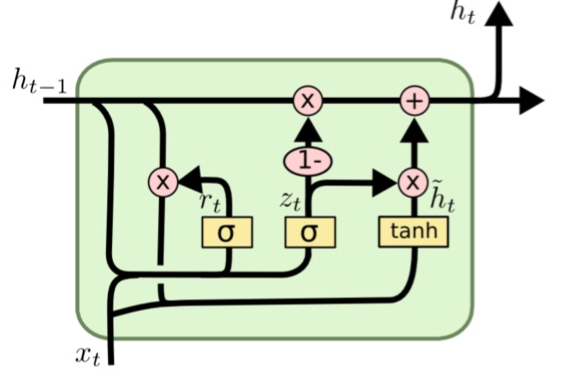
GRUEncoder采用GRU方法,GRU也是RNN的一种变种。一个LSTM单元有四个输入 ,因而参数是RNN的四倍,带来的结果是训练速度慢。 GRU对LSTM进行了简化,在不影响效果的前提下加快了训练速度。
| 模型 | 模型介绍 |
|---|---|
| BOW(Bag Of Words) | 非序列模型,将句子表示为其所包含词的向量的加和 |
| RNN (Recurrent Neural Network) | 序列模型,能够有效地处理序列信息 |
| GRU(Gated Recurrent Unit) | 序列模型,能够较好地解决序列文本中长距离依赖的问题 |
| LSTM(Long Short Term Memory) | 序列模型,能够较好地解决序列文本中长距离依赖的问题 |
| Bi-LSTM(Bidirectional Long Short Term Memory) | 序列模型,采用双向LSTM结构,更好地捕获句子中的语义特征 |
| Bi-GRU(Bidirectional Gated Recurrent Unit) | 序列模型,采用双向GRU结构,更好地捕获句子中的语义特征 |
| Bi-RNN(Bidirectional Recurrent Neural Network) | 序列模型,采用双向RNN结构,更好地捕获句子中的语义特征 |
| Bi-LSTM Attention | 序列模型,在双向LSTM结构之上加入Attention机制,结合上下文更好地表征句子语义特征 |
| TextCNN | 序列模型,使用多种卷积核大小,提取局部区域地特征 |
| 模型 | dev acc | test acc |
|---|---|---|
| BoW | 0.8970 | 0.8908 |
| Bi-LSTM | 0.9098 | 0.8983 |
| Bi-GRU | 0.9014 | 0.8785 |
| Bi-RNN | 0.8649 | 0.8504 |
| Bi-LSTM Attention | 0.8992 | 0.8856 |
| TextCNN | 0.9102 | 0.9107 |
以下是本项目主要代码结构及说明:
rnn/
├── deploy # 部署
│ └── python
│ └── predict.py # python预测部署示例
├── export_model.py # 动态图参数导出静态图参数脚本
├── model.py # 模型组网脚本
├── predict.py # 模型预测
├── utils.py # 数据处理工具
├── train.py # 训练模型主程序入口,包括训练、评估
└── README.md # 文档说明
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])在模型训练之前,需要先下载词汇表文件word_dict.txt,用于构造词-id映射关系。
wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txtNOTE: 词表的选择和实际应用数据相关,需根据实际数据选择词表。
我们以中文情感分类公开数据集ChnSentiCorp为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证
CPU 启动:
python train.py --vocab_path='./senta_word_dict.txt' \
--device=cpu \
--network=bilstm \
--lr=5e-4 \
--batch_size=64 \
--epochs=10 \
--save_dir='./checkpoints'GPU 启动:
unset CUDA_VISIBLE_DEVICES
python -m paddle.distributed.launch --gpus "0" train.py \
--vocab_path='./senta_word_dict.txt' \
--device=gpu \
--network=bilstm \
--lr=5e-4 \
--batch_size=64 \
--epochs=10 \
--save_dir='./checkpoints'XPU 启动:
python train.py --vocab_path='./senta_word_dict.txt' \
--device=xpu \
--network=lstm \
--lr=5e-4 \
--batch_size=64 \
--epochs=10 \
--save_dir='./checkpoints'以上参数表示:
vocab_path: 词汇表文件路径。device: 选用什么设备进行训练,可选cpu、gpu或者xpu。如使用gpu训练则参数gpus指定GPU卡号。目前xpu只支持模型网络设置为lstm。network: 模型网络名称,默认为bilstm, 可更换为bilstm,bigru,birnn,bow,lstm,rnn,gru,bilstm_attn,cnn等。lr: 学习率, 默认为5e-5。batch_size: 运行一个batch大小,默认为64。epochs: 训练轮次,默认为10。save_dir: 训练保存模型的文件路径。init_from_ckpt: 恢复模型训练的断点路径。
程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的save_dir中。
如:
checkpoints/
├── 0.pdopt
├── 0.pdparams
├── 1.pdopt
├── 1.pdparams
├── ...
└── final.pdparams
NOTE:
- 如需恢复模型训练,则init_from_ckpt只需指定到文件名即可,不需要添加文件尾缀。如
--init_from_ckpt=checkpoints/0即可,程序会自动加载模型参数checkpoints/0.pdparams,也会自动加载优化器状态checkpoints/0.pdopt。 - 使用动态图训练结束之后,还可以将动态图参数导出成静态图参数,具体代码见export_model.py。静态图参数保存在
output_path指定路径中。 运行方式:
python export_model.py --vocab_path=./senta_word_dict.txt --network=bilstm --params_path=./checkpoints/final.pdparams --output_path=./static_graph_params其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。
导出模型之后,可以用于部署,deploy/python/predict.py文件提供了python部署预测示例。运行方式:
python deploy/python/predict.py --model_file=static_graph_params.pdmodel --params_file=static_graph_params.pdiparams --network=bilstm启动预测:
CPU启动:
python predict.py --vocab_path='./senta_word_dict.txt' \
--device=cpu \
--network=bilstm \
--params_path=checkpoints/final.pdparamsGPU启动:
export CUDA_VISIBLE_DEVICES=0
python predict.py --vocab_path='./senta_word_dict.txt' \
--device=gpu \
--network=bilstm \
--params_path='./checkpoints/final.pdparams'XPU启动:
python predict.py --vocab_path='./senta_word_dict.txt' \
--device=xpu \
--network=lstm \
--params_path=checkpoints/final.pdparams将待预测数据分词完毕后,如以下示例:
这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般
怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片
作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。
处理成模型所需的Tensor,如可以直接调用preprocess_prediction_data函数既可处理完毕。之后传入predict函数即可输出预测结果。
如
Data: 这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 Lable: negative
Data: 怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片 Lable: negative
Data: 作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。 Lable: positive
关于LSTM、GRU、CNN更多信息参考: