🌐 Homepage | 🏆 Leaderboard | 🤗 MM-IQ | 📖 MM-IQ Paper
This repo provides the evaluation code of the MM-IQ benchmark.
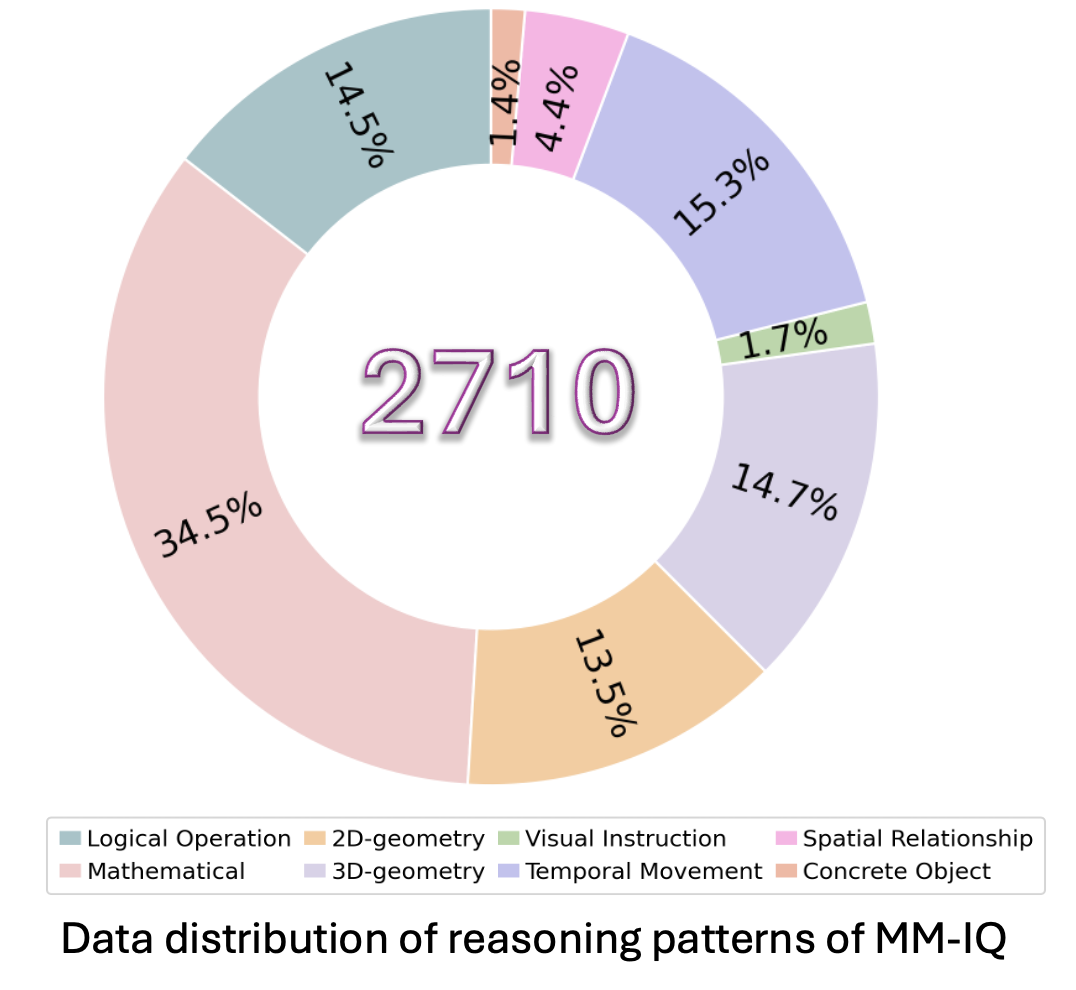
IQ testing has served as a foundational methodology for evaluating human cognitive capabilities, deliberately decoupling assessment from linguistic background, language proficiency, or domain-specific knowledge to isolate core competencies in abstraction and reasoning. Yet, artificial intelligence research currently lacks systematic benchmarks to quantify these critical cognitive dimensions in multimodal systems. To address this critical gap, we propose MM-IQ, a comprehensive evaluation framework comprising 2,710 meticulously curated test items spanning 8 distinct reasoning paradigms.
Through systematic evaluation of leading open-source and proprietary multimodal models, our benchmark reveals striking limitations: even state-of-the-art architectures achieve only marginally superior performance to random chance (27.49% vs. 25% baseline accuracy). This substantial performance chasm highlights the inadequacy of current multimodal systems in approximating fundamental human reasoning capacities, underscoring the need for paradigm-shifting advancements to bridge this cognitive divide.
For more detailed information, please refer to MM-IQ Dataset.
We have uploaded a demo to illustrate how to access the MM-IQ dataset on Hugging Face, available at hugging_face_dataset_demo.ipynb.
Please refer to MM-IQ Evaluation for more detailed information.
🎯 MM-IQ Evaluation
- We have released MM-IQ dataset with 2710 problems, across eight reasoning patterns.
- With our evaluation folder, you can use the LMM's response or the parsed prediction as input to get the performance of MM-IQ.
The guidelines for the annotators emphasized strict compliance with copyright and licensing rules from the initial data source, specifically avoiding materials from websites that forbid copying and redistribution. If you encounter any data samples potentially breaching the copyright or licensing regulations of any site, we encourage you to contact us. Upon verification, such samples will be promptly removed.
- Huanqia Cai: [email protected]
Our code is based on MMMU. We thank the authors of MMMU for their great work and clean code.
@article{cai2025mm,
title={MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models},
author={Cai, Huanqia and Yang, Yijun and Hu, Winston},
journal={arXiv preprint arXiv:2502.00698},
year={2025}
}