| Example | Services | Usecases |
|---|---|---|
| Lambda Example showing Media Transformation | S3 APIG λ | multi-platform media, content delivery pipeline, on-demand image resizing |
| Deriving Multiple Data Format from Single Source | S3 SNS λ | event-driven system, Processing data logs to produce multiple result derivatives, convert media to multiple formats |
| Real-Time Data Processing Example using AWS Lambda | Kinesis λ | λ polls kinesis streams, one Lambda function is invoked every 200ms per shard, Website clickstream, Payment transactions, IT logs, Location-based tracking, Stream-based model (event source mapping), Event structure model(batch async) |
| Custom Logic Workflows using AWS Lambda | SNS StepFunctions λ | complex repeatable scenarios, Customer onboarding, shopping Cart Management, Drip Marketing, Loyalty programmes |
| Change Data Capture with AWS Lambda | DynamoDB Streams λ SNS DynamoDB Cloudwatch | analyze and keep track of the changes made in the database, eventual consistency, Cross Region Replication, Filtering, Monitoring, Auditing, Notifications |
| AWS Lambda Example showing Custom Alexa Skills | Alexa skill λ | Adding a meeting to the calendar, Finding out the nearest coffee shop, Create a reminder, Playing the music |
| Automated Stored Procedures using AWS Lambda | Aurora λ SES SNS CloudWatch DynamoDB | traditional stored procedures have become a pain point in terms of consuming CPU resources, Send an email using SES,Issue a notification using SNS, Insert publish metrics to CloudWatch, Update a DynamoDB table, Implement complex ETL & workflows |
| Combining AWS Lambda example with Amazon RedShift (Data Warehouse) | λ Redshift SNS | ETL , Single region multiple copies, Creating multiple copies of redshift clusters, Responding to failures/incidents |
| Serverless Image Recognition Engine | Cognito λ StepFunctions Rekognition DynamoDB | Personalizing not just the content but images |
| Serverless Text-to-Speech | APIG S3 DynamoDB SNS Polly | Amazon Polly converts the text into the audio in the same language as the text |
| Personalized Content Delivery through AWS Lambda | APIG λ Cloudserach | Personalisation |
| Lambda Architecture for Batch and Stream Processing | S3 Glue λ EMR Kinesis Athena | |
| Optimize Delivery of Trending, Personalized News Using Amazon Kinesis and Related Services | Cloudformation stack EMR Redshift S3 SNS λ | convert data sets into Data Models |
| Scrape 300k prices per day from Google Flights | SQS λ Chalice DynamoDB Pyppeteer GithubActions Dashbird | scraping using two lambdas - one for triggering , other for scraping |
| Optimize Delivery of Trending, Personalized News | Kinesis Data Streams, S3, Kinesis Data Analytics, Firehose, λ, fluentd, DynamoDB, RDS, Redshift, Athena | Personalization: Deliver articles based on each user’s attributes, past activity logs, and feature values of each article.Trends analysis/identification: Optimize delivering articles using recent (real-time) user activity logs—to incorporate the latest trends from all users. |
| PayGo Leveraging Smart Meters to Help Customers Conserve Energy | ELB EC2 S3 | real time usage information , make payments for Utilities |
| Audio Live Streaming and Batch Processing Architecture | ALB, API server , Route53, ElasticCache Redis , CloudFront, RDS Aurora, S3, DocumentDB, NGINX Server , λ, Rekognition | live streaming and batch processing , Rekognition for content moderation |
| Digital Content Orchestration | S3 , StepFns, Meda Convert, λ, DynamoDB, Rekognition, Transcribe , Comprehend | Levels Beyond uses AWS Services to enable customers to quickly automate, package, and distribute digital content for orchestration. |
| Scalable realtime user monitoring system that serves 50K requests per minute, | CDN, ALB, Route53, EC2, SQS, Redis, Cassandra | how Zoho Site24x7 built a user monitoring system that serves up to 50K requests per minute. |
| high-performance DDOS and Edge Protection platform | CloudFront , Route53, ShieldAdvanced, WAF, ELB, EC2 , DataConnect , VPC peering, DynamoDB , λ , s3 Learn how William Hill built a high-performance DDOS and Edge Protection platform using AWS Services that has been effective in mitigating a 177 GBPS DDOS attacks and 48 million attempted exploits (in 2019) from across 121,000 IPs and 196 countries. In addition, the company successfully blocked 63 million requests from 180,000 IPs from 202 countries, all trying to scrape pricing and event data, which if successful, is highly detrimental to the business as well as to customer experience. | |
| Infor - Ingest and Analyze Millions of Application Events Daily for Compliance Violations | S3 SQS , Kinesis, Fargate, EMR, EventBridge , Aurora | Infor modernized a single-tenant application deployed for individual customers into a multi-tenant scalable application capable of ingesting, storing, and analyzing millions of customer application events per day. |
| HaloDoc - Monolith to Microservices | EC2 , RDS , SNS λ , Kafka , Flink , Grafana, Kibana , Redshift, S3, Rekognition | evolved their monolithic back end into decoupled microservices with Amazon EC2 & SQS, adopted serverless to cost effectively support new user functionality with AWS Lambda, and manage the high volume and velocity of data with Amazon DynamoDB, RDS and Redshift. |
| processes 55TB of data per day | S3 SQS λ EMR Spark, Fanout, RDS | Nielsen Marketing Cloud processes 55TB of data per day while maintaining quality, performance, and cost using a fully automated serverless pipeline. |
| scalable, elastic platform | S3 SNS λ | HSBC is building a scalable, elastic platform while maintaining bank-grade security. |
| highly elastic solution combined with low maintenance and running costs | APIG , ELB, Fargate , RDS , Kinesis , λ , DynamoDB | how Temenos used AWS managed services like DynamoDB and Fargate with serverless technology to build their T24 Transact banking system, and achieve a highly elastic solution combined with low maintenance and running costs. |
| Using Chime SDK to Power Coach-led Virtual Workouts with OTlive | S3 SNS λ | how they built a global, scalable virtual workout classes system using native AWS services. You will learn how the Amazon Chime SDK is used to stream real-time video between coach and participants. How Chime SDK’s websockets are used to send heart rate telemetry in real time from the members to the coach. Finally, you will learn how the second by second heart rate telemetry is streamed to Firehose for later processing in OTF’s data lake. |
| S3 SNS λ |

- virtual classes for fitness centres
- Member -> Cognito (authenticate) -> APIG -> λ -> Aurora (retrieve class details)
- Coach -> Cognito (authenticate) -> APIG -> λ -> Aurora (retrieve class details)
- Member -> ChimeSDK (Video streaming / connection) -> Coach
- Member -> websockets of ChimeSDK (low latency / edge) -> check Heart rate -> Coach
- Data (Hear trate etc) -> Kinesis -> S3 / Data Lake

- Elastic Scalability - Unpredictable loads -> burst out and scale back down
- Clients -> APIG -> Endpoints routed to -> ELB (route to the correct container)-> Fargate (host containers)-> persist the data into RDS
- Events from RDS pused to -> Kinesis -> λ ( provide optimised data model) -> DynamoDB
- Why 2 DBs - RDS ( database schema for SQL queries and only optimized queries sent to DynamoDB )
- Maintainance and Manageability -
- APIG -> query workload to λ -> DynamoDB
- Cloud Formation scripts to spin up predefined architecture

- Scaling issues (Using Direct connect from on prem to Bank)- VPC endpoint (λ)-> Proxies -> DC -> Bank
- deploy workloads in and out of the bank
- create VPC's as needed
- Proxies controled by security (whitelist domains) , λ -> VPC endpoint -> Internet gateway -> extrenal (e.g push notifications)
- Terraform / SAM templates for deployments - configure network/ CIDR blocks , build infra , deploy code on infra

- 250 billion events / day
- event Files -> S3 bucket -> EMR Spark (processed) -> S3 -> λ (Processing and spitting it / uploads)
- Files (metadata) -> SQS -> λ -> RDS -> λ -> Spark
- RDS -> workmanager λ -> Fanout to many λs -> upload to networks
- λ -> SQS (processed / retried)
- Scale
- Rate Limiting per network - killing external servers , partner servers needed rate limiting
- Cost -> Making λs more efficient , memory footprint to optimize, number of hhtp connections sent


- EC2 with RDS for each microservice
- Data Partitioning - DynamoDB to save all data , having a low latency DB
- To remove tight coupling between microservices - SNS
- Serverless - Doctor - elecrtronic prescription(Consulation service would raise an event and that will trigger a λ
- Realtime visbility of data - each microservice would raise an event to SNS which triggers λs , enriched data sent to Kafka ,flink , elastic search -> Grafana dashboards
- Transactional Data [Scalable warehouse]- RDS -> DMS -> Redshift ( run queries) , old data goes to Glacier for record keeping
- Streaming - Kafka ->Elastic search(persistent layer)-> Kibana / Grafana (Dashboards)
- Image repo -> image uploaded to s3 -> rekognition (unsafe images)

- Ingestion Flow = Applications generate security and data -> Kinesis Strem -> service on Fargate , parses the data -> Aurora DB and S3 buckets (scheduled glue jobs that do ETL)
- Scheduled Events (managed by cx) that trigger analysis -> Analysis Engine runs on Fargate -> Trigger EMR jon on Spark engine (retrieves data from aurora and S3) -> violations sent to EventBridge -> SQS message -> Fargate (decorate violations and send emails to cx on smtp.
- Transient and long running jobs on EMR cluster

- Reasoning - In 2016 major DDOS attack , largest botnet at peak 177 GB/sec
- CloudFront -> ShieldAdvanced (mitifate layer 3 and 4 DDOS attempts) and low complexity layer 7
- For more higher complexity layer 7 - use WAF
- CloudFront -> Route53 ( two hosted zones) -> traffic to ELB (nonsensitive traffic) , traffic to EC2 that hosts F5 big IP (sensitive traffic) [extra layer of protection]
- VPC -> VPC peering (that has 7 different channel accounts where appln sits) -> VPC *

- Users -> Route53 -> CDN -> (downloads the beacon script on the browser - which collects user metrics)
- Users -> Route53 -> ALB -> Collectors (Group of EC2 instances that are auto scaled) -> push the data to SQS
- Processors(Group of EC2 instances that are auto scaled) -> susbcribe to SQS and fectches info and process data / calculation -> Cache (Redis) -> store DB casandra cluster (across AZ for high availability)
- Dashboard (API requests)-> ALB -> Processors
- Enhancements -> Geo based routing , Replace EC2 collectors to λ, maintaining and automating deployments across reigons using code deploy
- EC2, ELB -> Direct connect -> ON-Prem
- logs of traffic from CloudFront -> S3 -> logs to Onprem analysis servers -> analysed ips sent to DyanamoDB, λ runs inspects the table for new / expired entries -> updates WAF filters

- User -> Upload File to S3 -> Triggers Step Fn -> Media Convert (creates a proxy for playing back and browser) , trigger λ extract metadata and stored in DynamoDB, trigger Rekognition for validating data profiles (eg nudity) stored in DynamoDB, trigger Transcribe (take audio from content and translate to text) -> sent to Comprehend again stored in DynamoDB.
- Ingest into Reach Engine (EC2, EKS)- ( allow users to replay content , view metadata, search metadata, visualization of data from Rkognition)

- DJ's open live room witgh ALB and API Server - which reuests a chat room server and the live streaming server through the streaming server.
- All data stored in RDS aurora at the same time stored in DocumentDB
- Listeners listen through API server

- Visit the utility website through ELB -> Data in EC2 -> Utility Company -> communicates to smart meter
- Barcode on Mobile or Paper utilty bill -> Particiapting retailer -> Evaluate Business rules -> Payment goes to EC2 -> Utility Company -> communicates to smart meter
- Persist data through EC2 instead of RDS , reason - features that RDS did not support in the past therefore SQL server on Windows OS in EC2
- High Availability and DR - Stack redundant on different AZ, DR - > backing data onto S3 and cross reigon replicated
- Next steps -> SQL server to RDS , Infrastructure automation and orchestration - for building environemnets
- Gunosy is a news curation application that covers a wide range of topics, such as entertainment, sports, politics, and gourmet news. The application has been installed more than 20 million times. Gunosy aims to provide people with the content they want without the stress of dealing with a large influx of information. We analyze user attributes, such as gender and age, and past activity logs like click-through rate (CTR). We combine this information with article attributes to provide trending, personalized news articles to users.
-
Users need fresh and personalized news. There are two constraints to consider when delivering appropriate articles:
-
Time: Articles have freshness—that is, they lose value over time. New articles need to reach users as soon as possible.
-
Frequency (volume): Only a limited number of articles can be shown. It’s unreasonable to display all articles in the application, and users can’t read all of them anyway.
-
We optimize the delivery of articles with these two steps.
-
Personalization: Deliver articles based on each user’s attributes, past activity logs, and feature values of each article—to account for each user’s interests.
-
Trends analysis/identification: Optimize delivering articles using recent (real-time) user activity logs—to incorporate the latest trends from all users.
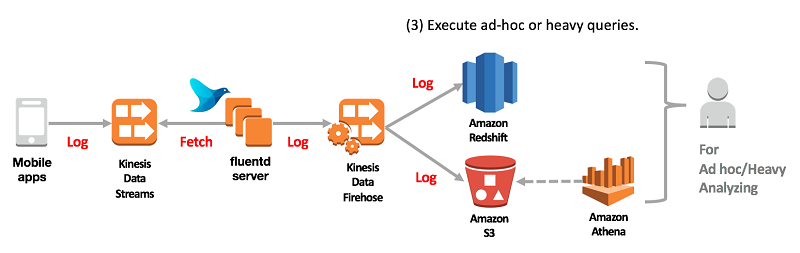
- The following diagrams depict the architecture for optimizing article delivery by processing real-time user activity logs
- There are three processing flows:
- Process real-time user activity logs.
- Store and process all user-based and article-based logs.
- Execute ad hoc or heavy queries.

- Brisk Voyage finds cheap, last-minute weekend trips for our members. The basic idea is that we continuously check a bunch of flight and hotel prices, and when we find a trip that’s a low-priced outlier, we send an email with booking instructions.
- We use SQS to serve a queue of URLs to crawl. Google Flights URLs look like this: https://www.google.com/flights?hl=en#flt=BOS.JFK,LGA,EWR.2020-11-13*JFK,LGA,EWR.BOS.2020-11-16;c:USD;e:1;sd:1;t:f.
- The three-letter codes in the URL above are IATA airport codes. If you click that link, notice how there are multiple destination airports. This is one key to efficient Google Flights scraping!
- A single SQS queue stores all Google Flights URLs that need to be crawled. When the crawler runs, it will pick off a message from the queue. Order is not important, so a standard queue (not a FIFO) is used.
- Lambda is where the crawler actually runs. We use Chalice, which is an excellent Lambda microframework for Python, to deploy functions to Lambda.
- Although Serverless is the most popular Lambda framework, it is written in NodeJS. This is a turn-off for us given that we’re most familiar with Python, and want to keep our stack uniform. We’ve been very happy with Chalice — it’s as simple as Flask to use, and it allows the entire Brisk Voyage backend to be Python on Lambda.
- The crawler consists of two Lambda functions:
- The primary Lambda function ingests messages from the SQS queue, crawls Google Flights, and stores the output. When this function runs, it launches a Chrome browser on the Lambda instance and crawls the page.
- The second Lambda function triggers multiple instances of the first function. This runs as many crawlers as we need in parallel. This function is defined to run at two minutes past the hour during UTC hours 15–22 every day.
- An alternative would be to use the SQS queue as an event source for the crawl function, so that when the queue populates, the crawlers automatically scale up. We originally used this approach.
- There is one big drawback, however: the maximum number of messages that can be ingested by one invocation (batch size) is 10, meaning that the function has to be freshly invoked for every group of 10 messages.
- This not only causes compute inefficiency, but increases bandwidth drastically as the browser cache is destroyed every time the function restarts. There are ways around this, but in our experience, they have lead lots of extra complexity.
- Lambda costs $0.00001667/GB/second, while many EC2 instances cost one-sixth of that. We currently pay around $50/month for Lambda, so this would mean we could substantially reduce these costs.
- Lambda, however, has two big benefits: first, it scales up and down instantly with zero effort on our part, meaning we are not ever paying for an idling server.
- Second, it’s what the rest of our stack is built on. Less technology means less cognitive overhead. If the number of pages we crawl ramps up, it will make sense to reconsidering EC2 or a similar compute service. At this point, I think an extra $40 per month ($50 on Lambda vs ~$10 on EC2) is worth the simplicity for us.
-
Pyppeteer is a Python library for interacting with Puppeteer, a headless Chrome API. Since Google Flights requires Javascript to load prices, it is necessary to actually render the full page. Each of the 50 crawl functions launches its own copy of a headless Chrome browser, which is controlled with Pyppeteer.
-
The crawl function reads a URL from the SQS queue, then Pyppeteer tells Chrome to navigate to that page behind a rotating residential proxy from PacketStream. The residential proxy is necessary to prevent Google from blocking the IP Lambda makes requests from.
-
Once the prices are extracted, we delete the SQS message, and re-queue any origin/destinations that weren’t displayed within the flight results. We then move onto the next page
- a new URL is pulled from the queue, and the process repeats. After the first page crawled in each crawl instance, pages require much less bandwidth to load (~100kb instead of 3 MB) due to Chrome’s caching.
- This means that we want to keep the instance alive as long as possible, and crawl as many trips as we can in order to preserve the cache. Because it’s advantageous to persist functions to retain the cache, crawl‘s timeout is 15 minutes, which is the maximum that AWS currently allows.
- After it’s extracted from the page, we have to store the flight data. We chose DynamoDB for this because it has on-demand scaling. This was important for us, as we were uncertain about what kinds of loads we would need. It’s also cheap, and 25GB comes free under AWS’s Free Tier.
- DynamoDB has taken some work to get right. Normally, tables can only have one primary index with one sort key.
- Adding secondary indices is possible, but is either limited or requires additional provisioning, which increases costs.
- Due to this limitation on indices, DynamoDB works best when the usage is fully thought-out beforehand. It took us a couple tries to get the table design right. In retrospect, DynamoDB is a little inflexible for the kind of product we’re building. Now that Aurora Serverless offers PostgreSQL, it may be wise for us to switch to that at some point.
- We use Dashbird for monitoring the crawler and everything else that’s run under Lambda. Good monitoring is a requirement for scraping applications because page structure changes are a constant danger. At any time (even multiple times per day, as we’ve seen with Google Flights recently) the page structure can change, which breaks the crawler. We need to be alerted when this occurs. We have two separate mechanisms to track this:
- A Dashbird alert that emails us when there is a crawl failure.
- A GitHub Action that runs every 3 hours that runs a test crawl and verifies the results make sense. Since that crawler isn’t always running, this alerts us when Google Flights changes their page structure outside of operating hours. This way, the crawler can be fixed prior to starting for the day.
-
Cross-device development is a huge concern when it comes to application development. Facilitating this comes at a high cost and manual tasks which hinders the efficiency of development teams.
-
However, with AWS Lambda you can solve and automate this problem by developing a multi-platform media and content delivery pipeline.
-
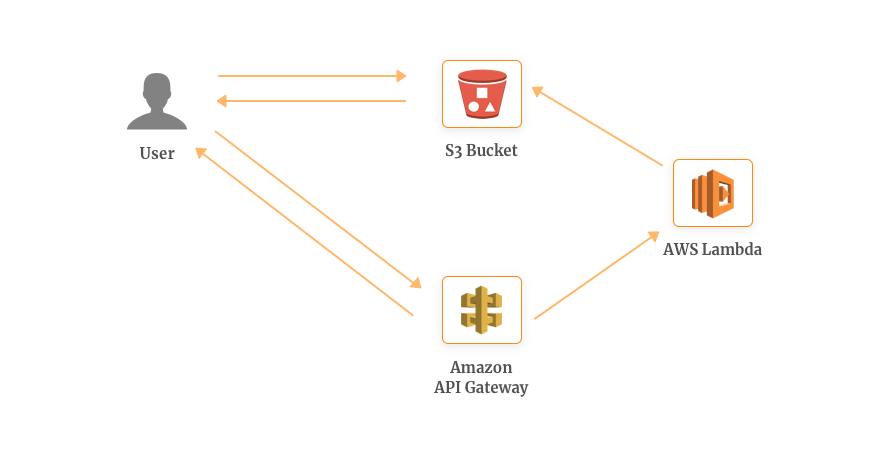
For example, whenever a user requests for an image which isn’t available in the Amazon S3 bucket, the user’s browser follows the redirect and request the image resize through AWS API Gateway.
-
This triggers the Lambda function which fetches the original image from the S3 bucket, resizes it and uploads it back along with the corresponding requested key.
-
The best example is Netflix with its 70 billion hours of content in a quarter to nearly 60 million customer uses AWS Lambda examples of media transform to facilitate their media files in more than 50 formats.
-
They are also leveraging it to build a self-sufficient automated infrastructure to replace inefficient processes to reduce the error rates and valuable time.
- When you’re redesigning your website or app, you don’t need to resize your entire image archive. Transformation on the go gives you high agility.
- With on-demand image resizing, you’re not required to store your archive in every possible format. Along with this, you can also delete the expired and older images.
- With Lambda, each request is initiated if the required image is not available. This means each request is not affected in any way with the previous failover.
-
Many times there comes a requirement when a single object is required in multiple formats. AWS Lambda along with S3 & SNS helps in building a general purpose event-driven system which processes the data in parallel.
-
To facilitate this, a pub-sub (SNS & Lambda) model is used to create a layer where data can be processed in the required format before sending it to the storage layer (S3).

-
In the above architecture, SNS works as a publisher of message delivery while AWS Lambda as a subscriber. Here, the event notification from the Amazon S3 goes to the Lambda functions which will process the multiple derivatives of the given data object.
-
The main part of our architecture is the “SNS topic”. It is notified when the object enters into the S3, transforms it into the message and distributes it to the subscribers (AWS Lambda). This architecture is not only fast (due to its serverless nature) but is scalable without much hassle of maintenance.
- Processing the data logs to produce multiple result derivatives which can be used for operations, marketing, sales, etc.
- Transforming the content from one format to another, for example, Microsoft Word to PDF.
- A master media file which needs to be converted into multiple formats.
- Processing data in real time and responding to them is highly imperative for modern business requirements. To enable this, analyzing the metrics data in real time is critical. But Amazon Kinesis Stream and AWS Lambda have made it possible!

-
Create a Kinesis Stream and configure it to capture data from your website. Kinesis facilitates the data volume processing on 1 shard: 1 function basis to limit the parallelism as soon as you hit a certain data limit per shard. The number of Lambda function instances scales automatically as the stream is scaled.
-
Once your application writes the records to the stream, AWS Lambda polls the stream from the shard and process them whenever a new record is found.
-
For example, you can have your Lambda function polling the Kinesis stream 5 times a second on a per shard basis. That means one Lambda function is invoked every 200ms per shard.
- Website clickstream
- Payment transactions
- Social Media timeline
- IT logs
- Location-based tracking
-
Stream-based model (event source mapping) where you map out your data sources across your app/website. These sources write data to the stream and whenever a new record is found, a Lambda function is invoked to execute your custom logic.
-
Synchronous invocation model where you invoke your Lambda function manually using RequestResponse invocation type (synchronous invocation by manually monitoring the Kinesis stream.
-
Event structure model where your Lambda function receives data as a collection of records to process. The batch size of these records needs to be specified at the time of event source mapping.
-
For example, there are thousands of IoT devices sending data logs. In some cases, you need to execute an operation when a condition is matched, Lambda & Kinesis works best for you! Also, check out how Dubsmash used Kinesis + Lambda while they were scaling for 200 million users.
-
Bustle processes high volume of site metric data in real time. This allows them to capture more data quickly. Which in turn helps them in analyzing how new features are affecting the website audience. Not only that, they have been able to monitor user engagement which has empowered marketing to make decisions driven by data.
-
We have often come across complex applications (e-commerce, analytics software, ERP, etc) which consists of complex repeatable scenarios that need to be executed in a response to some event. In other words, workflows.
-
Earlier, it was not possible to include Lambdas in such workflows. Coordinating these functions, chaining them and checking conditions for deciding what to do was a responsibility of a developer.
-
However, with Step Functions, coordinating AWS Lambda is possible. These functions will be short, easy to test and will accommodate a single responsibility.
-
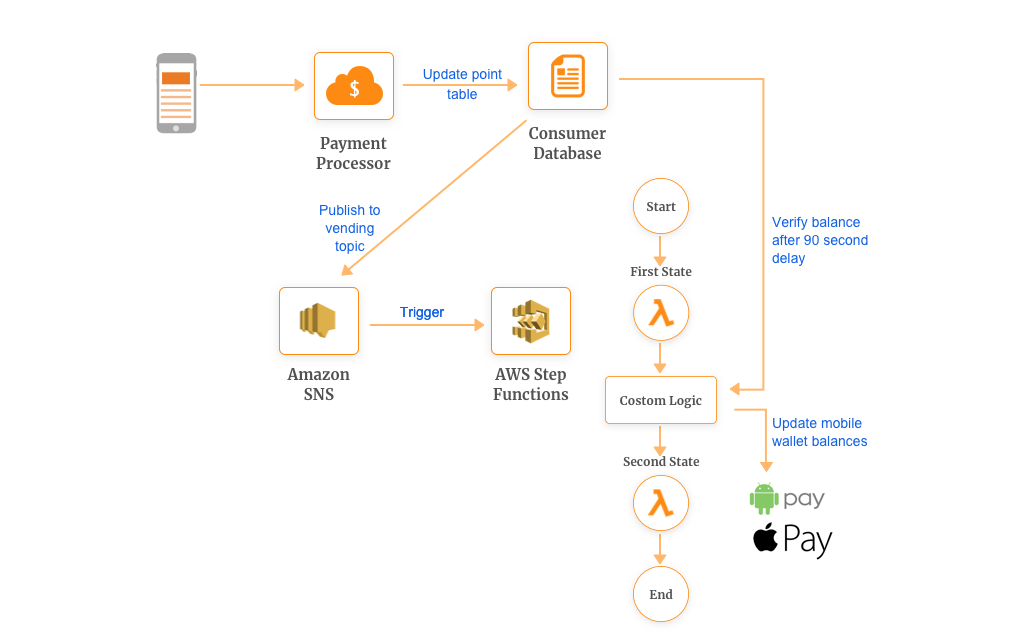
As shown in the image, you can apply custom logic before you invoke your subsequent functions, for example, delay of 10 seconds. Some of the potential scenarios where you can use Step Functions and Lambda are:
- Customer onboarding
- Shopping Cart Management
- Drip Marketing
- Loyalty programmes
-
For Coke Vending Pass Program, developers used a combination of SNS and Lambda. But eventually, it was slow to react and prolonged timing dependencies. This lead to confusing updates to the vending machine. As a potential solution, 90 seconds of time delay would work fine and hence they added a delay to the first Lambda function.
-
As you might have guessed it, this increased the execution time of the function which resulted in an increased bill. In order to make this solution more cost-effective, they turned to Step Functions to coordinate their components of microservice at scale.
-
Similarly, FoodPanda, the popular food delivery giant uses Step Functions along with AWS Lambda to improve their food delivery application workflow and continually improve their delivery times.
-
Here’s another interesting example by Alex Casalboni where he developed a state machine which estimates the best power configuration to minimize the cost for any given Lambda function.
-
Many times it is required to analyze and keep track of the changes made in the database. Or maybe you want to process data before it is stored in the database. With AWS Lambda & DynamoDB Streams this is possible.
-
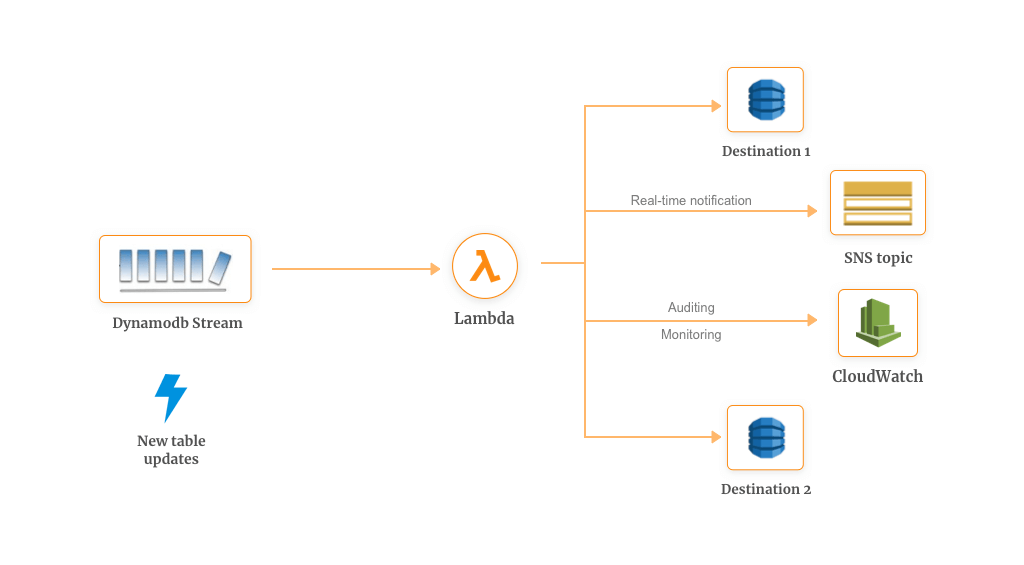
Amazon DynamoDB, when integrated with AWS Lambda, can help you trigger a piece of code that automatically responds to the events in the DynamoDB Streams. These triggers can help you build an application that reacts to the data modification in DynamoDB tables.
-
Once you enable DynamoDB Streams for your database, it keeps records of changes such as puts, updates & deletes. Whenever an item is modified in the table, a new record has appeared in the DynamoDB Stream. AWS Lambda polls the stream and executes your function which can be used for custom requirements.
-
DynamoDB streams with AWS Lambda can also be used for enabling multiple workflows. Some of them are:
- Cross Region Replication
- Filtering
- Monitoring
- Auditing
- Notifications
-
For example, cross-region replication is highly useful when you want to run real-time applications in parallel. Mapbox serves maps to almost 100 million unique users every month across the world. To reduce the speed at which the maps are delivered and rendered, they turned to cross-region replication using DynamoDB and AWS Lambda. More information can be found here.
-
Similarly, Netflix also uses AWS Lambda to update its offshore databases whenever new files are uploaded. This way, all their databases are kept updated.
-
Apart from this, you can also use AWS Lambda examples to create backups of the data from DynamoDB Stream on S3 which will capture every version of a document. This will help you recover from multiple types of failure quickly.
-
Another example, you can use AWS Lambda to notify SNS for multiple use cases. Suppose you want to send out an email whenever new books are added to the library.
-
For this, whenever new books are added to the database, an AWS Lambda function will trigger which will notify SNS. This, in turn, will send mass emails to the students.
-
Most of us are familiar with Alexa, popularized with Amazon’s multiple lines of Echo smart speakers and devices.
-
We are accustomed to using voice-enabled searches and interacting with voice assistants in-built in our smartphones.
-
One such AWS Lambda example is Alexa. This comes with a predefined set of functionalities (called skills) which are used for the voice interface. For voice interaction, Alexa processes the natural language into a programmatic action.
-
For example, you can create a straightforward and basic functionality which will call a Lambda function in response to the given voice command.
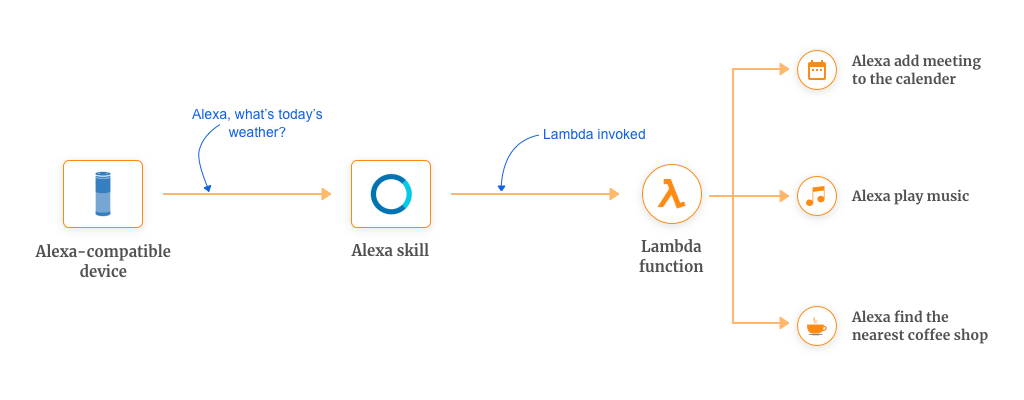
-
Custom Alexa Skill Set: This is an object embedded inside AWS Console which invokes your handler function in response to the voice command from the Alexa enabled devices.
-
Alexa Skill Handler Function: This is an AWS Lambda function which provides us with the custom logic that we want our command to execute. This handles the task of fulfilling the user’s request.
-
Third Party Functions: These functions are hosted outside of the Alexa skill. These provide us with the functionality of interfacing with the 3rd party services like interacting with a Database, call to a 3rd party services, etc.
-
Some of the Alexa skills that you can write for yourself are:
-
Adding a meeting to the calendar
-
Finding out the nearest coffee shop
-
Create a reminder
-
Playing the music
-
Need some more inspiration? Check out this list of 50 most useful Alexa Skills.
-
To derive multiple formats of data, sometimes users need to do compute work. This compute work is based on the data which is being inserted, updated or deleted to the database. However, oftentimes they do not want the compute work to be done on the compute resources but on the database itself.
-
Amazon Aurora MySQL has the ability to invoke Lambda as a “storage/stored procedure”. This functionality triggers the function before/after some operations of interest are performed on the particular database table.
-
This ability of Lambda has reinvented the old methods of stored procedures to new methods which are higher and greater in the velocity.
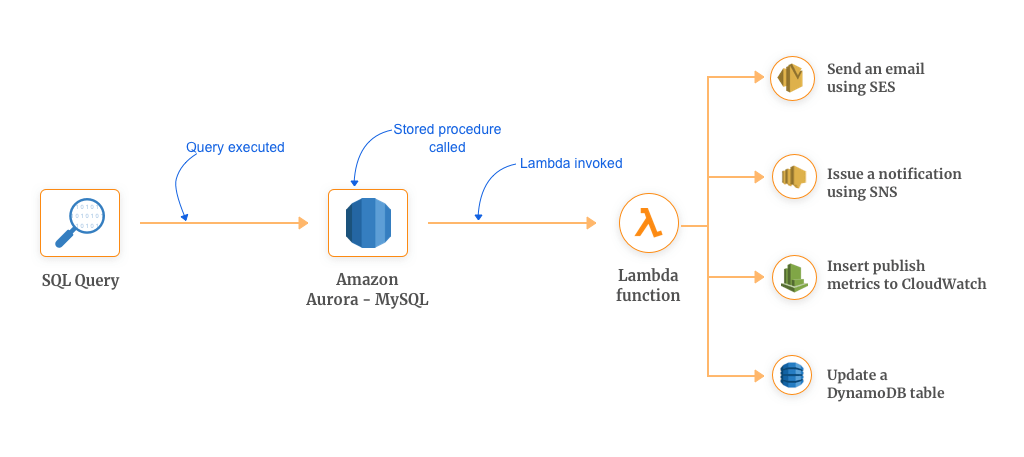
- This could be very useful for databases having high velocities or high traffic where traditional stored procedures have become a pain point in terms of consuming CPU resources from the other capabilities of the database. You can take this use case to invoke Lambda for whatever your requirements be.
This mechanism helps you wire other services of AWS with your Aurora database. Here are some of the things you can do:
- Send an email using SES
- Issue a notification using SNS
- Insert publish metrics to CloudWatch
- Update a DynamoDB table
-
Implement complex ETL & workflows
-
Track & audit actions on database tables
-
Perform advance performance monitoring & analysis
-
Combining AWS Lambda example with Amazon RedShift (Data Warehouse)
-
Amazon RedShift has the number of different ways for which it creates events along with AWS Lambda, for example, when you want to create replicas, do snapshots, backups or create an event to which SNS topic is subscribed to.
-
This SNS topic subsequently invokes Lambda which can be useful for things like:
- Single region multiple copies
- Creating multiple copies of redshift clusters
- Responding to failures/incidents
- Number of automotive capabilities
-
Imagine you have a website where people can upload images. As soon as the images are uploaded, you want the images to go through a set of workflow actions.
-
For example, a workflow where a user uploads an image which is stored in the S3 bucket triggers a Lambda function 1. This function invokes the state function workflow, as shown in the image.

-
This step function workflow orchestrates the job of multiple Lambda functions. The first thing it does it to extract the metadata from the image, for example, image type information. Meanwhile, another three lambda functions are invoked in parallel.
-
Lambda function 2 is invoked to extract the image metadata
-
Lambda function 3 invokes the Rekognition which finds out the object in the image
-
Lambda function 4 is invoked to generate an image thumbnail
-
Lambda function 5 writes all this information back into the DynamoDB
-
End result: Whenever the page refreshes after the user has uploaded the image, they see all the metadata, thumbnail and the object tagged that are evident in the image. This is an example of an image processing pattern and can extend it as per your custom requirements.
-
NatGeo Example: As they were moving towards a larger platform, they found out that they have a lot of metadata about the text content but the images didn’t really have a lot of metadata and that was affecting how they were surfacing content which isn’t tied to the text.
-
This was important since they were trying to showcase images and videos and not just magazines articles.
-
Using AWS Lambda example and Rekognition helped them in two ways:
-
Personalizing not just the content but images as well
-
Cropping mechanism where the system identifies the focal point and crops automatically
-
With the advent of AI enabled devices, text-to-speech has become imperative for modern applications. Medium being the latest one in facilitating TTS functionality. More to that, speech synthesis is a tricky subject and the list of interpretation challenges is endless.
-
With AWS Lambda & Amazon Polly, you can harness the power of lifelike speech synthesis application. Amazon Polly uses advance deep learning technologies to synthesize speech that resembles the human voice.
-
AWS Lambda here enables Polly to work with faster response times which is critical for real-time and interactive dialogue.
-
Here’s an application architecture of our sample application which converts a text module into an MP3 file. To run the application asynchronously, SNS is used to receive information and convert the files simultaneously.
-
This uses two methods where AWS Lambda along with API Gateway as a RESTful web service:
-
Lambda 1: Initially for sending out the notification about a new post which is to be converted into an MP3 file.
-
Lambda 2: For retrieving information about the post which includes a URL of the MP3 file stored in the S3 bucket.
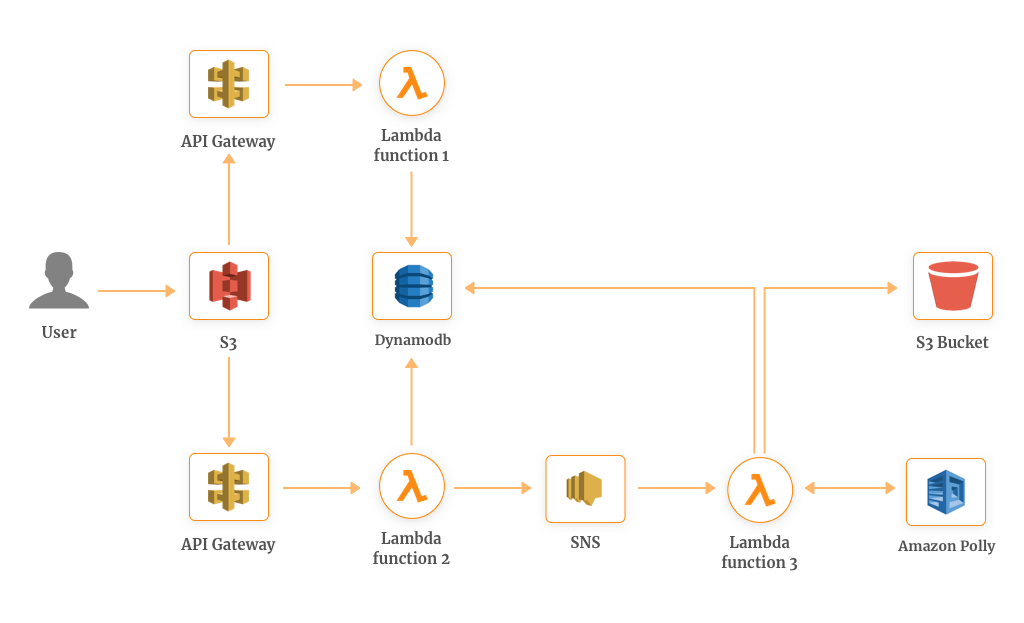
- Whenever a new post is added to the S3 bucket, a dedicated API Gateway triggers a Lambda function 1 which initializes the process of MP3 file generation.
- Lambda function 1 stores the copy of the information in DynamoDB where information about all posts is stored.
- Meanwhile, Lambda function 1 is publishing a message to SNS which trigger Lambda function 2. This function along with Amazon Polly converts the text into the audio in the same language as the text.
- After that, an MP3 file is stored in the S3 bucket with the reference URL and the information about the same will be stored in the DynamoDB.
-
Today most of the application facilitates the personalized content and news feed. This is possible because the personalized user experience is becoming an inevitable feature and accessing & monitoring of user touch points is becoming easy.
-
However, setting up and managing a complex architecture isn’t a requirement. AWS Lambda has made it possible to get started easily with a personalized content platform with the possibility to make changes on the go. Let’s take an example of our reference architecture.
-
Here all the information extracted from users touch points is stored in the DynamoDB. With the help of Lambda function processed in the backend, it creates the user’s profile and a custom feed based upon various parameters.
-
This personalised feed aggregates the content from multiple places

- Aggregate the content, normalize it and then prepares it for the delivery. Lambda function 1 is used to communicate with Rekognition where it classifies the image, gives the proper meta tags, resizes it according to the device and so on.

-
This second part which facilitates the content personalization is mostly powered by the API Gateway and Lambda functions.
-
Content API: The primary source of the feed is CloudSearch where the aggregated content is stored for the Content API to communicate.
-
User API: This keeps track of what users are browsing in the application, monitors their activity with respect to time.
-
Read/Write API: This is mostly pushing back and forth the data gathered into the DynamoDB
-
Admin API: This is for the editors to manage things manually from the backend, for example, change the tagging, turn off if it’s unsuitable for the students, etc.
- The AWS services frequently used to analyze large volumes of data are Amazon EMR and Amazon Athena.
- For ingesting and processing stream or real-time data, AWS services like Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, Amazon Kinesis Data Analytics,Spark Streaming and Spark SQL on top of an Amazon EMR cluster are widely used.
- Amazon Simple Storage Service (Amazon S3) forms the backbone of such architectures providing the persistent object storage layer for the AWS compute service.
- Lambda architecture is an approach that mixes both batch and stream (real-time) dataprocessing and makes the combined data available for downstream analysis or viewing via a serving layer. It is divided into three layers: the batch layer, serving layer, and speed layer.

-
Each of the layers in the Lambda architecture can be built using various analytics, streaming, and storage services available on the AWS platform.
- The batch layer consists of the landing Amazon S3 bucket for storing all of the data (e.g.,clickstream, server, device logs, and so on) that is dispatched from one or more data sources.
- The raw data in the landing bucket can be extracted and transformed into a batch view for analytics using AWS Glue, a fully managed ETL service on the AWS platform.
- Data analysis is performed using services like Amazon Athena, an interactive query service, or managedcHadoop framework using Amazon EMR.
- Using Amazon QuickSight, customers can also perform visualization and one-time analysis.

-
Finally, the serving layer can be implemented with Spark SQL on Amazon EMR to process the data in Amazon S3 bucket from the batch layer, and Spark Streaming on an Amazon EMR cluster, which consumes data directly from Amazon Kinesis streams to create a view of the entire dataset which can be aggregated, merged or joined.
-
The merged data set can be written to Amazon S3 for further visualization.
-
The metadata (e.g., table definition and schema) associated with the processed data is stored in the AWS Glue catalog to make the data in the batch view immediately available for queries by downstream analytics services in the batch layer.
-
Customer can use a Hadoop based stream processing application for analytics, such as Spark Streaming on Amazon EMR.
- How to convert an openly available dataset called MIMIC-III, which consists of de-identified medical data for about 40,000 patients, into an open source data model known as the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM).
- It describes the architecture and steps for analyzing data across various disconnected sources of health datasets so you can start applying Big Data methods to health research.
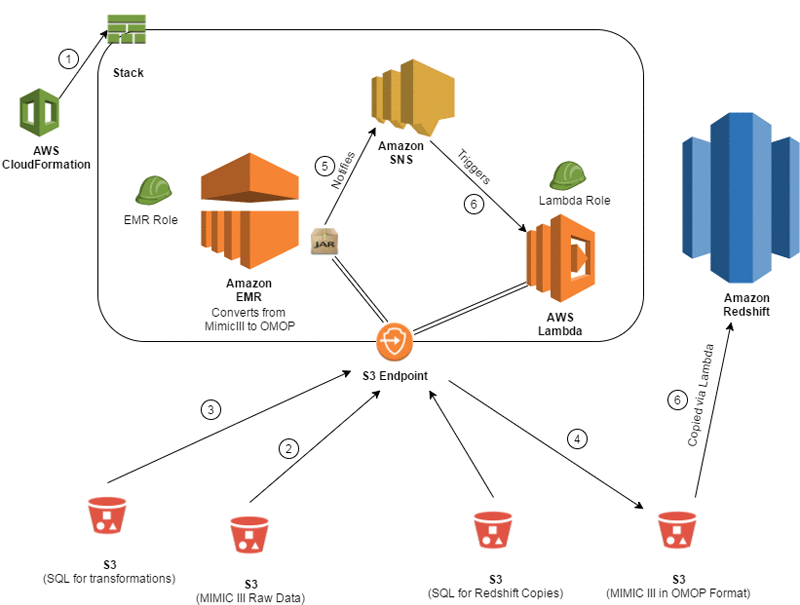
- The data conversion process includes the following steps:
- The entire infrastructure is spun up using an AWS CloudFormation template. This includes the Amazon EMR cluster, Amazon SNS topics/subscriptions, an AWS Lambda function and trigger, and AWS Identity and Access Management (IAM) roles.
- The MIMIC-III data is read in via an Apache Spark program that is running on Amazon EMR. The files are registered as tables in Spark so that they can be queried by Spark SQL.
- The transformation queries are located in a separate Amazon S3 location, which is read in by Spark and executed on the newly registered tables to convert the data into OMOP form.
- The data is then written to a staging S3 location, where it is ready to be copied into Amazon Redshift.
- As each file is loaded in OMOP form into S3, the Spark program sends a message to an SNS topic that signifies that the load completed successfully.
- After that message is pushed, it triggers a Lambda function that consumes the message and executes a COPY command from S3 into Amazon Redshift for the appropriate table.
-
The transformation code runs in a Spark container that can scale out based on how you define your EMR cluster. There are no single points of failure. As your data grows, your infrastructure can grow without requiring any changes to the underlying architecture.
-
If you add more data sources, such as EHRs and other research data, the high-level view of the ETL would look like the following:
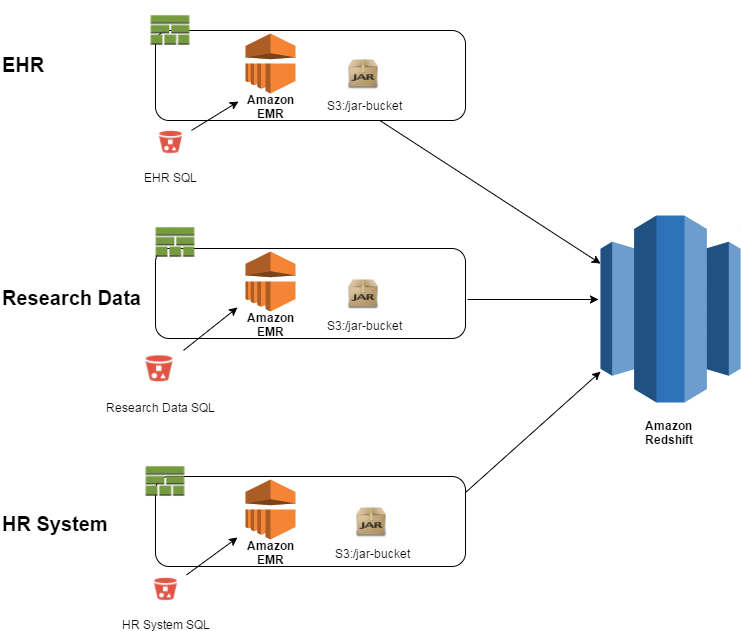
-
In this case, the loads of the different systems are completely independent. If the EHR load is four times the size that you expected and uses all the resources, it has no impact on the Research Data or HR System loads because they are in separate containers.
-
You can scale your EMR cluster based on the size of the data that you anticipate. For example, you can have a 50-node cluster in your container for loading EHR data and a 2-node cluster for loading the HR System. This design helps you scale the resources based on what you consume, as opposed to expensive infrastructure sitting idle.
-
The only code that is unique to each execution is any diffs between the CloudFormation templates (e.g., cluster size and SQL file locations) and the transformation SQL that resides in S3 buckets. The Spark jar that is executed as an EMR step is reused across all three executions.