
NACME (National Action Council For Minorities in Engineering) is an organization committed to assisting underrepresented minorities in engineering and computer science career paths. NACME provides scholarships, opportunities and programs in order to increase the engineering worforce and prepare underrepresented students for the real world. The AMLI Google Bootcamp is one of program that NACME provides that gives college students an introduction to machine learning in order to contend for an entry-level Machine Learning position.
Developed by:
- Brianna Murel - Morgan State University
- Jaden Robinson - Morgan State University
- Tobi Owolabi - Morgan State University
- Laila Amin - Morgan State University
Everyone
- Colab File Contributors : Create an empty colab and apply tactics like EDA (Exploratory Data Analysis), creating a DataFrame, training a model etc. The group is responsible for implementing and detailing code in order to complete the assigned topic for the project.
Brianna
- PowerPoint Creator : Manage presentation slides detailing the team members and roles, the reasons for completing the project, the lessons learned when completing the project and the steps moving forward after completing the project.
Tobi
-
Project Lead : Keep the group on task and oversee that everyone works on their assigned parts of the project. Maintains communication with the team and writes a project report as necessary.
-
Design Documenter : Frequently updates the design document on the necessary steps taken to complete the project. Write the intermediate and long term goals of the project.
Jaden
- Read.md file Creator : Creates the introductory file used to detail what is NACME/AMLI Google Bootcamp, gives a description of the topic for the project, list the names of the team members, their linked GitHub accounts and their associated University. They also provide the results for their respected projects.
Laila
- Ethical Considerations Editor : Write a discussion on the ethics of the project, write paragraphs on how a fictional character was positively and negatively affected by the project model, list possible biases and describe modifications to mitigate bias.
The premise of the project is to utilize a dataset of 20 News Groups and display the top 100 words by their frquencies(how often they appear). Then, natural language processing is applied to cluster documents in order to investigate the top 3 sets of topics contained in each cluster. Our goal is to conduct Unsupervised Learning by clustering our documents and examine the hidden words within our data. The words included in the documents are stripped by performing lemmatization (process from Natural Language Processing that accurately groups mutiple variations of the same word). Also, K-means clustering will be conducted to group the documents in the News Group by a number of clusters to and display the top 3 sets of topics(a.k.a. Topic Modeling).
- NLP is a means to where machines learn and interpret human language in the same manner as humans. Communication with the Iphone's Siri is an example of a use for nlp as when a user speaks into their device, Siri converts the speech to a machine's language and outputs information the user was looking for.

- process of converting words into their root word or lemma. In the example below, "play" is the lemma for all the variations of words. Lemmatization is used in this project to increase the accuracy of printing the top topics associated in each cluster.

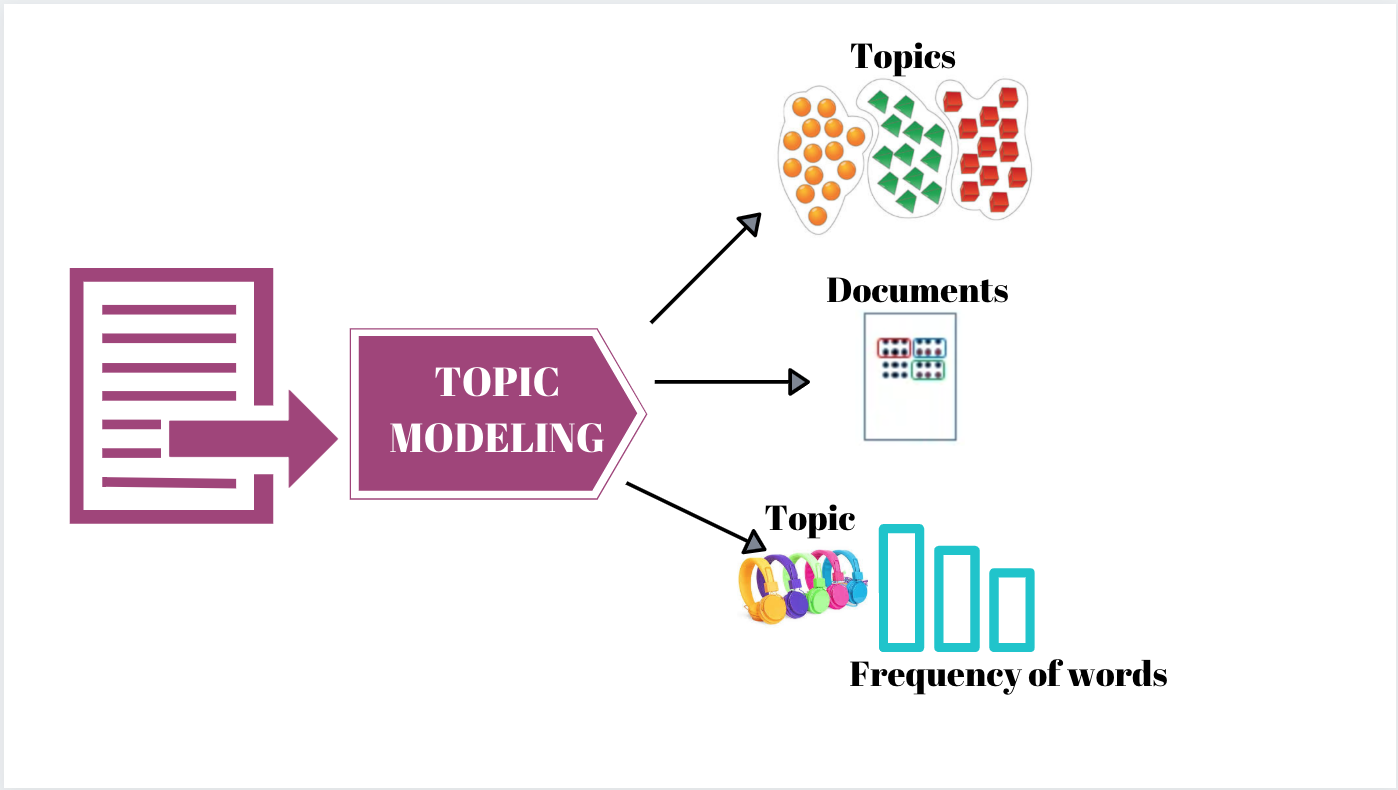
https://www.pinterest.com/pin/stemming-and-lemmatization-in-python--540713499008866837/ https://www.cybiant.com/resources/natural-language-processing/ https://medium.com/analytics-vidhya/how-to-perform-topic-modeling-using-mallet-abc43916560f
- Fork this repo
- Change directories into your project
- On the command line, type
pip3 install requirements.txt
- Tobi: [email protected]
- Jaden: [email protected]
- Brianna: [email protected]
- Laila: [email protected]