Confusion about the formula of content adversarial loss #56
Comments
|
Duplicate Issue: #17 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
|
Duplicate Issue: #17 |
In the original paper, the content adversarial loss is:
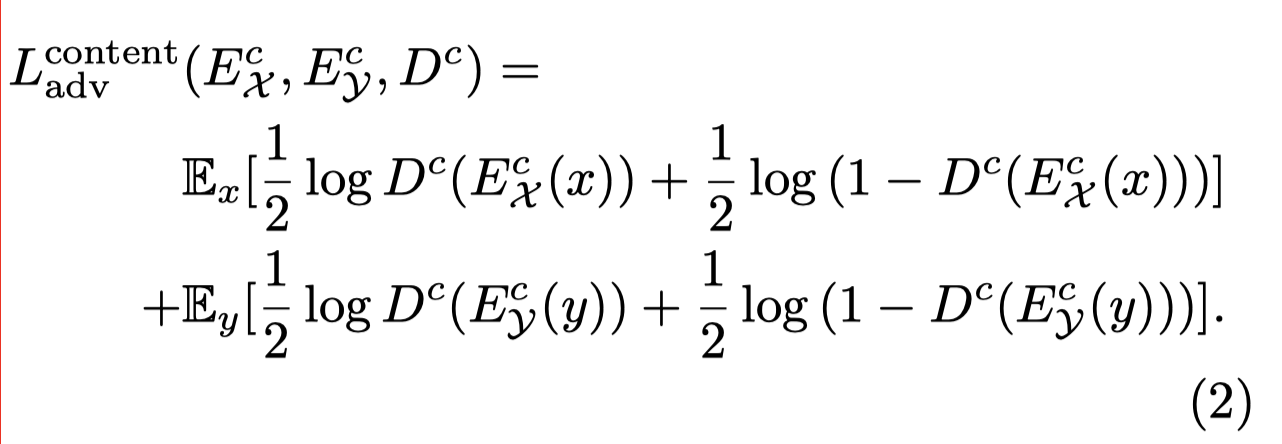
However, according to the code:
I think this formula should be written as:
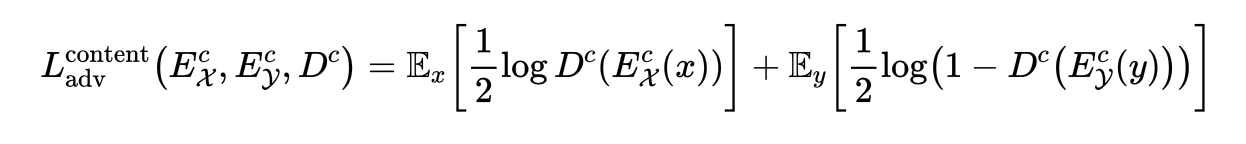
After all, the discriminator get optimal when it outputs 0.5 for all input in the situation of original formula
The text was updated successfully, but these errors were encountered: