Designing Data-Intensive Applications: 6. Partitioning #9
Comments
Capítulo 6 - ParticionamientoParticionamiento como dice su nombre se trata de poder partir los Datos en partes mas manejables, este concepto es común en todas las grandes BD, aunque su nombre sea diferente en cada BD (shards, regions, vbuckets, vnode). El propósito principal de partir los datos es poder escalar, ya que existe un limite físico de los discos, una BD particionada permite distribuir los datos en varios discos y en varias instancias de la BD, las solicitudes son distribuidas a los nodos o instancias de la BD que tiene los registros. Particionamiento y ReplicaciónPara tolerar fallos (ver replicación) copias de las particiones son almacenadas en diferentes nodos, esto significa que los nodos (replicas) pueden tener mas de una partición. Particionamiento por llave-valorEl objetivo es poder repartir los datos y las solicitudes de manera equitativa entre los nodos, si esto sucede en teoría, 10 nodos van a poder soportar 10 veces mas datos (y solicitudes - ver replicación).
Por rangos de llavesTal como los volúmenes de las enciclopedias (ej. Tomo1: A-ak — Bayes ... Tomo12: Trudeu - Zywiec ), los datos son particionados asignado un rango continuo de llaves a cada partición, puede que estos rangos no estén distribuidos de manera uniforme porque puede que los datos no estén distribuidos de manera uniforme; en el ejemplo de la enciclopedia el primer tomo tiene dos letras y el ultimo 7, asumiendo que los tomos son del mismo tamaño; estos limites para las particiones pueden ser escogidos por un administrador o por la BD misma, ademas las llaves son mantenidas en orden para facilitar las solicitudes, sin embargo esto mismo puede generar hot spots en el ejemplo de la enciclopedia es mas común acceder a ciertos tomos que otros debido a la frecuencia en que se usan ciertas palabras. Por hash de las llavesPara mitigar el riesgo de hot spots, muchas BD usan funciones hash[1] para determinar la partición de una determinada llave, una buena función hash distribuiría de forma uniforme una serie de llaves en un rango determinado incluso si tienen valores muy similares; una vez se tiene esta función, se usa para asignar las llaves a una partición el resultado de esta (hash) en vez de la llave, los limites de la partición entonces son uniformes o pueden ser escogidos de forma pseudoaleatoria (Hashing Consistente[2]); sin embargo usar Hashes tiene la característica que ya no se pueden hacer consultas por rango tan fácilmente, por ejemplo saber que palabra tienen la misma raíz etimológica (ej Bio....), para resolver esto algunas BD usan llaves primarias compuestas, donde solo una parte de la llave es procesada por la función Hash para determinar la partición y el resto se usa como un indice para poder ordenar. Aliviando Hot SpotsUsar llaves procesadas (hashed) reduce en gran parte los hot spots, pero no los elimina por completo, en el ejemplo de la enciclopedia, si esta es compartida en una biblioteca de la escuela y toda una clase necesita la misma definición, el tomo al que van a acceder es el mismo. Algunas BD agregan unos dígitos aleatorios extra a la llave al momento de guardar los datos para que esta sea repartida en varias particiones, sin embargo esto significa que las lecturas van a tener que compensar y leer de varias particiones, esta técnica solo tiene sentido si tienes algunas pocas llaves que son muy comunes. Particionamiento e Indices secundariosHasta ahora todo lo explicado tiene sentido si el acceso a los datos es por las llaves primarias, pero si se desea acceder por otras llaves no es tan sencillo, por ejemplo en la enciclopedia buscar todas las palabras que hacen referencia a una ciudad; este tipo de búsquedas son muy comunes en las bases de datos relacionales, y son el objetivo central de los servidores de búsqueda como Elasticsearch. Particionando Indices secundarios por documentoEn esta estrategia para usar indices secundarios, la BD, mantiene un indice local en cada partición que es creado al momento de agregar datos a esta, en el ejemplo de la búsqueda de ciudades en la enciclopedia, cada tomo tendría un listado de las ciudades de ese tomo, ahora para poder buscar todas las ciudades tendría que buscar ese indice en todos los tomos de la enciclopedia; este enfoque se llama dispersar y reunir (skatter/gather) y puede hacer que las consultas de lectura de indices secundarios sean muy costosas, incluso si se hace en paralelo puede causar problemas, sin embargo muchas BDs usan este enfoque (MongoDB, Riak, Cassandra, Elasticsearch, VoltDB). Particionando Indices secundarios por términosEn vez de usar un indice local se puede construir un indice global que cubre a todas las particiones, sin embargo tener este indice global podría convertirse en un hot spot si se deja en un solo nodo por lo que debe también particionarse; esto se llama particionado por termino, porque es el termino el que determina la partición a donde va, tiene la ventaja que las lecturas son mucho mas eficientes, ya que el cliente lee directo de las particiones que necesita, pero tiene que compensar por esto distribuyendo la creación del indice en la escritura por lo que los indices no siempre están disponibles inmediatamente justo después de una escritura ya en la practica su creación es asíncrona. Rebalanceando ParticionesUna base de datos usualmente cambia con el tiempo a diferencia de una enciclopedia[3] los datos son modificados, hay fallos en las maquinas, o cambian los requerimientos de uso, esto requiere mover datos de un nodo para otro, este proceso se llama rebalanceo. Sin importar el esquema de particionado, después de rebalancear se debe:
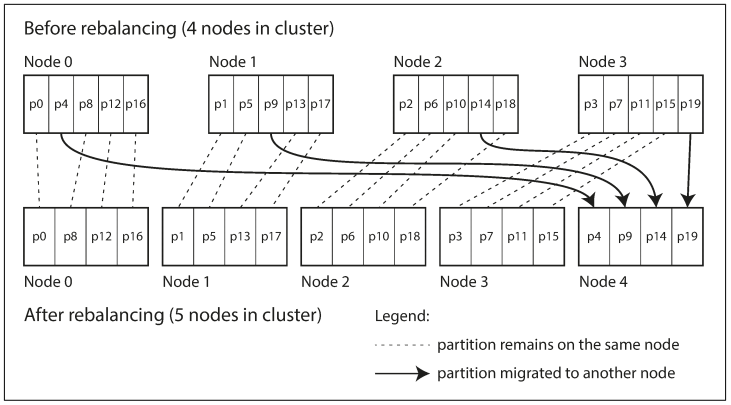
Estrategias de RebalanceoComo no hacerlo: cuando se particiona por el hash de una llave se dividen los posibles resultados (hashes) en rangos y a cada rango se le asigna un particion Numero fijo de particiones: Hay una solución sencilla para rebalancear tener muchas mas particiones que nodos, y asignar muchas particiones a cada nodo, cuando un nuevo nodo es agregado, de cada uno de los existentes nodos se traspasan particiones enteras al nuevo nodo:
En esta estrategia el numero de particiones es fija para facilitar esta operación, el numero de particiones tiene que ser el "adecuado", el mínimo numero es el posible numero de nodos (una partición por nodo), sin embargo si las particiones son muy grandes (pocas particiones) los procesos de rebalanceo y recuperación son muy costosos, si por el contrario son muchas particiones, esto genera muchos costos de administración. Particionado dinámico: Cuando las BD usan particionado por rangos de llaves un numero fijo de particiones no es lo mejor, imaginemos a nuestra enciclopedia de 10 tomos a la que le vamos agregando nuevas palabras, es probable que terminemos con tomos mas llenos que otros, por este motivo algunas BD reconfiguran el numero de particiones asignando un tamaño fijo a estas, si se "llenan" se convierte en dos particiones cada una con mas o menos la mitad de los datos de la original, una vez estas nuevas particiones son creadas pueden asignarse a un nuevo nodo para balancear la carga; sin embargo esto tiene una desventaja cuando no hay suficientes datos para llenar una partición todas las solicitudes van a un solo nodo, para mitigar esto algunas BD previenen configurar un numero fijo inicial de particiones (pre-splitting). Particionado proporcional a los nodos: Otra opción es tener el numero de particiones proporcional al numero de nodos, es decir, cuantas particiones va a soportar cada nodo, en este caso el tamaño de cada partición crece proporcional a los datos mientras que el numero de nodos no cambia, cuando se agregan nuevos nodos las particiones reducen su tamaño al dividirse y el nuevo nodo toma una de las partes de esas divisiones, esto hace que el nuevo nodo reciba una buena parte de la carga. Operaciones: Rebalanceo Automático o ManualEnrutado de solicitudesEjecución paralela[1] https://es.wikipedia.org/wiki/Función_hash [2] https://en.wikipedia.org/wiki/Consistent_hashing (no existe traducción al español) [3] https://en.wikipedia.org/wiki/Wikipedia:Statistics (1.8 ediciones por segundo) |
Esta semana a cargo @kuryaki
Siguiente semana @guilleiguaran
The text was updated successfully, but these errors were encountered: