| title | date | categories | tags | permalink | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
Redis 集群 |
2020-06-24 03:45:38 -0700 |
|
|
/pages/77dfbe/ |
Redis 集群(Redis Cluster) 是 Redis 官方提供的分布式数据库方案。
既然是分布式,自然具备分布式系统的基本特性:可扩展、高可用、一致性。
- Redis 集群通过划分 hash 槽来分区,进行数据分享。
- Redis 集群采用主从模型,提供复制和故障转移功能,来保证 Redis 集群的高可用。
- 根据 CAP 理论,Consistency、Availability、Partition tolerance 三者不可兼得,而 Redis 集群的选择是 AP。Redis 集群节点间采用异步通信方式,不保证强一致性,尽力达到最终一致性。
Redis 集群由多个节点组成,节点刚启动时,彼此是相互独立的。节点通过握手( CLUSTER MEET 命令)来将其他节点添加到自己所处的集群中。
向一个节点发送 CLUSTER MEET 命令,可以让当前节点与指定 IP、PORT 的节点进行握手,握手成功时,当前节点会将指定节点加入所在集群。
集群节点保存键值对以及过期时间的方式与单机 Redis 服务完全相同。
Redis 集群节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求。
分布式存储需要解决的首要问题是把 整个数据集 按照 分区规则 映射到 多个节点 的问题,即把 数据集 划分到 多个节点 上,每个节点负责 整体数据 的一个 子集。
Redis 集群通过划分 hash 槽来将数据分区。Redis 集群通过分区的方式来保存数据库的键值对:集群的整个数据库被分为 16384 个哈希槽(slot),数据库中的每个键都属于这 16384 个槽的其中一个,集群中的每个节点可以处理 0 个或最多 16384 个槽。如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态。
通过向节点发送 CLUSTER ADDSLOTS 命令,可以将一个或多个槽指派给节点负责。
> CLUSTER ADDSLOTS 1 2 3
OK
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 – 5500
- 节点B存储的哈希槽范围是:5501 – 11000
- 节点C存储的哈希槽范围是:11001 – 16384
当客户端向节点发送与数据库键有关的命令时,接受命令的节点会计算出命令要处理的数据库属于哪个槽,并检查这个槽是否指派给了自己:
- 如果键所在的槽正好指派给了当前节点,那么当前节点直接执行命令。
- 如果键所在的槽没有指派给当前节点,那么节点会向客户端返回一个 MOVED 错误,指引客户端重定向至正确的节点。
决定一个 key 应该分配到那个槽的算法是:计算该 key 的 CRC16 结果再模 16834。
HASH_SLOT = CRC16(KEY) mod 16384
当节点计算出 key 所属的槽为 i 之后,节点会根据以下条件判断槽是否由自己负责:
clusterState.slots[i] == clusterState.myself
当节点发现键所在的槽并非自己负责处理的时候,节点就会向客户端返回一个 MOVED 错误,指引客户端转向正在负责槽的节点。
MOVED 错误的格式为:
MOVED <slot> <ip>:<port>
个人理解:MOVED 这种操作有点类似 HTTP 协议中的重定向。
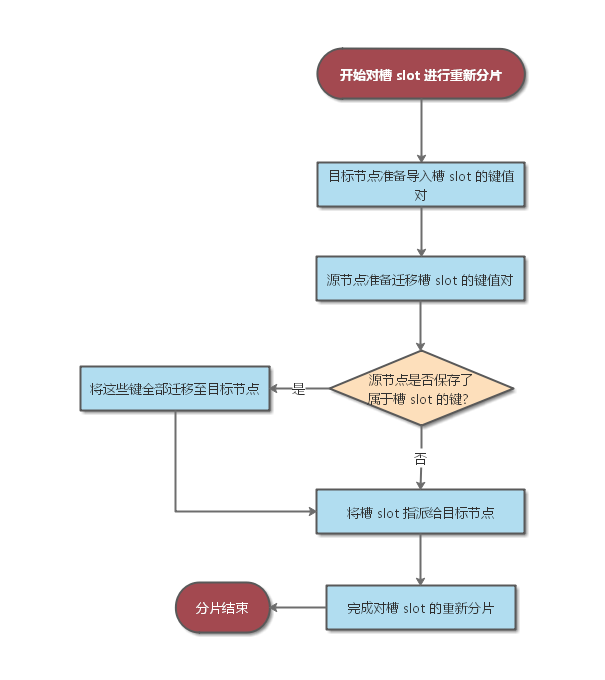
Redis 集群的重新分区操作可以将任意数量的已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点被移动到目标节点。
重新分区操作可以在线进行,在重新分区的过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
Redis 集群的重新分区操作由 Redis 集群管理软件 redis-trib 负责执行的,redis-trib 通过向源节点和目标节点发送命令来进行重新分区操作。
重新分区的实现原理如下图所示:
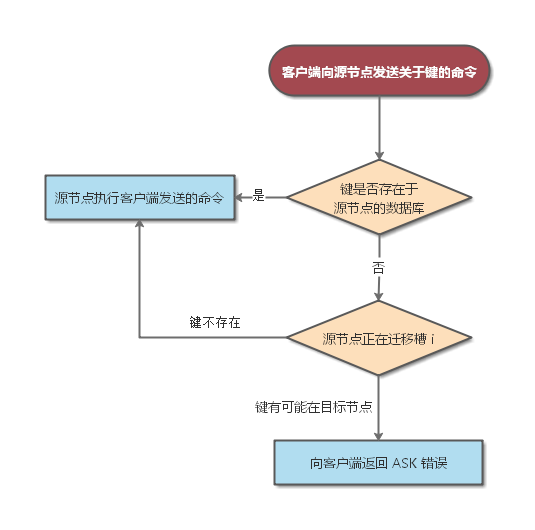
ASK 错误与 MOVED 的区别在于:ASK 错误只是两个节点在迁移槽的过程中使用的一种临时措施,在客户端收到关于槽 X 的 ASK 错误之后,客户端只会在接下来的一次命令请求中将关于槽 X 的命令请求发送至 ASK 错误所指示的节点,但这种转向不会对客户端今后发送关于槽 X 的命令请求产生任何影响,客户端仍然会将关于槽 X 的命令请求发送至目前负责处理槽 X 的节点,除非 ASK 错误再次出现。
判断 ASK 错误的过程如下图所示:
Redis 复制机制可以参考:Redis 复制
集群中每个节点都会定期向集群中的其他节点发送 PING 消息,以此来检测对方是否在线。
节点的状态信息可以分为:
-
在线状态;
-
下线状态(FAIL);
-
疑似下线状态(PFAIL),即在规定的时间内,没有应答 PING 消息;
- 下线主节点的所有从节点中,会有一个从节点被选中。
- 被选中的从节点会执行
SLAVEOF no one命令,成为新的主节点。 - 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
- 新的主节点向集群广播一条 PONG 消息,告知其他节点这个从节点已变成主节点。
Redis 集群选举新的主节点流程基于共识算法:Raft
集群中的节点通过发送和接收消息来进行通信。
Redis 集群节点发送的消息主要有以下五种:
MEET- 请求接收方加入发送方所在的集群。PING- 集群中每个节点每隔一段时间(默认为一秒)从已知节点列表中随机选出五个节点,然后对这五个节点中最久没联系的节点发送 PING 消息,以此检测被选中的节点是否在线。PONG- 当接收方收到发送方发来的 MEET 消息或 PING 消息时,会返回一条 PONG 消息作为应答。FAIL- 当一个主节点 A 判断另一个主节点 B 已经进入 FAIL 状态时,节点 A 会向集群广播一条关于节点 B 的 FAIL 消息,所有收到这条消息的节点都会立即将节点 B 标记为已下线。PUBLISH- 当节点收到一个 PUBLISH 命令时,节点会执行这个命令,并向集群广播一条 PUBLISH 消息,所有接受到这条消息的节点都会执行相同的 PUBLISH 命令。
Redis 集群相对 单机,存在一些功能限制,需要 开发人员 提前了解,在使用时做好规避。
-
key批量操作 支持有限:类似mset、mget操作,目前只支持对具有相同slot值的key执行 批量操作。对于 映射为不同slot值的key由于执行mget、mget等操作可能存在于多个节点上,因此不被支持。 -
key事务操作 支持有限:只支持 多key在 同一节点上 的 事务操作,当多个key分布在 不同 的节点上时 无法 使用事务功能。 -
key作为 数据分区 的最小粒度,不能将一个 大的键值 对象如hash、list等映射到 不同的节点。 -
不支持 多数据库空间:单机 下的 Redis 可以支持
16个数据库(db0 ~ db15),集群模式 下只能使用 一个 数据库空间,即db0。 -
复制结构 只支持一层:从节点 只能复制 主节点,不支持 嵌套树状复制 结构。
Redis Cluster 的优点是易于使用。分区、主从复制、弹性扩容这些功能都可以做到自动化,通过简单的部署就可以获得一个大容量、高可靠、高可用的 Redis 集群,并且对于应用来说,近乎于是透明的。
所以,Redis Cluster 非常适合构建中小规模 Redis 集群,这里的中小规模指的是,大概几个到几十个节点这样规模的 Redis 集群。
但是 Redis Cluster 不太适合构建超大规模集群,主要原因是,它采用了去中心化的设计。
Redis 的每个节点上,都保存了所有槽和节点的映射关系表,客户端可以访问任意一个节点,再通过重定向命令,找到数据所在的那个节点。那么,这个映射关系表是如何更新的呢?Redis Cluster 采用了一种去中心化的流言 (Gossip) 协议来传播集群配置的变化。
Gossip 协议的优点是去中心化;缺点是传播速度慢,并且是集群规模越大,传播的越慢。
我们后面会部署一个 Redis 集群作为例子,在那之前,先介绍一下集群在 redis.conf 中的参数。
- cluster-enabled
<yes/no>- 如果配置”yes”则开启集群功能,此 redis 实例作为集群的一个节点,否则,它是一个普通的单一的 redis 实例。 - cluster-config-file
<filename>- 注意:虽然此配置的名字叫“集群配置文件”,但是此配置文件不能人工编辑,它是集群节点自动维护的文件,主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。通常是在收到请求之后这个文件就会被更新。 - cluster-node-timeout
<milliseconds>- 这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请求。 - cluster-slave-validity-factor
<factor>- 如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。如果设置成正数,则 cluster-node-timeout 乘以 cluster-slave-validity-factor 得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。假设 cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过 50 秒,此从节点不能成为主节点。注意,如果此参数配置为非 0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。 - cluster-migration-barrier
<count>- 主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。更详细介绍可以看本教程后面关于副本迁移到部分。 - cluster-require-full-coverage
<yes/no>- 在部分 key 所在的节点不可用时,如果此参数设置为”yes”(默认值), 则整个集群停止接受操作;如果此参数设置为”no”,则集群依然为可达节点上的 key 提供读操作。
Redis Cluster 不太适合用于大规模集群,所以,如果要构建超大 Redis 集群,需要选择替代方案。一般有三种方案类型:
- 客户端分区方案
- 代理分区方案
- 查询路由方案
客户端 就已经决定数据会被 存储 到哪个 Redis 节点或者从哪个 Redis 节点 读取数据。其主要思想是采用 哈希算法 将 Redis 数据的 key 进行散列,通过 hash 函数,特定的 key会 映射 到特定的 Redis 节点上。
客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前,业界普遍使用的 Redis 多实例集群 方法。Java 的 Redis 客户端驱动库 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool。
-
优点:不使用 第三方中间件,分区逻辑 可控,配置 简单,节点之间无关联,容易 线性扩展,灵活性强。
-
缺点:客户端 无法 动态增删 服务节点,客户端需要自行维护 分发逻辑,客户端之间 无连接共享,会造成 连接浪费。
客户端 发送请求到一个 代理组件,代理 解析 客户端 的数据,并将请求转发至正确的节点,最后将结果回复给客户端。
- 优点:简化 客户端 的分布式逻辑,客户端 透明接入,切换成本低,代理的 转发 和 存储 分离。
- 缺点:多了一层 代理层,加重了 架构部署复杂度 和 性能损耗。
代理分区 主流实现的有方案有 Twemproxy 和 Codis。
Twemproxy 也叫 nutcraker,是 Twitter 开源的一个 Redis 和 Memcache 的 中间代理服务器 程序。
Twemproxy 作为 代理,可接受来自多个程序的访问,按照 路由规则,转发给后台的各个 Redis 服务器,再原路返回。Twemproxy 存在 单点故障 问题,需要结合 Lvs 和 Keepalived 做 高可用方案。
- 优点:应用范围广,稳定性较高,中间代理层 高可用。
- 缺点:无法平滑地 水平扩容/缩容,无 可视化管理界面,运维不友好,出现故障,不能 自动转移。
Codis 是一个 分布式 Redis 解决方案,对于上层应用来说,连接 Codis-Proxy 和直接连接 原生的 Redis-Server 没有的区别。Codis 底层会 处理请求的转发,不停机的进行 数据迁移 等工作。Codis 采用了无状态的 代理层,对于 客户端 来说,一切都是透明的。
-
优点:实现了上层 Proxy 和底层 Redis 的 高可用,数据分区 和 自动平衡,提供 命令行接口 和 RESTful API,提供 监控 和 管理 界面,可以动态 添加 和 删除 Redis 节点。
-
缺点:部署架构 和 配置 复杂,不支持 跨机房 和 多租户,不支持 鉴权管理。
客户端随机地 请求任意一个 Redis 实例,然后由 Redis 将请求 转发 给 正确 的 Redis 节点。Redis Cluster 实现了一种 混合形式 的 查询路由,但并不是 直接 将请求从一个 Redis 节点 转发 到另一个 Redis 节点,而是在 客户端 的帮助下直接 重定向( redirected)到正确的 Redis 节点。
-
优点:去中心化,数据按照 槽 存储分布在多个 Redis 实例上,可以平滑的进行节点 扩容/缩容,支持 高可用 和 自动故障转移,运维成本低。
-
缺点:重度依赖 Redis-trib 工具,缺乏 监控管理,需要依赖 Smart Client (维护连接,缓存路由表,
MultiOp和Pipeline支持)。Failover 节点的 检测过慢,不如有 中心节点 的集群及时(如 ZooKeeper)。Gossip 消息采用广播方式,集群规模越大,开销越大。无法根据统计区分 冷热数据。