注意!本内容は「WebエンジニアのためのC言語入門ハンズオン #1」をやったことを前提にしています。
- mallocとfree
- 構造体
- データ構造の自作
- ヘッダーファイル
- 実習
- char
- int
- float
- double
- 上記データ型の配列 ※文字列型とかありません。
if elsefor whileswitchサブルーチン(function)break continuegotoと名札
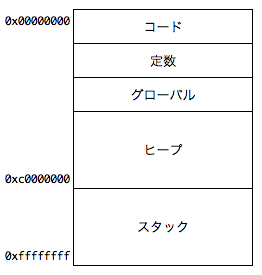 今回のハンズオンでは、
今回のハンズオンでは、ヒープを使います。
C言語では、全ての引数は値渡しです。
そのため、基本データ型(char,int,float,double)以外のデータをやり取りしたい場合は
型を指定したメモリアドレスを使って、関数間のデータの受け渡しを行います。
ポインターで利用する演算子は、主に以下の2つです。
- 間接演算子
* - アドレス演算子
&
余程の小さいプログラムを除いて、プログラム内の関数間でデータをやり取りするため
C言語のプログラムでは、mallocという関数を使ってヒープに領域を確保して、情報を保持させます。
mallocはstdlib.hという共有ライブラリに含まれます。
memory allocationを略したものです。
freeは、ヒープに確保した領域を解放します。
ヒープに確保した領域は明示的に解放しなければ、プログラムの実行が終了するまで解放されません。
デーモンプログラムなどでは、メモリの解放忘れは致命的です。 プロセスが長く生存するに従って、解放されないメモリ領域が増えていき、メモリを使い尽くしてしまいます。 これはメモリリークと呼ばれます。
mallocしたらfreeして解放しなければなりません。2つはセットです。
とある現場では、巨大なデーモンプログラムのどこでメモリリークが発生しているのかを特定出来なかったため 3日に1回の頻度で、強制的に再起動することで、メモリの解放を行っていました。 あのプログラムはまだ動いているのだろうか・・・。
mallocは引数として、確保するメモリのサイズをbyteで指定します。 しかし、各データ型のサイズはOS依存があるので、そのまま数字で指定すると異なるOSでの動作が期待しない結果を生んでしまう可能性があります。
そのようなOS依存を解決する手段として、mallocのメモリサイズ指定はsizeof演算子を使って指定するのが一般的なようです。
例えば、文字列(charの配列)10文字分のメモリ空間を確保する場合は・・・
(char *)malloc(sizeof(char)*10);
こんな風に使います。
※sizeof演算子は任意のデータ型や、構造体に対して使えます。
mallocを体験するプログラムです。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char * getString(){
char * str;
str = (char *) malloc (sizeof(char) * 8);
strcpy(str, "abcdefg");
return str;
}
int main (){
char * str;
str = getString();
printf("str => %s\n", str);
}
ex1-1.cという名前で保存して下さい。gcc -o ex1-1 ex1-1.cでコンパイルして下さい。- 実行ファイル
ex1-1を実行して下さい。
getString関数内でヒープを確保し、mainにポインターを戻しています。 このように関数間でデータの受け渡しをする場合は、ヒープを使います。
※基本データ型であれば、値渡しで受け渡しが出来ます。
1-1はmallocはしたものの、freeをしてません。 main関数にfreeを追記しましょう。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char * getString(){
char * str;
str = (char *) malloc (sizeof(char) * 8);
strcpy(str, "abcdefg");
return str;
}
int main (){
char * str;
str = getString();
printf("str => %s\n", str);
free(str);
printf("str => %s\n", str);
}
ex1-2.cという名前で保存して下さい。gcc -o ex1-2 ex1-2.cでコンパイルして下さい。- 実行ファイル
ex1-2を実行して下さい。
2つ目のprintlnでは、何と出力されたでしょうか?
freeは、プログラムがメモリ領域を再割当て可能な状態にするという意味です。 そのため、freeされた直後であれば、メモリ内には同じ内容が残っています。
※この性質を利用して、メモリ内の情報を読取る攻撃もあります。
アンチパターンとして、グローバル変数を使ってデータの受け渡しをするプログラムを書いてみましょう。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char gstr[15];
void setGlobalString(){
strcpy(gstr, "This is Global");
}
int main (){
printf("str => %s\n", gstr);
setGlobalString();
printf("str => %s\n", gstr);
}
ex1-3.cという名前で保存して下さい。gcc -o ex1-3 ex1-3.cでコンパイルして下さい。- 実行ファイル
ex1-3を実行して下さい。
グローバル変数を使っているので、小規模なプログラムではスッキリ見えます。 しかし、規模が大きくなるにつれ、グローバル空間を汚したことが大きな負債となって現れます。
グローバル空間は、定数で使うのみにするのが懸命と思います。
- C言語のプログラムで、基本データ型以外のデータを関数間でやり取りする場合は、ヒープを使う。
- メモリを割り当てる時はmallocを使うが、sizeof関数を使うことで、バイト数をハードコードしないようにする。
- 割り当てたらfreeで解放する。
- 上手くいかないからといって、やけになってglobalを使わない。
mallocで確保できるメモリの最大量はどれくらいでしょうか?
実メモリよりも大きいメモリサイズをmallocで割り当て出来るのでしょうか?
答えはYesです。
64bitOS以前はメモリは貴重な存在でした。 メモリサイズが小さいため、実メモリより大きい値をmallocがセットした時にエラーにしてしまうと、 プログラムがメモリサイズに縛られてしまうことになります。
そのため、各OSはオーバーコミットという仕組みを用意していて、実メモリよりも大きいメモリサイズをプログラムが割り当てしても エラーにならないようにしています。これはC言語の仕組みというよりは、OS側の仕様です。
あまりにも実メモリサイズとかけ離れた割り当ては、制限されるそうです。
構造体は、基本データ型、及び任意のポインタ の組み合わせで構成されるユーザ定義のデータの集まりです。
C言語では、関数も関数ポインタという形で、ポインタ扱い可能です。
データを定義できて、関数をもつことができる。オブジェクト指向のクラスに近いです。 アクセス修飾子とかはないですが・・・。
構造体でデータ構造を定義出来れば、プログラムをスッキリ書くことが出来ます。 また、多すぎる引数を持つ関数があった場合にも、構造体のポインターだけを渡すことができれば、見通し良くなります。
typedef struct <型の別名(省略可)> {
<型に所属するデータの定義> ;
<型に所属するデータの定義> ;
<型に所属するデータの定義> :
} <型名>;
とりあえず構造体を作ってみましょう。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct animal {
char * type;
char * voice;
} animal;
void printAnimal(struct animal * an){
printf("type => %s\n", an->type);
printf("voice => %s\n", an->voice);
}
int main(){
struct animal * tama = (struct animal *) malloc (sizeof(struct animal));
tama->type = (char *) malloc (1024);
tama->voice = (char *) malloc (1024);
strcpy((*tama).type, "cat");
strcpy((*tama).voice, "meow");
printAnimal(tama);
struct animal * pochi = (struct animal *) malloc (sizeof(struct animal));
pochi->type = (char *) malloc (1024);
pochi->voice = (char *) malloc (1024);
strcpy(pochi->type, "dog");
strcpy(pochi->voice, "bowow");
printAnimal(pochi);
}
ex2-1.cという名前で保存して下さい。gcc -o ex2-1 ex2-1.cでコンパイルして下さい。- 実行ファイル
ex2-1を実行して下さい。
文字列配列を2つ持つ、animalという構造体を定義しました。 構造体を使う時のポイントは以下のとおりです。
- 構造体自体を作成するときは、メモリ領域を確保する。
- 構造体に定義された変数にアクセスする方法2つ、括弧を使う方法とアロー演算子
構造体内のポインターや、基本データ型に参照する方法は2つの書き方があります。
上のコードの(*tama)は、tamaという構造の実体を表現しています。
構造体の実体の変数にドットを使ってアクセスしています。
しかし、この表記は非常に見づらいですし、記述するのも大変です。 そこで、アロー演算子が用意されています。
(* tama).voice = tama->voice
PHPのアロー演算子は、きっとココから来ているのですね。
構造体自体をポインターとして扱う場合は、ドット記法は長くて書きづらいです。 しかし、構造体を宣言した場所では、アロー演算子でアクセスすると意味がおかしくなってしまいます。
例えば、こういう場合です。
struct animal hanhan;
hanhan.type = (char *) malloc (1024);
hanhan.voice = (char *) malloc (1024);
strcpy(hanhan.type, "neko");
strcpy(hanhan.voice, "fugafuga");
printAnimal(&hanhan);
構造体をポインターではなく、main関数内でのローカル変数として宣言してます。
この場合は、アロー演算子でアクセスするとエラーになってしまします。
あくまでも、構造体ポインターに対する実体参照操作を楽にするのがアロー演算子であることを覚えておいて下さい。
2-1のプログラムにはわざとらしく欠点を残して置きました。
- 欠点とは何でしょうか?
- 欠点を補うためのコードを記述してみて下さい。
(解答例は最後に書いておきました。)
C言語では、言語自体がサポートするデータ型が少ないので、欲しいデータ構造は自作するのが普通のようです。 そのため、他の言語では用意されているようなハッシュマップやリンクドリストのような便利なデータ構造も全て自作する必要があります。
一見、すごく面倒くさそうに見えますが、実は利点があります。
- データ構造を自作すると、その構造が持つ計算量が把握出来る。
- データ構造を自作すると、その構造が持つデータ量も把握出来る。
用意されている構造を使うだけでは、得られない知見を得ることが出来ます。 当ハンズオンでも、単純なデータ構造を自作してみましょう。
もっとも単純なデータ構造として、片方向のリンクドリストを作成します。

#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct linkedList {
int value;
struct linkedList * next;
} linkedList;
struct linkedList * createList(int value){
struct linkedList * list = (struct linkedList *) malloc (sizeof(struct linkedList));
list->value = value;
list->next = NULL;
return list;
}
void addList(struct linkedList * list, int value){
struct linkedList * current;
current = list;
while(current->next != NULL){
current = current->next;
}
current->next = createList(value);
}
void printList(struct linkedList * list){
struct linkedList * current;
current = list;
while(1){
printf("value = %d\n", current->value);
if(current->next == NULL){
break;
}
current = current->next;
}
}
int main(){
struct linkedList * list = createList(15);
addList(list, 22);
addList(list, 5);
addList(list, 8);
printList(list);
}
ex3-1.cという名前で保存して下さい。gcc -o ex3-1 ex3-1.cでコンパイルして下さい。- 実行ファイル
ex3-1を実行して下さい。
演習問題2と同じようにfreeが足りていません。 片方向リストを再帰的にfreeする関数を作ってみて下さい。
(解答例はハンズオン後にお見せします。)
共有ライブラリをインクルードするとき、hoge.hという名前を使いますが、hってなんでしょうか? hの拡張子をもつファイルはヘッダーファイルと呼ばれます。
実際にヘッダーファイルを見てみましょう。
LinuxOSであれば、/usr/includeの下にヘッダーファイルが入っています。
試しにstdio.hの中身を見てみます。
Mac OSXのstdio.hの一部抜粋
/* stdio buffers */
struct __sbuf {
unsigned char *_base;
int _size;
};
int fgetc(FILE *);
int fgetpos(FILE * __restrict, fpos_t *);
char *fgets(char * __restrict, int, FILE *);
難しそうな記述が沢山見えますが、どうでしょうか? 1つずつをよく見てみると、読めそうじゃないですか?
実はヘッダーファイルは、単なるCのファイルです。
C言語では、関数は巻き上がりません。そのため、関数は使う場所よりも前で宣言されている必要があります。 しかし、全ての関数を利用する順序に並べるのは大変です。
そこで、関数を定義と実装の2つ用意して、定義部分を先に読ませてしまいます。 この定義の事をプロトタイプ宣言と呼びます。
ヘッダーファイルとは、一般的にはプロトタイプ宣言や、定数、グローバル変数をまとめた物です。 このファイルを先頭でincludeすることで、関数の未定義を防いだり、共通部分をまとめたりします。
プロトタイプ宣言をやってみましょう。
#include <stdio.h>
int main(){
int z = add(4, 5);
printf("result is => %d\n", z);
}
int add(int x, int y){
return x + y;
}
ex4-1-1.cという名前で保存して下さい。gcc -o ex4-1-1 ex4-1-1.cでコンパイルして下さい。- 実行ファイル
ex4-1-1を実行して下さい。
警告の内容を読んでみて下さい。 implicit declaration(暗黙の宣言)というのは、宣言がされていませんよ?というエラーです。
#include <stdio.h>
int add(int x, int y);
int main(){
int z = add(4, 5);
printf("result is => %d\n", z);
}
int add(int x, int y){
return x + y;
}
ex4-1-2.cという名前で保存して下さい。gcc -o ex4-1-2 ex4-1-2.cでコンパイルして下さい。- 実行ファイル
ex4-1-2を実行して下さい。
警告は消えたはずです。
関数の{}を削除すれば、プロタイプ宣言の完成です。
※行末にセミコロンが必要です。
関数
int getTax(){
//色々書いてある
}
プロタイプ宣言
int getTax();
プロトタイプ宣言や、グローバル変数の定義を一つのファイル にまとめて、拡張子hでファイルを作成します。
#include "common.h"
ex4-2.cという名前で保存して下さい。gcc -o ex4-2 ex4-2.cでコンパイルして下さい。- 実行ファイル
ex4-2を実行して下さい。
ある程度の規模のCプログラムであれば、必ずヘッダーファイルを作る・・・と思います。 ヘッダーファイルを用意することで、複数のファイルから、関数を呼び出すことが可能となります。
ヘッダーファイルのincludeは、<>ではなくダブルクォートで囲まれています。
ダブルクォートは、絶対パス・相対パスで、実在するファイルをincludeするときに使います。
作成したcommon.hは、共有ライブラリではないので、実際に存在するファイルパスでincludeします。
ここまでで、C言語の基本的な文法、お作法、ポインター、構造体まで学習しました。
おさらいとして、もっとも単純なソートアルゴリズムであるバブルソートを実装しましょう。 Cの配列を使っても良いのですが、おさらいとして、本日作成した単方向リストを使って実装しましょう。
1から実装するのは、何なので演習問題3-2をベースに作って行きます。
任意のコレクションのN番目の値と、N+1番目の値を比較して、大きければ値を入れ替えるソートアルゴリズムです。 大きい値が次々とコレクションの後方にソートされていく様を水の中を浮き上がる泡に例えています。
入力値は、演習3-1と同様とします。つまり・・・
15, 22, 5, 8の順番に並んでいます。
sortListという名前の関数を作成して下さい。
printListの手前でsortListを呼び出して、LinkedListをソートします。
5, 8, 15, 22の順番に出力されたら正解です!
バブルソートの処理を順に考えると、LinkedListの値は、以下の様な順番で並び替わって行きます。
15, 22, 5, 815, 5, 22, 815, 5, 8, 225, 15, 8, 225, 8, 15, 22
hanhan1978が学習に用いた本達です。良書厳選。
- プログラミング言語C (K&R)





受け取った構造体の中身を1つずつfreeします。
最後に構造体そのものもfreeします。
void freeAnimal(struct animal * an){
free(an->type);
free(an->voice);
free(an);
}
LinkedListを順番にfreeしていきます。
次の構造体のポインタを取得したら、現在の構造体のメモリ空間を解放します。
void freeList(struct linkedList * list){
struct linkedList * cur;
struct linkedList * nex;
cur = list;
while(1){
nex = cur->next;
free(cur);
if(nex == NULL){
break;
}
cur = nex;
}
}
int sortList(struct linkedList * list){
struct linkedList * cur;
struct linkedList * nex;
cur = list;
int changed = 0;
while(1){
nex = cur->next;
if(nex == NULL){
break;
}
if(cur->value > nex->value){
int tmp = cur->value;
cur->value = nex->value;
nex->value = tmp;
changed = 1;
}
cur = nex;
}
if (changed){
sortList(list);
}
return 0;
}