Coordinator crash when adding a device #82004
Comments
|
Hey there @dmulcahey, @Adminiuga, @puddly, mind taking a look at this issue as it has been labeled with an integration ( Code owner commandsCode owners of
(message by CodeOwnersMention) zha documentation |
|
Its the first gen SonOff MG21 coordinator and it shall working with the standard firmware for the repro. Is the network long in production or is in new formed ? Sonoff have making one hot fix then have running EZSP 7.X that is extending the NVM for token storage and going back to EZSP 6.10.3.0 or earlier is the coordinator crashing. If you is not having to many device try the fix by flashing the https://github.com/xsp1989/zigbeeFirmware/blob/master/firmware/Zigbee3.0_Dongle-NoSigned/EZSP/nvm3_initfile.gbl. I think it shall being safe letting ZHA restoring the network after have flashing it. The issue and the GBL file xsp1989/zigbeeFirmware#28 (comment). |
|
Hey there @MattWestb ! Thank you for looking into my issue! 😃 For the NVM, is it something that is written by the network backup? Because I can observe this issue with 2 different coordinators with different firmware provider. I can destroy the NVM portion in question with the proposed firmware but considering I see this issue with 2 different coordinator, could that be involved in the issue? If I erase this portion, what would be the consequences? I can do a network analysis if needed but for now, I’m not entirely sure where the issue reside. Would it definitively be the coordinator or Home-Assistant could be involved? I overcame lot’s of issues on my network over the time but this one hits me quite hard as it renders my whole network unusable and I can’t pinpoint where the issue reside. It also can happen when you don’t expect it with the problem that lights start to flash as well. |
|
You need to provide the debug logs.
|
|
I posted this in the initial post but I might be misunderstanding what is meant by debug log, sorry if it is not what you are asking for. This was generated with the following : If you need other occurrences, I have several to look at. 😸 |
|
The dongle crashes with |
|
Can you try this configuration? zha:
zigpy_config:
ezsp_config:
CONFIG_ADDRESS_TABLE_SIZE: 16 # FW: 32, ZHA: 16
CONFIG_MULTICAST_TABLE_SIZE: 8 # FW: 8, ZHA: 16
CONFIG_PACKET_BUFFER_COUNT: 250 # FW: 250, ZHA: 255
CONFIG_SOURCE_ROUTE_TABLE_SIZE: 16 # FW: 200, ZHA: 16
CONFIG_TRUST_CENTER_ADDRESS_CACHE_SIZE: 2 # FW: 0, ZHA: 2Related: itead/Sonoff_Zigbee_Dongle_Firmware#10 If this indeed fixes the problem and you can reliably reproduce the crash, it would be super helpful if you could help us narrow down which of the config options solves the problem. Something about Sonoff's build of EmberZNet is unstable. |
|
So, currently I am using the https://www.aliexpress.com/item/1005003578599189.html?spm=a2g0o.order_list.0.0.46f01802MxU13p with the https://github.com/xsp1989/zigbeeFirmware/blob/master/firmware/Zigbee3.0_Dongle-NoSigned/EZSP/ncp-uart-sw_v6.10.3_115200.gbl firmware. Just tried the configuration you gave me. Unfortunately, it still did it.
Here is the log : I can see that the NCP failed : But also that there is no memory available for this configuration : As for the firmware, I can always try any of the following : Thank you for your kind help! 😺 |
|
If installing the linked EZSP 7.X and like going back to one lower version you must erasing the NVM / tocke with the GBL file i meted before or the NCP is crashing. You can also trying one of Garys cooked for sonoff ZBB that have the same Zigbee-module and shall being pin compatible (its for hacked ZBB without signing that only the ZBB is using and shall working on the sticks 2). PS. EZSP 6.5.5 is working but is not recommended the its have many bad bugs also with 6.8.X and 6.9.X and working good / recommended ones is 6.10.X and late 6.7.X. |
|
Does the issue only happen with that particular bulb? Although it very likely isn't the issue, were you ever able to pair it via Bluetooth to your phone? Firmware version |
|
@TheJulianJES at first I believed it was this bulb in particular but then anything I pair (ex : an IKEA bulb) it does the same thing. The issue still persist, I am to believe the issue is not from the bulb but rather the coordinator. Now, how I can diagnose this, it’s a little bit harder, I'm not sure where to look. I can capture the network activity, but I don’t know if my answers will be there. One thing I found interesting, someone was kind enough to show me their coordinator backup and I found one difference between mine and his, I have to note that a while back, I did migrate from one coordinator to another with zigpy since it was not yet implemented in Home-Assistant. I can see that mine is missing this portion : Would that be normal? I can see in my first ever back-up the tc_link_key was indeed present. Is it why new devices have such a hard time joining but not older ones? |
|
I think your backup is done with normal TC-Link keys stored in the chip NVM / token storage in the flash chip and is getting problems then restoring it on the new coordinator that is using hashed TC-Link keys. @puddly Is the coordinator restore from one other coordinator (not EZSP) to one EZSP working OK or if the backup of EZSP network was formed with one EZSP that was not using hashed TC-Link keys (old install with EM53X coordinator) and restoring the backup on one new with not formed network in the chip = forming one Hashed TC-Link key network ?? Trying |
|
You can retroactively apply hashed link key settings. I’ve done it. I’ll dig the commands up later |
|
All you need to do to upgrade to hashed link keys is to click the "Migrate" button and reconfigure the current radio. If you restore the most recent backup, it'll upgrade you to a hashed link key automatically when re-forming the network. |
|
@dmulcahey i’d be very happy if that’s what I need to solve my issue! |
|
Ah, I forgot it won't actually perform a restore if the current settings are identical to the new settings. You will have to leave the current network first, either by:
ZHA will auto-restore in the second scenario. |
|
Hey @puddly ! Thanks for helping me out! I’m not sure why. Since I have my original key, could I write it in the backup and restore from it? |
|
Something isn't adding up. Can you post a full debug log of the backup and restore? $ zigpy -vvv radio --baudrate 115200 ezsp /dev/ttyUSB0 backup -z > backup.json
$ cat backup.json
$ zigpy -vvv radio --baudrate 115200 ezsp /dev/ttyUSB0 restore backup.json |
|
Thanks. According to the restore, one was written: Can you do another backup to confirm? |
|
Sooo strange. Now it did : Is something broken in Zigpy? |
|
The exact same code is used by network formation, backup restoration, and the ZHA config flow so I think either the original network was never cleared or your browser may have cached the downloaded backup. |
|
Does it still crash? |
|
It does. 😞 I removed the power from the newer bulb and re-applied it and the coordinator crashed : home-assistant_crash_2022_11_20.log There is no crash when I do the same for older devices of the network. I also can’t add new devices to the coordinator following the restore by zigpy cli. @MattWestb : I’ll try erasing the NVM portion tomorrow as you recommended. You say it is used to store keys? |
|
@mguaylam If Puddly is not finding any other way i think flashing the NVM fix is one way also reflashing the EZSP 6.10.3 at the same time you have hocked up i think can being good (but the EZSP first and then the NVM fix). The NVM fix is writing one empty file over the aria the token storage is in the flash. I can see that you have writing one new IEEE then changing from the EM358X coordinator and it shall not being any problems as long the old coordinator is not online in your radio range. Fast look in the log i finding little strange that the system is reading the manufacture tokens many times (first time its having problems) then the normal is only doing then initializing the coordinator and perhaps then (our Puddly) is doing one new backup. |
|
I flashed the 6.10.3 firmware from : https://github.com/xsp1989/zigbeeFirmware/blob/master/firmware/Zigbee3.0_Dongle-NoSigned/EZSP/ncp-uart-sw_v6.10.3_115200.gbl then https://github.com/xsp1989/zigbeeFirmware/blob/master/firmware/Zigbee3.0_Dongle-NoSigned/EZSP/nvm3_initfile.gbl but the coordinator was not responding correctly on the serial connection. I did the inverse and it worked. I still can’t add new devices now, it’s very strange. I also confirmed the coordinator still crash : I indeed came from a EM358X (HUSBZB-1) which I have get rid of a while ago. My system is a full fledged server so I’d be surprised there would be performance issues from there. |
|
It is a HPE Tower Server running Fedora with pods built on Podman. It only has USB 2 ports. I tried an extension cable this morning to be sure it wasn’t that. My Wi-Fi access point is on channel 11 and my ZigBee network is on channel 15. No overlapping. The coordinator I'm using is the easyIoT on v.6.10.3 built by xsp1989 but I tried the SonOff-E coordinator with ITEAD v.6.10.3 firmware as well in case the coordinator itself was the issue. I also tried the easyIoT with v.6.7.9 built by xsp1989 in the hope it would be a bug in the 6.10.3 firmware. As for restoring, I did a restore on both of these coordinators, never a new network. I tried a form a new network on the easyIoT before restoring but the result was the same. |
|
I think I'm onto something. I need to analyze more; I can send also the capture file in private. Then I can see an insane amount of network conflicts coming from my 4 Sinope thermostats and it goes very fast, i’m wondering if that’s what crash my coordinator : The thing is, now I’m wondering if my issues started exactly after I added those thermostats to my network. But I never heard of anyone having such issue with their Sinope thermostats. Then I see a lot of beacons and I’m not sure where they are coming from, I see some from smart meters from my electricity company (but only a few) : Then a non-tree link failure from my unscrewed bulb : Then the network seem’s to start : Do Philips bulbs flash like that when there is an address conflict? Would the address conflict broadcast-ed by the thermostats be the reason the coordinator crash? |






|
If i remember right is old HUE blinking then there is rejoining the network (Its in the black box of bad Zigbee devices then is not deleting children that have jumping / leave the network). I think its not the coordinator that is the problem for the moment i think its the network that is stalling then so many device is out of sync (all is having the network key but the frame counter is not OK and cant updating all things then the TC-Link key is new for all devices). If i was you i should setting up one new network with different PAN-ID, Extended PAN-ID and network key on one other Chanel (channel is not one must but is more safe) and adding / moving only some devices and see if they is working OK. One other variant is shutting down all devices and power on only some at the time and trying getting them working / syncing but i think its the same work if all is going well but is much more if not working OK compared with doing one new network. Also all devices need getting the new TC-Link key and must being resettled for getting it = the same work as making one new network. |
When there's an address conflict, the conflicting device would leave and re-join the network -> this would cause the light to blink because of the identify command.
The "nwk conflict" is a network broadcast and it is possible it is causing a crash, because you have reported quite high setting for the broadcast table, unless Before you get the 1st address conflict, what is the command which triggers it? Usually it is one very close to the 1st address conflict messages in the batch. What Address is reported to be conflicting? I see two scenarios for the address conflict:
|
|
I used to have a lot of "NWK Conflicts" in the network and for some reason it was caused by Interference. After I moved coordinator a little bit, it just started working. In the packet captures I was seeing this triggering the storm of conflicts: Notice the destination address of |
|
Nice Pan Corrupted NVM in the device or buggy firmware in I think then more or less all devices is not having one OK TC-Link key its no way getting the network back then devices cant doing private communication with TC and they need being retested and rejoined for getting it OK. |
|
Due to a couple of reasons, my main network is also running on a ZBDongle-E at the moment with this "custom" firmware. While it has mostly been working fine (coming from a CC2652 where older firmware had sub-optimal performance but newer firmware crashed after some time), I experienced some weird behavior yesterday that may or may not be related to this issue. A bit of a backstory is required though: HA version: 2022.12.0.dev20221127 (I also had some (similar) issues with 2022.11.4)
interview.mp4I have very little time at the moment, so I didn't really get to debugging this (video was also recorded on a phone). I should have saved the debug logs from that pairing to look at them later though.
This is why I even wrote up my interesting story of yesterday night. The coordinator is already on a USB extension and so on (not near any USB 3 plugs, APs, ...) and if the network works, it performs very well (light scene changes, ...). So yeah, uhm, not sure where exactly I was going with this, but maybe it contains some useful information to debug this problem. Also not sure how much longer my main network is going to be run off a ZBDongle-E. |
|
Do you get NWKID conflicts in the logs now? |
|
I think both was running network with stored TC-Link key and have merger to one EZSP that is using hashed Link-Keys. Also standard EZSP is only having 12 tokens (or less) for TC-Link so if merging from TI coordinator and have many Zigbee 3 devices its not enough token to storing all in the flash. I think in both cases is the network routing badly broken so the sending permit join the network cant broadcasting it to all devices then some / many router is blocked with some false network settings. @TheJulianJES Did you flashing the EZSP with the IEEE from the coordinator before then merger the network or is it running on the chip default ? And the XSP1989 firmware is from the original Sonoff ZBB but is shall working well on the new E-Dongle then the the pins used is the same and also EZSP 6.10.3 shall being stable on this devices and is more secure running then 7.X if getting problem. |
|
Here the third is coming !! One of my Billy RCP was having problems with IKEA controllers so i "converting" back to NCP 6.10.3.0 by stooping Silabs addon and flashing the chip with NCP firmware and pointing ZHA to the comport and restarting. I have one IKEA GU10 WS2 and one STOFTMOLN (Light engine 3 WS) as routers and one wireless dimmer and one Symphonisk. So i doing little sniffing then trying joining the controllers and i is getting the same error with tree error. Sadly i was not saving the sniff. The legend is that the RCP test have bin running on different chips but ZHA have restoring the network all the time and looks working OK. In my test setup it was looking like unicast to one joining sleeper was not working and ZHA is timing out all the time after the device have getting the network key and little more. I have not looking wot commands the TC is using the TC-Link key but 100% with routing things and some direct unicast. Most of the network traffic is only using network key for protection so shall not being any problems. I think if having this problems with one large production network is the best forming one new one with network key, PAN-ID and extended pan-id changed and start resetting / adding routers near the coordinator and extending the routers so getting full coverage and last adding the end devices. I shall doing more testing by flashing RCP firmware and letting ZHA attaching the network from Silabs addon to the chip (its normally working OK) and see if its making more problems with the TC-Link key then adding devices. Edit: The RCP / NCP have being changed some times then it was one IKEA Markus and ZHA have merger it OK all the swapping but somthing have going wrong with the TC-Link key. |
|
In 3.2.2 Trust Center Link Key is the answer then the TC-Link key is being used and one Zigbee 3 network cant working stable if its not being sett OK in all (router) device and also not (re)joining devices OK. |
Weirdly, I have disabled the identify effect upon joining but still get that effect from the GIF in the first post. It start as soon as the Sinopé thermostats declares an address conflict. Also happens then the coordinator is unplugged.
I can try but this happens even with the coordinator unplugged (basically offline).
I can’t see a direct conflict to a certain message but it seem’s to always be after 0xbd0f which is my new Philips Bulb. 0x965b is one of my thermostat. This screenshot is the first network conflict since unplugging my coordinator. It took about 10 minutes before the thermostats went crazy and all my (still on) lights started flashing. I have to note that it does not seem to be particular to this bulb, I tried another Philips Hue bulb of the same model with the same result, even an IKEA bulb does the same.
So, from my understanding, if a device see’s a network address conflict, it will broadcast a network conflict and the joining device is supposed to leave and try to come back with another address? Because I can’t see an indication of the culpit in the message. There is also no one else in the capture with 0x965b except : 50:0b:91:40:00:02:bc:68 Content of the shown frame selected above.
That would mean somehow my 4 thermostats are affected as they are the only ones reporting conflicts and when 1 starts, all 4 goes. How can I verify that they have the right information?
Unfortunately, I can’t see any conflict unless I misunderstand how the conflict process works. Devices reporting a conflict are alone using their address, I don’t see any other MAC using them. |

|
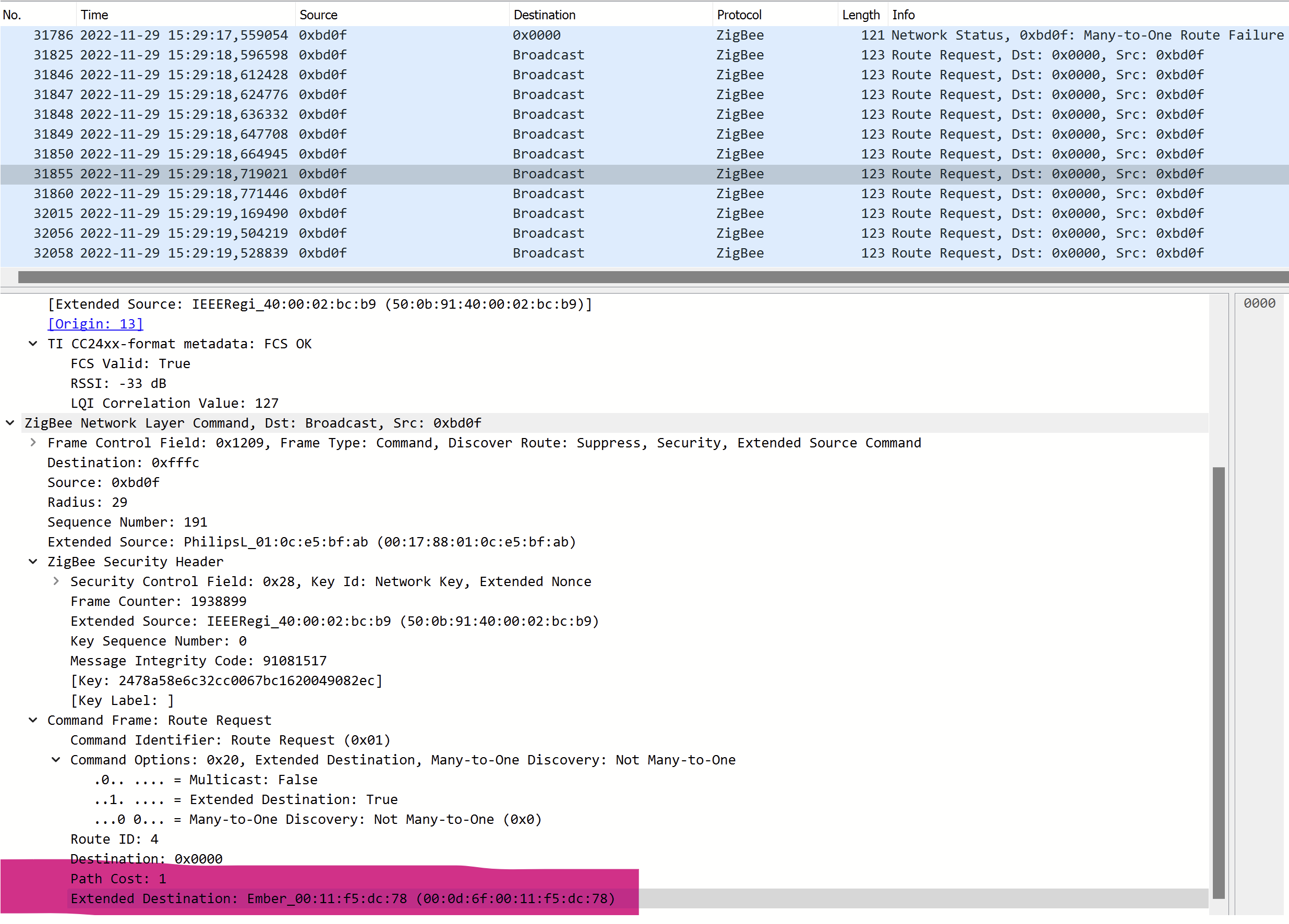
Can you post the packet # 31825 here? The route request one? And also post the IEEE address of your coordinator. The original one and the new one if you overwrote it with backup. I had some devices using incorrect coordinator IEEE address for some reason to even though it was overwritten with the new one. |
Packet # 31825Current IEEE of the coordinator
Which concord's with my original HUSBZB-1 back-up : As for the previous IEEE, do you know if we can see the one we overwritten? i didn’t take note of it. Interestingly, the network conflicts started around the first route request of 0xbd0f after some filtering. Just a word to thank you for looking into my issue. |

Yes, I did. The original IEEE should still come from an Elelabs ELU013 -> CC2652 -> ZBDongle-E.
I did get a lot of "joined the network"/"changed id" logs during the unsuccessful pairing from the video: 2022-11-28 00:55:09.902 DEBUG (MainThread) [bellows.zigbee.application] Received trustCenterJoinHandler frame with [0x1f8d, 58:8e:81:ff:fe:d3:90:2c, <EmberDeviceUpdate.STANDARD_SECURITY_UNSECURED_JOIN: 1>, <EmberJoinDecision.USE_PRECONFIGURED_KEY: 0>, 0x7866]
2022-11-28 00:55:09.902 INFO (MainThread) [zigpy.application] Device 0x1f8d (58:8e:81:ff:fe:d3:90:2c) joined the network
2022-11-28 00:55:09.902 DEBUG (MainThread) [zigpy.application] Device 58:8e:81:ff:fe:d3:90:2c changed id (0xaad7 => 0x1f8d)However, now that my network is back to running "normal" (still unable to pair devices in some places and seem to get multiple rejoins/nwk id changes in other places), I do not get any rejoins/nwk id changes during normal operation. |
|
Possibly completely unrelated but |
|
It sends the route request to destination SiliconL_ff:fe:0f:dd:1e (60:a4:23:ff:fe:0f:dd:1e) nwk id 0x0000 but the eui should be 00:0d:6f:00:11:f5:dc:78 and that's why the thermostat reports the nwk conflict. I guess the 60:a4:23:ff:fe:0f:dd:1e is the original IEEE address? I have no ideas how devices get the wind of the original IEEE. In your backup, are there any TC link keys with that IEEE? |
|
Unfortunately I have no trace of the previous IEEE address of the coordinator before I wrote on it. So I can’t know for sure it come’s from there. I've checked for that address but it doesn't appear in any backup I have made. I do still have 2 new EasyIoT I could write to if need be (and look at their IEEE address before writing 00:0d:6f:00:11:f5:dc:78 on it) but I would keep that as a last resort because i’m burning thru coordinators like crazy. 😹 I looked at my first ever back-up of my HUSBZB-1 I have : And the current EasyIoT: |
|
No, i mean the current backup of EZSP coordinator as of now? Does it have any partner eui of 60:a4:23:ff:fe:0f:dd:1e ? |
|
No, i mean the current backup of EZSP coordinator as of now? Does it have any partner eui of 60:a4:23:ff:fe:0f:dd:1e ? Or is the EasyIoT current EZSP coordinator? |
|
I was checking the ghost IEEE @mguaylam can you post the first 6 numbers (or all) of the IEEE for one or all then im interested of the chip / Zigbee stack they is using then its smells firmware bugs. |
|
@Adminiuga sorry for the confusion, my main coordinator is the EasyIoT. The Sonoff one was for testing. As for the Philips bulbs, I have quite a few, I’ll do that as soon as I can and come back to you. 😸 @MattWestb : I’m having trouble understanding you. 😢 Are you on the Discord of Home-Assistant? |
|
It could be that the Philips joined while you were running the other coordinator and it got wrong tclink key cached. |
|
@mguaylam Sorry no HA Discord :-((
This is the second track and i like to knowing if the TRVs is having "normal" firmware or some more "exotic" ones that can doing problems. |
|
So I repaired all routers of the network. At first, I could not pair anything except directly thru the coordinator but I think that’s fixed now, I had to pair directly with the coordinator or a device with the new trust center link key to make it work. I then did some tests ;
All of which used to make the thermostats think there is a network conflict and make all my lights flash. I think it’s quite an annoying feature from Philips to make lights flash that horrible pattern upon network conflicts but oh well. Interestingly it suddenly stopped when the problematic Philips Hue bulb got its proper configuration. So the issue resolved before I reset the thermostats. Not sure why since I taught they were the issue. I’m gonna hope it’s the good one. I will close this issue now in the hope I will not need to open it again. To conclude, it appears the missing trust center link key was the issue here. I’m not sure why mine disappeared since I always had one. Thanks Puddly, Adminiuga, MattWestb, TheJulianJES and Dmulcahey for the help provided in this issue here and on other platforms. It really helped! I hope you all know how your time is valued here. I hope you all have a nice day! ☀️ |
Great work done !!Keep looking in the log for routing problems and also if some end devices (sleeper or not) is having problems and can need being repaired for getting one valid TC-Link key and working 100% OK in the network. Then your backup was having TC-Link keys it was likely forming the network before ZHA was start using hashed TC-Link keys and was working OK until you was restoring one backup and some device (new added ones) was starting using hashed ones and the old not => routing and joining problems. |
The problem
Issue
Coordinator crash when a new devices joins or re-join the network.
ERROR (MainThread) [bellows.ezsp] NCP entered failed state. Requesting APP controller restartSteps to reproduce the issue
Add a new device to the network or reapply mains power to it.
Controller fails immediately. May take more or less time for Home-Assistant to be able to reset the controller. Can end up stuck indefinitely when adding a new device until it is reset. Usually helps when Home-Assistant is restarted entirely.
Effect
Philips Hue lights start a flashing patern in sync while the controler is failed. Similar with IKEA devices but stroboscopic effect.
The coordinator is not reachable thus, it is not possible to control devices.
Coordinator
Generic Aliexpress EFR32MG21 : https://www.aliexpress.com/item/1005003578599189.html?spm=a2g0o.order_list.0.0.46f01802MxU13p
Tried a different SDK version (6.7.9 : where the issue first appeared) then with a different coordinator (same chipset) with the same result. (Sonoff-E coordinator) with the https://github.com/itead/Sonoff_Zigbee_Dongle_Firmware/blob/master/Dongle-E/NCP/ncp-uart-sw_EZNet6.10.3_V1.0.1.gbl firmware.
Hue light
zha-40ddd6936d1246728ca550920844f2e9-Signify Netherlands B.V. LTA010-2f79db844541232293a51b47904435cd.json (1).txt
What version of Home Assistant Core has the issue?
core-2022.11.2
What type of installation are you running?
Home Assistant Container
Integration causing the issue
ZHA
Link to integration documentation on our website
https://www.home-assistant.io/integrations/zha/
Diagnostics information
home-assistant.log
Here’s my network backup as I wonder if something is not wrong with it :
ZHA backup 2022-11-12T16-58-07.216Z.txt
Example YAML snippet
The text was updated successfully, but these errors were encountered: