diff --git a/chapters/th/_toctree.yml b/chapters/th/_toctree.yml
index 5139c38b7..b473ea93c 100644
--- a/chapters/th/_toctree.yml
+++ b/chapters/th/_toctree.yml
@@ -104,4 +104,26 @@
title: เรียนจบเรื่อง tokenizer แล้ว!
- local: chapter6/10
title: คำถามท้ายบท
- quiz: 6
\ No newline at end of file
+ quiz: 6
+
+- title: 7. หน้าที่หลักของ NLP
+ sections:
+ - local: chapter7/1
+ title: บทนำ
+ - local: chapter7/2
+ title: การจำแนกประเภทคำ (Token classification)
+ - local: chapter7/3
+ title: การปรับแต่งโมเดลภาษา (Fine-tuning a masked language model)
+ - local: chapter7/4
+ title: การแปลความหมาย
+ - local: chapter7/5
+ title: การสรุปความหมาย (Summarization)
+ - local: chapter7/6
+ title: การเทร็นภาษาเชิงสาเหตุตั้งแต่เริ่มต้น (Training a causal language model from scratch)
+ - local: chapter7/7
+ title: การตอบคำถาม (Question answering)
+ - local: chapter7/8
+ title: การเชี่ยวชาญใน NLP
+ - local: chapter7/9
+ title: คำถามท้ายบท
+ quiz: 7
\ No newline at end of file
diff --git a/chapters/th/chapter7/1.mdx b/chapters/th/chapter7/1.mdx
new file mode 100644
index 000000000..8f4f261a5
--- /dev/null
+++ b/chapters/th/chapter7/1.mdx
@@ -0,0 +1,38 @@
+
+
+# บทนำ[[บทนำ]]
+
+
+
+ใน [บทที่ 3](/course/th/chapter3), คุณได้เห็นวิธีการปรับแต่งโมเดลสำหรับการจัดหมวดหมู่ข้อความแล้ว ในบทนี้ เราจะพูดถึงหน้าที่ NLP โดยทั่วไป ดังนี้:
+
+- การจำแนกประเภทคำ (Token classification)
+- การปรับแต่งโมเดลภาษา (Masked language modeling) เช่น BERT
+- การสรุปความหมาย (Summarization)
+- การแปลความหมาย (Translation)
+- โมเดลภาษาเชิงสาเหตุ (Causal language modeling pretraining) เช่น GPT-2
+- การตอบคำถาม (Question answering)
+
+{#if fw === 'pt'}
+
+ในการดำเนินการนี้ คุณจะต้องใช้ประโยชน์จากทุกสิ่งที่คุณได้เรียนรู้เกี่ยวกับ `Trainer` API และ 🤗 Accelerate ไลบรารี่ใน [บทที่ 3](/course/th/chapter3) ไลบรารี 🤗 ชุดข้อมูลใน [บทที่ 5](/course/th/chapter5 ) และไลบรารี 🤗 Tokenizers ใน [บทที่ 6](/course/th/chapter6) นอกจากนี้เรายังจะอัปโหลดผลลัพธ์ของเราไปยัง Model Hub เช่นเดียวกับที่เราทำใน [บทที่ 4](/course/th/chapter4) ดังนั้นนี่คือบทที่ทุกอย่างมารวมกันจริงๆ!
+
+แต่ละส่วนสามารถอ่านแยกกันได้ และจะแสดงวิธีฝึกโมเดลด้วย `Trainer` API หรือด้วยลูปการฝึกของคุณเอง โดยใช้ 🤗 Accelerate คุณสามารถข้ามส่วนใดส่วนหนึ่งและมุ่งความสนใจไปที่ส่วนที่คุณสนใจมากที่สุดได้เลย: `Trainer` API นั้นยอดเยี่ยมสำหรับการปรับแต่ง (fine-tuning) หรือฝึกฝน (training) โมเดลของคุณโดยไม่ต้องกังวลกับสิ่งที่เกิดขึ้นเบื้องหลัง ในขณะที่ลูปการฝึกฝนด้วย `Accelerate` จะช่วยให้คุณปรับแต่งส่วนใด ๆ ที่คุณต้องการได้ง่ายขึ้น
+
+{:else}
+
+ในการดำเนินการนี้ คุณจะต้องใช้ประโยชน์จากทุกสิ่งที่คุณได้เรียนรู้เกี่ยวกับโมเดลการฝึกอบรมด้วย Keras API ใน [บทที่ 3](/course/th/chapter3) ไลบรารี 🤗 ชุดข้อมูลใน [บทที่ 5](/course/th/chapter5) และ 🤗 ไลบรารี Tokenizers ใน [บทที่ 6](/course/th/chapter6) นอกจากนี้เรายังจะอัปโหลดผลลัพธ์ของเราไปยัง Model Hub เช่นเดียวกับที่เราทำใน [บทที่ 4](/course/th/chapter4) ดังนั้นนี่คือบทที่ทุกอย่างมารวมกันจริงๆ!
+
+แต่ละส่วนสามารถอ่านได้อย่างอิสระ
+
+{/if}
+
+
+
+
+หากคุณอ่านส่วนต่างๆ ตามลำดับ คุณจะสังเกตเห็นว่ามีโค้ดและข้อความค่อนข้างเหมือนกัน การทำซ้ำนี้ มีเจตนาเพื่อให้คุณสามารถเข้าไปทำงานใดๆ ที่คุณสนใจ (หรือกลับมาใหม่ทีหลัง) และค้นหาตัวอย่างการทำงานที่สมบูรณ์ได้
+
+
diff --git a/chapters/th/chapter7/2.mdx b/chapters/th/chapter7/2.mdx
new file mode 100644
index 000000000..a48fe5d31
--- /dev/null
+++ b/chapters/th/chapter7/2.mdx
@@ -0,0 +1,981 @@
+
+
+# การจำแนกประเภทคำ[[การจำแนกประเภทคำ]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+แอปพลิเคชันแรกที่เราจะสำรวจคือการจำแนกคำ งานทั่วไปนี้ครอบคลุมปัญหาใดๆ ที่สามารถกำหนดเป็น "การกำหนดป้ายกำกับให้กับแต่ละคำในประโยค" เช่น:
+
+- **Named entity recognition (NER)**: ค้นหาเอนทิตี (เช่น บุคคล สถานที่ หรือองค์กร) ในประโยค สิ่งนี้สามารถกำหนดเป็นการกำหนดป้ายกำกับให้กับแต่ละคำโดยมีหนึ่งคลาสต่อเอนทิตีและหนึ่งคลาสสำหรับ "ไม่มีเอนทิตี"
+- **Part-of-speech tagging (POS)**: ทำเครื่องหมายแต่ละคำในประโยคว่าสอดคล้องกับส่วนของคำพูด (เช่น คำนาม กริยา คำคุณศัพท์ ฯลฯ)
+- **Chunking**: ค้นหาคำ (token) ที่เป็นของเอนทิตีเดียวกัน งานนี้ (ซึ่งสามารถใช้ร่วมกับ POS หรือ NER) สามารถกำหนดเป็นป้ายกำกับ (label) เดียว (โดยปกติคือ `B-`) ให้กับคำใด ๆ ที่อยู่ที่จุดเริ่มต้นของก้อน และอีกป้ายกำกับหนึ่ง (โดยปกติคือ `I-`) ให้กับคำที่ อยู่ภายในก้อนข้อมูล และป้ายกำกับที่สาม (โดยปกติคือ `O`) ของคำที่ไม่ได้เป็นของก้อนใดก้อนหนึ่ง
+
+
+
+แน่นอนว่ามีปัญหาการจำแนกคำประเภทอื่นๆ อีกหลายประเภท นี่เป็นเพียงตัวอย่างบางส่วนเท่านั้น ในส่วนนี้ เราจะปรับแต่งโมเดล (BERT) ในงาน NER ซึ่งจะสามารถคำนวณการคาดการณ์เช่นนี้ได้:
+
+
+
+
+ +
+ +
+
+คุณค้นหาโมเดลที่เราจะฝึกและอัปโหลดไปยัง Hub และตรวจสอบการคาดการณ์อีกครั้งได้ [ที่นี่](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).
+
+## การเตรียมข้อมูล[[การเตรียมข้อมูล]]
+
+ก่อนอื่น เราต้องการชุดข้อมูลที่เหมาะสำหรับการจำแนกคำ ในส่วนนี้ เราจะใช้ [CoNLL-2003 dataset](https://huggingface.co/datasets/conll2003) ซึ่งรวบรวมข่าวจาก Reuters
+
+
+
+💡 ตราบใดที่ชุดข้อมูลของคุณประกอบด้วยข้อความที่แบ่งออกเป็นคำโดยมีป้ายกำกับที่เกี่ยวข้อง คุณจะสามารถปรับขั้นตอนการประมวลผลข้อมูลที่อธิบายไว้ที่นี่กับชุดข้อมูลของคุณเองได้ ย้อนกลับไปที่ [บทที่ 5](/course/th/chapter5) หากคุณต้องการทบทวนวิธีโหลดข้อมูลที่คุณกำหนดเองใน `ชุดข้อมูล`
+
+
+
+### The CoNLL-2003 dataset[[the-conll-2003-dataset]]
+
+ในการโหลดชุดข้อมูล CoNLL-2003 เราใช้เมธอด `load_dataset()` จากไลบรารี 🤗 ชุดข้อมูล:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("conll2003")
+```
+
+การดำเนินการนี้จะดาวน์โหลดและแคชชุดข้อมูล ดังที่เราเห็นใน [บทที่ 3](/course/th/chapter3) สำหรับชุดข้อมูล GLUE MRPC การตรวจสอบออบเจ็กต์นี้จะแสดงให้เราเห็นคอลัมน์ที่มีอยู่และการแบ่งระหว่างชุดการฝึก การตรวจสอบ และการทดสอบ:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 14041
+ })
+ validation: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3250
+ })
+ test: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3453
+ })
+})
+```
+
+โดยเฉพาะอย่างยิ่ง เราจะเห็นว่าชุดข้อมูลมีป้ายกำกับ (label) สำหรับงานสามอย่างที่เรากล่าวถึงก่อนหน้านี้: NER, POS และ chunking จะเห็นว่าความแตกต่างอย่างมากจากชุดข้อมูลอื่นๆ ก็คือข้อความที่ป้อนไม่ได้ถูกนำเสนอเป็นประโยคหรือเอกสาร แต่เป็นรายการของคำ (คอลัมน์สุดท้ายเรียกว่า `โทเค็น` แต่มีคำในแง่ที่ว่าสิ่งเหล่านี้เป็นอินพุตโทเค็นล่วงหน้าที่ยังคงต้องการ เพื่อผ่านโทเค็นไนเซอร์สำหรับโทเค็นคำย่อย)
+
+มาดูองค์ประกอบแรกของชุดการฝึกกันดีกว่า:
+
+```py
+raw_datasets["train"][0]["tokens"]
+```
+
+```python out
+['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
+```
+
+เนื่องจากเราต้องการดำเนินการจดจำเอนทิตีที่มีชื่อ เราจะดูที่แท็ก NER:
+
+```py
+raw_datasets["train"][0]["ner_tags"]
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+```
+
+สิ่งเหล่านี้คือป้ายกำกับว่าเป็นจำนวนเต็มพร้อมสำหรับการฝึก แต่ก็ไม่จำเป็นเสมอไปเมื่อเราต้องการตรวจสอบข้อมูล เช่นเดียวกับการจัดหมวดหมู่ข้อความ เราสามารถเข้าถึงความสอดคล้องระหว่างจำนวนเต็มเหล่านั้นกับชื่อป้ายกำกับได้โดยดูที่แอตทริบิวต์ `features` ของชุดข้อมูลของเรา:
+
+```py
+ner_feature = raw_datasets["train"].features["ner_tags"]
+ner_feature
+```
+
+```python out
+Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
+```
+
+ดังนั้นคอลัมน์นี้จึงมีองค์ประกอบที่เป็นลำดับของ `ClassLabel`s ประเภทขององค์ประกอบของลำดับอยู่ในแอตทริบิวต์ `feature` ของ `ner_feature` นี้ และเราสามารถเข้าถึงรายชื่อได้โดยดูที่แอตทริบิวต์ `names` ของ `feature` นั้น:
+
+```py
+label_names = ner_feature.feature.names
+label_names
+```
+
+```python out
+['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
+```
+
+เราเห็นป้ายกำกับ (label) เหล่านี้แล้วเมื่อเจาะลึกไปป์ไลน์ `การจำแนกคำ` ใน [บทที่ 6](/course/th/chapter6/3) แต่เพื่อการทบทวนอย่างรวดเร็ว:
+
+- `O` หมายความว่าคำนี้ไม่สอดคล้องกับเอนทิตีใด ๆ
+- `B-PER`/`I-PER` หมายถึงคำที่ตรงกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *บุคคล*
+- `B-ORG`/`I-ORG` หมายถึงคำที่ตรงกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *องค์กร*
+- `B-LOC`/`I-LOC` หมายถึงคำที่สอดคล้องกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *สถานที่*
+- `B-MISC`/`I-MISC` หมายถึงคำที่สอดคล้องกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *เบ็ดเตล็ด*
+
+มาดูการถอดรหัสป้ายกำกับที่เราเห็นก่อนหน้านี้ ซึ่งทำให้เราได้สิ่งนี้:
+
+```python
+words = raw_datasets["train"][0]["tokens"]
+labels = raw_datasets["train"][0]["ner_tags"]
+line1 = ""
+line2 = ""
+for word, label in zip(words, labels):
+ full_label = label_names[label]
+ max_length = max(len(word), len(full_label))
+ line1 += word + " " * (max_length - len(word) + 1)
+ line2 += full_label + " " * (max_length - len(full_label) + 1)
+
+print(line1)
+print(line2)
+```
+
+```python out
+'EU rejects German call to boycott British lamb .'
+'B-ORG O B-MISC O O O B-MISC O O'
+```
+
+และสำหรับตัวอย่างการผสมป้ายกำกับ `B-` และ `I-` นี่คือสิ่งที่โค้ดเดียวกันนี้ให้กับองค์ประกอบของชุดการฝึกที่ดัชนี 4:
+
+```python out
+'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
+'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
+```
+
+ดังที่เราเห็น เอนทิตีที่ประกอบด้วยคำสองคำ เช่น "European Union" และ "Werner Zwingmann" จะถูกจัดว่าเป็นป้ายกำกับ `B-` สำหรับคำแรก และป้ายกำกับ 'I-` สำหรับคำที่สอง
+
+
+
+✏️ **ถึงตาคุณแล้ว!** พิมพ์สองประโยคเดียวกันด้วย POS หรือป้ายกำกับแบบแยกส่วน
+
+
+
+### การประมวลผลข้อมูล[[การประมวลผลข้อมูล]]
+
+
+
+ตามปกติ ข้อความของเราต้องแปลงเป็นรหัสโทเค็นก่อนที่โมเดลจะเข้าใจได้ ดังที่เราเห็นใน [บทที่ 6](/course/th/chapter6/) ความแตกต่างที่สำคัญในกรณีของงานการจำแนกโทเค็นก็คือ เรามีอินพุตโทเค็นล่วงหน้า โชคดีที่ tokenizer API สามารถจัดการกับสิ่งนั้นได้อย่างง่ายดาย เราแค่ต้องเตือน `tokenizer` ด้วยแฟล็กพิเศษ
+
+ขั้นแรก เรามาสร้างออบเจ็กต์ `tokenizer` กัน ดังที่เราได้กล่าวไว้ก่อนหน้านี้ เราจะใช้โมเดลที่ได้รับการฝึกล่วงหน้าของ BERT ดังนั้นเราจะเริ่มต้นด้วยการดาวน์โหลดและแคชโทเค็นไนเซอร์ที่เกี่ยวข้อง:
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "bert-base-cased"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+คุณสามารถแทนที่ `model_checkpoint` ด้วยโมเดลอื่นใดก็ได้ที่คุณต้องการจาก [Hub](https://huggingface.co/models) หรือด้วยโฟลเดอร์ในเครื่องที่คุณได้บันทึกโมเดลที่ฝึกไว้ล่วงหน้าและ tokenizer. มีข้อจำกัดเพียงอย่างเดียวคือโทเค็นต้องได้รับการสนับสนุนโดยไลบรารี 🤗 Tokenizers ดังนั้นจึงมีเวอร์ชัน "fast" ให้ใช้งาน คุณสามารถดูสถาปัตยกรรมทั้งหมดที่มาพร้อมกับเวอร์ชันที่รวดเร็วได้ใน [ตารางใหญ่นี้](https://huggingface.co/transformers/#supported-frameworks) และเพื่อตรวจสอบว่าวัตถุ `tokenizer` ที่คุณใช้อยู่นั้นเป็นจริง สนับสนุนโดย 🤗 Tokenizers คุณสามารถดูแอตทริบิวต์ `is_fast` ได้:
+
+```py
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+
+หากต้องการโทเค็นอินพุตที่แปลงเป็นโทเค็นล่วงหน้า (a pre-tokenized input) เราสามารถใช้ `tokenizer` ตามปกติและเพียงเพิ่ม `is_split_into_words=True`:
+
+```py
+inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
+inputs.tokens()
+```
+
+```python out
+['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
+```
+
+ดังที่เราเห็น Tokenizer ได้เพิ่มโทเค็นพิเศษที่ใช้โดยโมเดล (`[CLS]` ที่จุดเริ่มต้นและ `[SEP]` ในตอนท้าย) และปล่อยให้คำส่วนใหญ่ไม่ถูกแตะต้อง อย่างไรก็ตาม คำว่า `lamb` ถูกแปลงเป็นคำย่อย 2 คำ คือ `la` และ `##mb` สิ่งนี้ทำให้เกิดความไม่ตรงกันระหว่างอินพุตของเราและป้ายกำกับ: รายการป้ายกำกับมีเพียง 9 องค์ประกอบ ในขณะที่อินพุตของเราตอนนี้มี 12 โทเค็น การบัญชีสำหรับโทเค็นพิเศษเป็นเรื่องง่าย (เรารู้ว่ามันอยู่ที่จุดเริ่มต้นและจุดสิ้นสุด) แต่เรายังต้องตรวจสอบให้แน่ใจด้วยว่าเราจัดตำแหน่งป้ายกำกับทั้งหมดด้วยคำที่เหมาะสม
+
+โชคดีมาก เนื่องจากเราใช้ tokenizer ที่รวดเร็ว เราจึงสามารถเข้าถึง 🤗 Tokenizers มหาอำนาจได้ ซึ่งหมายความว่าเราสามารถจับคู่โทเค็นแต่ละโทเค็นกับคำที่เกี่ยวข้องได้อย่างง่ายดาย (ดังที่เห็นใน [บทที่ 6](/course/th/chapter6/3)):
+
+```py
+inputs.word_ids()
+```
+
+```python out
+[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
+```
+
+ด้วยการทำงานเพียงเล็กน้อย เราก็สามารถขยายรายการป้ายกำกับของเราให้ตรงกับโทเค็นได้ กฎข้อแรกที่เราจะใช้คือโทเค็นพิเศษจะมีป้ายกำกับ `-100` เนื่องจากโดยค่าเริ่มต้น `-100` คือดัชนีที่ถูกละเว้นในฟังก์ชันการสูญเสีย (loss function) ที่เราจะใช้ (cross entropy) จากนั้น แต่ละโทเค็นจะมีป้ายกำกับเดียวกันกับโทเค็นที่ขึ้นต้นด้วยคำว่าอยู่ข้างใน เนื่องจากเป็นส่วนหนึ่งของเอนทิตีเดียวกัน สำหรับโทเค็นที่อยู่ในคำ แต่ไม่ใช่ที่จุดเริ่มต้น เราจะแทนที่ `B-` ด้วย `I-` (เนื่องจากโทเค็นไม่ได้ขึ้นต้นเอนทิตี):
+
+```python
+def align_labels_with_tokens(labels, word_ids):
+ new_labels = []
+ current_word = None
+ for word_id in word_ids:
+ if word_id != current_word:
+ # Start of a new word!
+ current_word = word_id
+ label = -100 if word_id is None else labels[word_id]
+ new_labels.append(label)
+ elif word_id is None:
+ # Special token
+ new_labels.append(-100)
+ else:
+ # Same word as previous token
+ label = labels[word_id]
+ # If the label is B-XXX we change it to I-XXX
+ if label % 2 == 1:
+ label += 1
+ new_labels.append(label)
+
+ return new_labels
+```
+
+เรามาลองใช้ประโยคแรกกันดีกว่า:
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+word_ids = inputs.word_ids()
+print(labels)
+print(align_labels_with_tokens(labels, word_ids))
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+```
+
+ดังที่เราเห็น ฟังก์ชั่นของเราเพิ่ม `-100` สำหรับโทเค็นพิเศษสองตัวที่จุดเริ่มต้นและจุดสิ้นสุด และ `0` ใหม่สำหรับคำของเราที่แบ่งออกเป็นสองโทเค็น
+
+
+
+✏️ **ถึงตาคุณทดลองแล้ว!** นักวิจัยบางคนชอบที่จะระบุป้ายกำกับเพียง 1 ป้ายต่อคำ และกำหนด `-100` ให้กับโทเค็นย่อยอื่นๆ ในคำที่กำหนด นี่คือการหลีกเลี่ยงคำยาวๆ ที่แบ่งออกเป็นโทเค็นย่อยจำนวนมากซึ่งมีส่วนทำให้เกิดการสูญเสียอย่างมาก เปลี่ยนฟังก์ชันก่อนหน้าเพื่อจัดแนวป้ายกำกับกับ ID อินพุตโดยปฏิบัติตามกฎนี้
+
+
+
+ในการประมวลผลชุดข้อมูลทั้งหมดของเราล่วงหน้า เราจำเป็นต้องแปลงโทเค็นอินพุตทั้งหมดและใช้ `align_labels_with_tokens()` กับป้ายกำกับทั้งหมด เพื่อใช้ประโยชน์จากความเร็วของโทเค็นเซอร์ที่รวดเร็วของเรา วิธีที่ดีที่สุดคือโทเค็นข้อความจำนวนมากในเวลาเดียวกัน ดังนั้นเราจะเขียนฟังก์ชันที่ประมวลผลรายการตัวอย่างและใช้เมธอด `Dataset.map()` พร้อมตัวเลือก `batched=True` สิ่งเดียวที่แตกต่างจากตัวอย่างก่อนหน้านี้คือฟังก์ชัน `word_ids()` จำเป็นต้องได้รับดัชนีของตัวอย่างที่เราต้องการ ID คำเมื่ออินพุตไปยังโทเค็นไนเซอร์เป็นรายการข้อความ (หรือในกรณีของเรา รายการ ของรายการคำศัพท์) เราก็เลยเพิ่มเข้าไปด้วย:
+
+```py
+def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples["tokens"], truncation=True, is_split_into_words=True
+ )
+ all_labels = examples["ner_tags"]
+ new_labels = []
+ for i, labels in enumerate(all_labels):
+ word_ids = tokenized_inputs.word_ids(i)
+ new_labels.append(align_labels_with_tokens(labels, word_ids))
+
+ tokenized_inputs["labels"] = new_labels
+ return tokenized_inputs
+```
+
+โปรดทราบว่าเรายังไม่ได้เพิ่มอินพุตของเรา เราจะดำเนินการดังกล่าวในภายหลัง เมื่อสร้างแบทช์ด้วยตัวรวบรวมข้อมูล
+
+ตอนนี้เราสามารถใช้การประมวลผลล่วงหน้าทั้งหมดนั้นในคราวเดียวกับการแยกชุดข้อมูลอื่นๆ ของเรา:
+
+```py
+tokenized_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+)
+```
+
+เราได้ทำส่วนที่ยากที่สุดแล้ว! เมื่อข้อมูลได้รับการประมวลผลล่วงหน้าแล้ว การฝึกอบรมจริงจะมีลักษณะเหมือนกับที่เราทำใน [บทที่ 3](/course/th/chapter3) มาก
+
+{#if fw === 'pt'}
+
+## ปรับแต่งโมเดลอย่างละเอียดด้วย `Trainer` API
+
+โค้ดจริงที่ใช้ `Trainer` จะเหมือนกับเมื่อก่อน การเปลี่ยนแปลงเพียงอย่างเดียวคือวิธีการจัดเรียงข้อมูลเป็นชุดและฟังก์ชันการคำนวณหน่วยเมตริก
+
+{:else}
+
+## ปรับแต่งโมเดลอย่างละเอียดด้วย Keras
+
+โค้ดจริงที่ใช้ Keras จะคล้ายกับเมื่อก่อนมาก การเปลี่ยนแปลงเพียงอย่างเดียวคือวิธีการจัดเรียงข้อมูลเป็นชุดและฟังก์ชันการคำนวณหน่วยเมตริก
+
+{/if}
+
+
+### การจัดเรียงข้อมูล[[การจัดเรียงข้อมูล]]
+
+เราไม่สามารถใช้ `DataCollatorWithPadding` เหมือนใน [บทที่ 3](/course/th/chapter3) ได้ เพราะนั่นเป็นเพียงการแพดอินพุตเท่านั้น (ID อินพุต, attention mask และ ID ประเภทโทเค็น) ในที่นี้ป้ายกำกับของเราควรได้รับการบุในลักษณะเดียวกับอินพุตเพื่อให้มีขนาดเท่ากัน โดยใช้ค่า "-100" เพื่อที่การคาดการณ์ที่เกี่ยวข้องจะถูกละเว้นในการคำนวณการสูญเสีย
+
+ทั้งหมดนี้ทำโดย [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification) เช่นเดียวกับ `DataCollatorWithPadding` จะใช้ `tokenizer` ที่ใช้ในการประมวลผลอินพุตล่วงหน้า:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(
+ tokenizer=tokenizer, return_tensors="tf"
+)
+```
+
+{/if}
+
+เพื่อทดสอบสิ่งนี้กับตัวอย่างบางส่วน เราสามารถเรียกมันในรายการตัวอย่างจากชุดการฝึกโทเค็นของเรา:
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
+batch["labels"]
+```
+
+```python out
+tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
+ [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
+```
+
+ลองเปรียบเทียบสิ่งนี้กับป้ายกำกับสำหรับองค์ประกอบที่หนึ่งและที่สองในชุดข้อมูลของเรา:
+
+```py
+for i in range(2):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+[-100, 1, 2, -100]
+```
+
+{#if fw === 'pt'}
+
+ดังที่เราเห็น ป้ายกำกับชุดที่สองได้รับการเสริมให้เท่ากับความยาวของป้ายกำกับแรกโดยใช้ "-100"
+
+{:else}
+
+เครื่องมือรวบรวมข้อมูลของเราพร้อมแล้ว! ตอนนี้เรามาใช้เพื่อสร้าง `tf.data.Dataset` ด้วยเมธอด `to_tf_dataset()` คุณยังสามารถใช้ `model.prepare_tf_dataset()` เพื่อทำสิ่งนี้โดยใช้โค้ดสำเร็จรูปน้อยลงเล็กน้อย คุณจะเห็นสิ่งนี้ในส่วนอื่นๆ บางส่วนของบทนี้
+
+```py
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=16,
+)
+
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+
+ จุดต่อไป: โมเดลนั่นเอง
+
+{/if}
+
+{#if fw === 'tf'}
+
+### การกำหนดโมเดล[[การกำหนดโมเดล]]
+
+เนื่องจากเรากำลังแก้ไขปัญหาการจำแนกโทเค็น เราจะใช้คลาส `TFAutoModelForTokenClassification` สิ่งสำคัญที่ต้องจำเมื่อกำหนดโมเดลนี้คือการส่งข้อมูลบางอย่างเกี่ยวกับจำนวนป้ายกำกับที่เรามี วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการส่งผ่านตัวเลขนั้นด้วยอาร์กิวเมนต์ `num_labels` แต่หากเราต้องการให้วิดเจ็ตการอนุมานที่ดีทำงานเหมือนกับที่เราเห็นในตอนต้นของส่วนนี้ จะเป็นการดีกว่าถ้าตั้งค่าการโต้ตอบป้ายกำกับที่ถูกต้องแทน
+
+ควรกำหนดโดยพจนานุกรม 2 ฉบับ ได้แก่ `id2label` และ `label2id` ซึ่งมีการจับคู่จาก ID ไปยัง label และในทางกลับกัน:
+
+```py
+id2label = {i: label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+ตอนนี้เราสามารถส่งต่อไปยังเมธอด `TFAutoModelForTokenClassification.from_pretrained()` ได้ และพวกมันจะถูกตั้งค่าในการกำหนดค่าของโมเดล จากนั้นจึงบันทึกและอัปโหลดไปยัง Hub อย่างเหมาะสม:
+
+```py
+from transformers import TFAutoModelForTokenClassification
+
+model = TFAutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+เช่นเดียวกับเมื่อเรากำหนด `TFAutoModelForSequenceClassification` ของเราใน [บทที่ 3](/course/th/chapter3) การสร้างแบบจำลองจะออกคำเตือนว่าน้ำหนัก (weight) บางอย่างไม่ได้ถูกใช้ (น้ำหนักจากส่วนหัวของการฝึกล่วงหน้า) และน้ำหนักอื่น ๆ บางส่วนจะถูกเตรียมใช้งานแบบสุ่ม (weight จากส่วนหัวการจัดประเภทโทเค็นใหม่) และโมเดลนี้ควรได้รับการฝึกอบรม เราจะดำเนินการดังกล่าวภายในไม่กี่นาที แต่ก่อนอื่น โปรดตรวจสอบอีกครั้งว่าโมเดลของเรามีจำนวนป้ายกำกับ (label) ที่ถูกต้อง:
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ หากคุณมีโมเดลที่มีจำนวนป้ายกำกับไม่ถูกต้อง คุณจะได้รับข้อผิดพลาดที่ไม่ชัดเจนเมื่อเรียก `model.fit()` ในภายหลัง การแก้ไขข้อบกพร่องนี้อาจสร้างความรำคาญได้ ดังนั้นโปรดตรวจสอบให้แน่ใจว่าคุณมีป้ายกำกับถึงจำนวนที่คาดไว้
+
+
+
+### การปรับแต่งโมเดล[[การปรับแต่งโมเดล]]
+
+ตอนนี้เราพร้อมที่จะฝึกโมเดลของเราแล้ว! เรายังมีงานดูแลบ้านอีกเล็กน้อยที่ต้องทำก่อน: เราควรเข้าสู่ระบบ Hugging Face และกำหนดไฮเปอร์พารามิเตอร์การฝึกอบรมของเรา หากคุณกำลังใช้งานโน้ตบุ๊ก มีฟังก์ชันอำนวยความสะดวกที่จะช่วยคุณในเรื่องนี้:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+นี่จะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองการเข้าสู่ระบบ Hugging Face ของคุณได้
+
+หากคุณไม่ได้ทำงานในโน้ตบุ๊ก เพียงพิมพ์บรรทัดต่อไปนี้ในเทอร์มินัลของคุณ:
+
+```bash
+huggingface-cli login
+```
+
+หลังจากเข้าสู่ระบบแล้ว เราก็สามารถเตรียมทุกอย่างที่จำเป็นเพื่อคอมไพล์โมเดลของเราได้ 🤗 Transformers มีฟังก์ชัน `create_optimizer()` ที่สะดวกสบาย ซึ่งจะให้เครื่องมือเพิ่มประสิทธิภาพ `AdamW` แก่คุณพร้อมการตั้งค่าที่เหมาะสมสำหรับการลดน้ำหนักและการลดอัตราการเรียนรู้ ซึ่งทั้งสองอย่างนี้จะช่วยปรับปรุงประสิทธิภาพของโมเดลของคุณเมื่อเทียบกับเครื่องมือเพิ่มประสิทธิภาพ `Adam` ในตัว :
+
+```python
+from transformers import create_optimizer
+import tensorflow as tf
+
+# Train in mixed-precision float16
+# Comment this line out if you're using a GPU that will not benefit from this
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
+# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
+# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+```
+
+โปรดทราบว่าเราไม่ได้ระบุอาร์กิวเมนต์ `loss` ให้กับ `compile()` เนื่องจากแบบจำลองสามารถคำนวณการสูญเสียภายในได้จริง หากคุณคอมไพล์โดยไม่มีการสูญเสียและระบุป้ายกำกับของคุณในพจนานุกรมอินพุต (เช่นเดียวกับที่เราทำในชุดข้อมูลของเรา) แบบจำลองจะฝึกโดยใช้การสูญเสียภายในนั้น ซึ่งจะเหมาะสมสำหรับ งานและประเภทโมเดลที่คุณเลือก
+
+ต่อไป เราจะกำหนด `PushToHubCallback` เพื่ออัปโหลดโมเดลของเราไปยัง Hub ในระหว่างการฝึก และปรับโมเดลให้เข้ากับคอลแบ็กนั้น:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+คุณสามารถระบุชื่อเต็มของพื้นที่เก็บข้อมูลที่คุณต้องการพุชด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักดันโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/bert-finetuned-ner"` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่าไว้ เช่น `"cool_huggingface_user/bert-finetuned-ner"`
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อเรียก `model.fit()` และจะต้องตั้งชื่อใหม่
+
+
+
+โปรดทราบว่าในขณะที่การฝึกเกิดขึ้น แต่ละครั้งที่มีการบันทึกโมเดล (ที่นี่ ทุก epoch) โมเดลจะถูกอัปโหลดไปยัง Hub ในเบื้องหลัง ด้วยวิธีนี้ คุณจะสามารถกลับมาฝึกต่อในเครื่องอื่นได้หากจำเป็น
+
+ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณได้ปรับแต่งโมเดลในงานจำแนกโทเค็นสำเร็จแล้ว ขอแสดงความยินดีด้วย! แต่โมเดลของเราดีจริงแค่ไหน? เราควรประเมินตัวชี้วัดบางอย่างต่อ
+
+{/if}
+
+
+### เมตริก[[เมตริก]]
+
+{#if fw === 'pt'}
+
+หากต้องการให้ `Trainer` คำนวณเมตริกทุก epoch เราจะต้องกำหนดฟังก์ชัน `compute_metrics()` ที่จะรับอาร์เรย์ของการคาดคะเนและป้ายกำกับ แล้วส่งคืนพจนานุกรมพร้อมชื่อและค่าเมตริก
+
+เฟรมเวิร์คแบบดั้งเดิมที่ใช้ในการประเมินการทำนายการจัดหมวดหมู่โทเค็นคือ [*seqeval*](https://github.com/chakki-works/seqeval) หากต้องการใช้หน่วยวัดนี้ เราต้องติดตั้งไลบรารี *seqeval* ก่อน:
+
+```py
+!pip install seqeval
+```
+
+จากนั้นเราสามารถโหลดมันผ่านฟังก์ชัน `evaluate.load()` เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3):
+
+{:else}
+
+เฟรมเวิร์คแบบดั้งเดิมที่ใช้ในการประเมินการทำนายการจัดหมวดหมู่โทเค็นคือ [*seqeval*](https://github.com/chakki-works/seqeval). หากต้องการใช้หน่วยวัดนี้ เราต้องติดตั้งไลบรารี *seqeval* ก่อน:
+
+```py
+!pip install seqeval
+```
+
+จากนั้นเราสามารถโหลดมันผ่านฟังก์ชัน `evaluate.load()` เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3):
+
+{/if}
+
+```py
+import evaluate
+
+metric = evaluate.load("seqeval")
+```
+
+เมตริกนี้ไม่ทำงานเหมือนความแม่นยำมาตรฐาน โดยจะใช้รายการป้ายกำกับเป็นสตริง ไม่ใช่จำนวนเต็ม ดังนั้นเราจะต้องถอดรหัสการคาดคะเนและป้ายกำกับทั้งหมดก่อนที่จะส่งต่อไปยังเมตริก มาดูกันว่ามันทำงานอย่างไร ขั้นแรก เราจะได้ป้ายกำกับสำหรับตัวอย่างการฝึกอบรมแรกของเรา:
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+labels = [label_names[i] for i in labels]
+labels
+```
+
+```python out
+['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
+```
+
+จากนั้นเราสามารถสร้างการคาดการณ์ปลอมสำหรับสิ่งเหล่านั้นได้โดยเพียงแค่เปลี่ยนค่าที่ดัชนี 2:
+
+```py
+predictions = labels.copy()
+predictions[2] = "O"
+metric.compute(predictions=[predictions], references=[labels])
+```
+
+โปรดทราบว่าเมตริกจะใช้รายการการคาดการณ์ (ไม่ใช่แค่รายการเดียว) และรายการป้ายกำกับ นี่คือผลลัพธ์:
+
+```python out
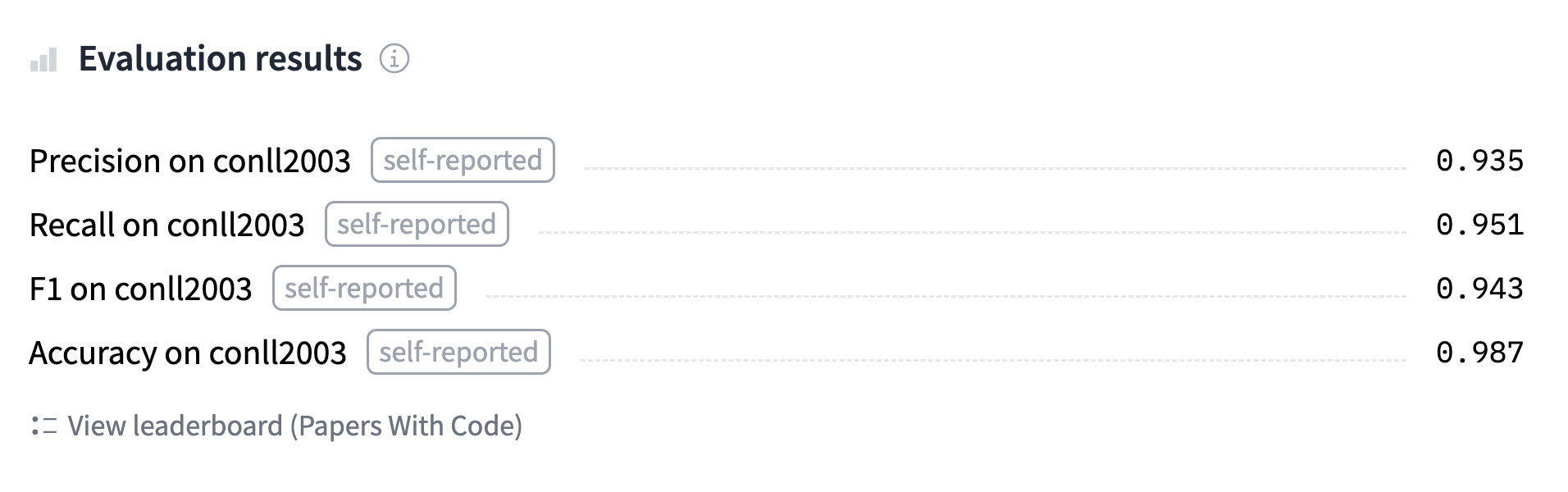
+{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
+ 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
+ 'overall_precision': 1.0,
+ 'overall_recall': 0.67,
+ 'overall_f1': 0.8,
+ 'overall_accuracy': 0.89}
+```
+
+{#if fw === 'pt'}
+
+นี่เป็นการส่งข้อมูลกลับมาจำนวนมาก! เราได้รับความแม่นยำ การเรียกคืน (recall) และคะแนน F1 สำหรับแต่ละเอนทิตีที่แยกจากกัน รวมถึงโดยรวมด้วย สำหรับการคำนวณตัวชี้วัดของเรา เราจะเก็บเฉพาะคะแนนโดยรวมเท่านั้น แต่คุณสามารถปรับแต่งฟังก์ชัน `compute_metrics()` เพื่อส่งคืนตัวชี้วัดทั้งหมดที่คุณต้องการรายงาน
+
+ฟังก์ชัน `compute_metrics()` นี้จะนำ argmax ของ logits มาแปลงเป็นการคาดการณ์ (ตามปกติ logits และความน่าจะเป็นอยู่ในลำดับเดียวกัน ดังนั้นเราจึงไม่จำเป็นต้องใช้ softmax) จากนั้นเราจะต้องแปลงทั้งป้ายกำกับและการทำนายจากจำนวนเต็มเป็นสตริง เราจะลบค่าทั้งหมดที่มีป้ายกำกับเป็น `-100` จากนั้นส่งผลลัพธ์ไปยังเมธอด `metric.compute()`:
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+
+ # Remove ignored index (special tokens) and convert to labels
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
+ return {
+ "precision": all_metrics["overall_precision"],
+ "recall": all_metrics["overall_recall"],
+ "f1": all_metrics["overall_f1"],
+ "accuracy": all_metrics["overall_accuracy"],
+ }
+```
+
+เมื่อเสร็จแล้ว เราก็เกือบจะพร้อมที่จะให้คำจำกัดความ `Trainer` ของเราแล้ว เราแค่ต้องการ `model` เพื่อปรับแต่ง!
+
+{:else}
+
+นี่เป็นการส่งข้อมูลกลับมาจำนวนมาก! เราได้รับความแม่นยำ การเรียกคืน (recall) และคะแนน F1 สำหรับแต่ละเอนทิตีที่แยกจากกัน รวมถึงโดยรวมด้วย ทีนี้มาดูว่าจะเกิดอะไรขึ้นถ้าเราลองใช้การทำนายแบบจำลองจริงเพื่อคำนวณคะแนนจริง
+
+TensorFlow ไม่ชอบการเชื่อมโยงการคาดการณ์ของเราเข้าด้วยกัน เนื่องจากมีความยาวลำดับที่แปรผันได้ ซึ่งหมายความว่าเราไม่สามารถใช้ `model.predict()` ได้เพียงอย่างเดียว -- แต่นั่นจะไม่หยุดเรา เราจะรับการคาดการณ์ทีละชุดและนำมาต่อกันเป็นรายการใหญ่ๆ รายการเดียวในระหว่างที่เราดำเนินการ โดยทิ้งโทเค็น `-100` ที่ระบุการมาสก์/การเติม จากนั้นจึงคำนวณเมตริกในรายการที่ตอนท้าย:
+
+```py
+import numpy as np
+
+all_predictions = []
+all_labels = []
+for batch in tf_eval_dataset:
+ logits = model.predict_on_batch(batch)["logits"]
+ labels = batch["labels"]
+ predictions = np.argmax(logits, axis=-1)
+ for prediction, label in zip(predictions, labels):
+ for predicted_idx, label_idx in zip(prediction, label):
+ if label_idx == -100:
+ continue
+ all_predictions.append(label_names[predicted_idx])
+ all_labels.append(label_names[label_idx])
+metric.compute(predictions=[all_predictions], references=[all_labels])
+```
+
+
+```python out
+{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
+ 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
+ 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
+ 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
+ 'overall_precision': 0.87,
+ 'overall_recall': 0.91,
+ 'overall_f1': 0.89,
+ 'overall_accuracy': 0.97}
+```
+
+โมเดลของคุณเป็นอย่างไรบ้าง เมื่อเทียบกับของเรา? หากคุณมีตัวเลขใกล้เคียงกัน แสดงว่าการฝึกของคุณสำเร็จ!
+
+{/if}
+
+{#if fw === 'pt'}
+
+### การกำหนดโมเดล[[การกำหนดโมเดล]]
+
+เนื่องจากเรากำลังแก้ไขปัญหาการจำแนกโทเค็น เราจะใช้คลาส `AutoModelForTokenClassification` สิ่งสำคัญที่ต้องจำเมื่อกำหนดโมเดลนี้คือการส่งข้อมูลบางอย่างเกี่ยวกับจำนวนป้ายกำกับที่เรามี วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการส่งผ่านตัวเลขนั้นด้วยอาร์กิวเมนต์ `num_labels` แต่หากเราต้องการให้วิดเจ็ตการอนุมานที่ดีทำงานเหมือนกับที่เราเห็นในตอนต้นของส่วนนี้ จะเป็นการดีกว่าถ้าตั้งค่าการโต้ตอบป้ายกำกับที่ถูกต้องแทน
+
+ควรกำหนดโดยพจนานุกรม 2 ฉบับ ได้แก่ `id2label` และ `label2id` ซึ่งมีการแมปจาก ID ไปยัง label และในทางกลับกัน:
+
+```py
+id2label = {i: label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+ตอนนี้เราสามารถส่งต่อไปยังเมธอด `AutoModelForTokenClassification.from_pretrained()` ได้ และพวกมันจะถูกตั้งค่าในการกำหนดค่าของโมเดล จากนั้นจึงบันทึกและอัปโหลดไปยัง Hub อย่างเหมาะสม:
+
+```py
+from transformers import AutoModelForTokenClassification
+
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+เช่นเดียวกับเมื่อเรากำหนด `AutoModelForSequenceClassification` ของเราใน [บทที่ 3](/course/th/chapter3) การสร้างแบบจำลองจะออกคำเตือนว่าน้ำหนักบางอย่างไม่ได้ถูกใช้ (น้ำหนักจากส่วนหัวของการฝึกล่วงหน้า) และน้ำหนักอื่นๆ บางส่วนจะถูกเตรียมใช้งานแบบสุ่ม (น้ำหนักนั้น จากส่วนหัวการจัดประเภทโทเค็นใหม่) และโมเดลนี้ควรได้รับการฝึกอบรม เราจะดำเนินการดังกล่าวภายในไม่กี่นาที แต่ก่อนอื่น โปรดตรวจสอบอีกครั้งว่าโมเดลของเรามีจำนวนป้ายกำกับที่ถูกต้อง:
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ หากคุณมีโมเดลที่มีจำนวนป้ายกำกับไม่ถูกต้อง คุณจะได้รับข้อผิดพลาดที่ไม่ชัดเจนเมื่อเรียกใช้เมธอด `Trainer.train()` ในภายหลัง (บางอย่างเช่น "CUDA error: device-side assert triggered") นี่คือสาเหตุอันดับหนึ่งของข้อบกพร่องที่ผู้ใช้รายงานเกี่ยวกับข้อผิดพลาดดังกล่าว ดังนั้นโปรดตรวจสอบให้แน่ใจว่าคุณได้ตรวจสอบนี้เพื่อยืนยันว่าคุณมีป้ายกำกับตามจำนวนที่คาดไว้
+
+
+
+### การปรับแต่งโมเดล[[การปรับแต่งโมเดล]]
+
+ตอนนี้เราพร้อมที่จะฝึกโมเดลของเราแล้ว! เราเพียงแค่ต้องทำสองสิ่งสุดท้ายก่อนที่เราจะกำหนด `Trainer` ของเรา: เข้าสู่ระบบ Hugging Face และกำหนดข้อโต้แย้งในการฝึกของเรา หากคุณกำลังใช้งานโน้ตบุ๊ก มีฟังก์ชันอำนวยความสะดวกที่จะช่วยคุณในเรื่องนี้:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+นี่จะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองการเข้าสู่ระบบ Hugging Face ของคุณได้
+
+หากคุณไม่ได้ทำงานในโน้ตบุ๊ก เพียงพิมพ์บรรทัดต่อไปนี้ในเทอร์มินัลของคุณ:
+
+```bash
+huggingface-cli login
+```
+
+เมื่อเสร็จแล้ว เราก็สามารถกำหนด `TrainingArguments` ของเราได้:
+
+```python
+from transformers import TrainingArguments
+
+args = TrainingArguments(
+ "bert-finetuned-ner",
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ num_train_epochs=3,
+ weight_decay=0.01,
+ push_to_hub=True,
+)
+```
+
+คุณเคยเห็นสิ่งเหล่านี้มาแล้วส่วนใหญ่: เราตั้งค่าไฮเปอร์พารามิเตอร์บางอย่าง (เช่น อัตราการเรียนรู้ จำนวน epoch ที่จะฝึก และการลดของน้ำหนัก) และเราระบุ `push_to_hub=True` เพื่อระบุว่าเราต้องการบันทึกโมเดล และประเมินผลในตอนท้ายของทุก epoch และเราต้องการอัปโหลดผลลัพธ์ของเราไปยัง Model Hub โปรดทราบว่าคุณสามารถระบุชื่อของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/bert-finetuned-ner"` ลงใน `TrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นในกรณีของเราจะเป็น `"sgugger/bert-finetuned-ner"`
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อกำหนด `Trainer` ของคุณและจะต้องตั้งชื่อใหม่
+
+
+
+ในที่สุด เราก็ส่งทุกอย่างให้กับ `Trainer` และเริ่มต้นการฝึกอบรม:
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ tokenizer=tokenizer,
+)
+trainer.train()
+```
+
+โปรดทราบว่าในขณะที่การฝึกเกิดขึ้น แต่ละครั้งที่มีการบันทึกโมเดล (ที่นี่ ทุก epoch) โมเดลจะถูกอัปโหลดไปยัง Hub ในเบื้องหลัง ด้วยวิธีนี้ คุณจะสามารถกลับมาฝึกต่อในเครื่องอื่นได้หากจำเป็น
+
+เมื่อการฝึกอบรมเสร็จสิ้น เราจะใช้เมธอด `push_to_hub()` เพื่อให้แน่ใจว่าเราจะอัปโหลดโมเดลเวอร์ชันล่าสุด:
+
+```py
+trainer.push_to_hub(commit_message="Training complete")
+```
+
+คำสั่งนี้จะส่งคืน URL ของการคอมมิตที่เพิ่งทำไป หากคุณต้องการตรวจสอบ:
+
+```python out
+'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
+```
+
+`Trainer` ยังร่างการ์ดโมเดลพร้อมผลการประเมินทั้งหมดแล้วอัปโหลด ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณได้ปรับแต่งโมเดลในงานจำแนกโทเค็นสำเร็จแล้ว ขอแสดงความยินดีด้วย!
+
+หากคุณต้องการเจาะลึกลงไปในวงจรการฝึกซ้อมอีกสักหน่อย ตอนนี้เราจะแสดงให้คุณเห็นถึงวิธีการทำสิ่งเดียวกันโดยใช้ 🤗 Accelerate
+
+## การกำหนดเทร็นนิ่งลูปเฉพาะ[[การกำหนดเทร็นนิ่งลูปเฉพาะ]]
+
+ตอนนี้เรามาดูวงจรการฝึกซ้อมทั้งหมดกัน เพื่อให้คุณปรับแต่งส่วนต่างๆ ที่ต้องการได้อย่างง่ายดาย มันจะดูเหมือนกับสิ่งที่เราทำใน [บทที่ 3](/course/th/chapter3/4) มาก โดยมีการเปลี่ยนแปลงเล็กน้อยสำหรับการประเมิน
+
+### เตรียมทุกอย่างเพื่อการฝึก[[เตรียมทุกอย่างเพื่อการฝึก]]
+
+ก่อนอื่นเราต้องสร้าง `DataLoader`s จากชุดข้อมูลของเรา เราจะใช้ `data_collator` ของเราซ้ำเป็น `collate_fn` และสับเปลี่ยนชุดการฝึก แต่ไม่ใช่ชุดการตรวจสอบ:
+
+```py
+from torch.utils.data import DataLoader
+
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+ต่อไป เราจะสร้างโมเดลของเราขึ้นมาใหม่ เพื่อให้แน่ใจว่าเราจะไม่ทำการปรับแต่งแบบละเอียดจากเมื่อก่อนต่อไป แต่เริ่มต้นจากโมเดล BERT ที่ได้รับการฝึกไว้ล่วงหน้าอีกครั้ง:
+
+```py
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+จากนั้นเราจะต้องมีเครื่องมือเพิ่มประสิทธิภาพ เราจะใช้ `AdamW` แบบคลาสสิกซึ่งคล้ายกับ 'Adam` แต่มีการแก้ไขวิธีการลดน้ำหนัก:
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+เมื่อเรามีอ็อบเจ็กต์ทั้งหมดแล้ว เราก็สามารถส่งมันไปที่เมธอด `accelerator.prepare()` ได้:
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 หากคุณกำลังฝึกบน TPU คุณจะต้องย้ายโค้ดทั้งหมดที่เริ่มต้นจากเซลล์ด้านบนไปยังฟังก์ชันการฝึกเฉพาะ ดู [บทที่ 3](/course/th/chapter3) สำหรับรายละเอียดเพิ่มเติม
+
+
+
+ตอนนี้เราได้ส่ง `train_dataloader` ไปที่ `accelerator.prepare()` แล้ว เราสามารถใช้ความยาวของมันเพื่อคำนวณจำนวนขั้นตอนการฝึกได้ โปรดจำไว้ว่าเราควรทำเช่นนี้เสมอหลังจากเตรียม dataloader เนื่องจากวิธีการนั้นจะเปลี่ยนความยาวของมัน เราใช้กำหนดการเชิงเส้นแบบคลาสสิกจากอัตราการเรียนรู้ถึง 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+สุดท้ายนี้ ในการผลักดันโมเดลของเราไปที่ Hub เราจะต้องสร้างออบเจ็กต์ `Repository` ในโฟลเดอร์ที่ใช้งานได้ ขั้นแรกให้เข้าสู่ระบบ Hugging Face หากคุณยังไม่ได้เข้าสู่ระบบ เราจะกำหนดชื่อที่เก็บจาก ID โมเดลที่เราต้องการให้กับโมเดลของเรา (อย่าลังเลที่จะแทนที่ `repo_name` ด้วยตัวเลือกของคุณเอง เพียงต้องมีชื่อผู้ใช้ของคุณ ซึ่งเป็นสิ่งที่ฟังก์ชัน `get_full_repo_name()` ทำ ):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "bert-finetuned-ner-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/bert-finetuned-ner-accelerate'
+```
+
+จากนั้นเราสามารถโคลนพื้นที่เก็บข้อมูลนั้นในโฟลเดอร์ในเครื่องได้ หากมีอยู่แล้ว โฟลเดอร์ในเครื่องนี้ควรเป็นโคลนของพื้นที่เก็บข้อมูลที่เรากำลังทำงานด้วย:
+
+```py
+output_dir = "bert-finetuned-ner-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+ตอนนี้เราสามารถอัปโหลดทุกสิ่งที่เราบันทึกไว้ใน `output_dir` ได้โดยการเรียกเมธอด `repo.push_to_hub()` ซึ่งจะช่วยให้เราอัปโหลดโมเดลระดับกลางในตอนท้ายของแต่ละ epoch ได้
+
+### ลูปการฝึกอบรม[[ลูปการฝึกอบรม]]
+
+ตอนนี้เราพร้อมที่จะเขียนลูปการฝึกอบรม (training loop) ฉบับเต็มแล้ว เพื่อให้ส่วนการประเมินง่ายขึ้น เราได้กำหนดฟังก์ชัน `postprocess()` นี้ ซึ่งใช้การคาดการณ์และป้ายกำกับและแปลงเป็นรายการสตริง เหมือนกับที่วัตถุ `เมตริก` ของเราคาดหวัง:
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.detach().cpu().clone().numpy()
+ labels = labels.detach().cpu().clone().numpy()
+
+ # Remove ignored index (special tokens) and convert to labels
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ return true_labels, true_predictions
+```
+
+จากนั้นเราก็สามารถเขียนลูปการฝึกอบรมได้ หลังจากกำหนดแถบความคืบหน้าเพื่อติดตามว่าการฝึกดำเนินไปอย่างไร ลูปจะมีสามส่วน:
+
+- การฝึกในตัวเอง ซึ่งเป็นการวนซ้ำแบบคลาสสิกบน `train_dataloader` คือการส่งต่อผ่านโมเดล จากนั้นย้อนกลับและขั้นตอนการเพิ่มประสิทธิภาพ
+- การประเมิน ซึ่งมีความแปลกใหม่หลังจากได้รับผลลัพธ์ของแบบจำลองของเราเป็นชุด: เนื่องจากกระบวนการสองกระบวนการอาจมีการเสริมอินพุตและป้ายกำกับเป็นรูปร่างที่แตกต่างกัน เราจึงจำเป็นต้องใช้ `accelerator.pad_across_processes()` เพื่อทำการคาดการณ์และ ติดป้ายกำกับรูปร่างเดียวกันก่อนที่จะเรียกเมธอด `gather()` หากเราไม่ทำเช่นนี้ การประเมินจะเกิดข้อผิดพลาดหรือหยุดทำงานตลอดไป จากนั้นเราจะส่งผลลัพธ์ไปที่ `metric.add_batch()` และเรียก `metric.compute()` เมื่อลูปการประเมินสิ้นสุดลง
+- การบันทึกและการอัปโหลด โดยที่เราจะบันทึกโมเดลและโทเค็นไนเซอร์ก่อน จากนั้นจึงเรียก `repo.push_to_hub()` โปรดสังเกตว่าเราใช้อาร์กิวเมนต์ `blocking=False` เพื่อบอกไลบรารี 🤗 Hub ให้พุชในกระบวนการอะซิงโครนัส ด้วยวิธีนี้ การฝึกอบรมจะดำเนินต่อไปตามปกติและคำสั่ง (แบบยาว) นี้จะดำเนินการในเบื้องหลัง
+
+นี่คือโค้ดที่สมบูรณ์สำหรับลูปการฝึกอบรม:
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Training
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in eval_dataloader:
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ predictions = outputs.logits.argmax(dim=-1)
+ labels = batch["labels"]
+
+ # Necessary to pad predictions and labels for being gathered
+ predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(predictions)
+ labels_gathered = accelerator.gather(labels)
+
+ true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=true_predictions, references=true_labels)
+
+ results = metric.compute()
+ print(
+ f"epoch {epoch}:",
+ {
+ key: results[f"overall_{key}"]
+ for key in ["precision", "recall", "f1", "accuracy"]
+ },
+ )
+
+ # Save and upload
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+ในกรณีที่นี่เป็นครั้งแรกที่คุณเห็นโมเดลที่บันทึกไว้ด้วย 🤗 Accelerate ลองใช้เวลาสักครู่เพื่อตรวจสอบโค้ดสามบรรทัดที่มาพร้อมกับโมเดลนั้น:
+
+```py
+accelerator.wait_for_everyone()
+unwrapped_model = accelerator.unwrap_model(model)
+unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+```
+
+บรรทัดแรกอธิบายในตัวมันเอง: มันบอกกระบวนการทั้งหมดให้รอจนกว่าทุกคนจะถึงขั้นตอนนั้นก่อนจะดำเนินการต่อ เพื่อให้แน่ใจว่าเรามีโมเดลเดียวกันในทุกกระบวนการก่อนที่จะบันทึก จากนั้นเราก็คว้า `unwrapped_model` ซึ่งเป็นโมเดลพื้นฐานที่เรากำหนดไว้ เมธอด `accelerator.prepare()` เปลี่ยนโมเดลให้ทำงานในการฝึกแบบกระจาย ดังนั้นจะไม่มีเมธอด `save_pretrained()` อีกต่อไป เมธอด `accelerator.unwrap_model()` จะยกเลิกขั้นตอนนั้น สุดท้ายนี้ เราเรียก `save_pretrained()` แต่บอกวิธีการนั้นให้ใช้ `accelerator.save()` แทน `torch.save()`
+
+เมื่อเสร็จแล้ว คุณควรมีโมเดลที่สร้างผลลัพธ์ที่ค่อนข้างคล้ายกับโมเดลที่ได้รับการฝึกกับ `Trainer` คุณสามารถตรวจสอบโมเดลที่เราฝึกได้โดยใช้โค้ดนี้ที่ [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate) และหากคุณต้องการทดสอบการปรับแต่งใดๆ ในลูปการฝึก คุณสามารถนำไปใช้ได้โดยตรงโดยแก้ไขโค้ดที่แสดงด้านบน!
+
+{/if}
+
+## การใช้โมเดลที่ปรับแต่งแล้ว[[การใช้โมเดลที่ปรับแต่งแล้ว]]
+
+เราได้แสดงให้คุณเห็นแล้วว่าคุณสามารถใช้โมเดลที่เราปรับแต่งอย่างละเอียดบน Model Hub ด้วยวิดเจ็ตการอนุมานได้อย่างไร หากต้องการใช้ภายในเครื่องใน `pipeline` คุณเพียงแค่ต้องระบุตัวระบุโมเดลที่เหมาะสม:
+
+```py
+from transformers import pipeline
+
+# Replace this with your own checkpoint
+model_checkpoint = "huggingface-course/bert-finetuned-ner"
+token_classifier = pipeline(
+ "token-classification", model=model_checkpoint, aggregation_strategy="simple"
+)
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+ยอดเยี่ยม! โมเดลของเราใช้งานได้เช่นเดียวกับโมเดลเริ่มต้นสำหรับไปป์ไลน์นี้
diff --git a/chapters/th/chapter7/3.mdx b/chapters/th/chapter7/3.mdx
new file mode 100644
index 000000000..09f657bfb
--- /dev/null
+++ b/chapters/th/chapter7/3.mdx
@@ -0,0 +1,1045 @@
+
+
+# การปรับแต่งโมเดลภาษา[[การปรับแต่งโมเดลภาษา]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+สำหรับแอปพลิเคชัน NLP จำนวนมากที่เกี่ยวข้องกับโมเดล Transformer คุณสามารถใช้โมเดลที่ได้รับการฝึกล่วงหน้าจาก Hugging Face Hub และปรับแต่งข้อมูลของคุณโดยตรงสำหรับงานที่มีอยู่ โดยมีเงื่อนไขว่าคลังข้อมูลที่ใช้สำหรับการฝึกล่วงหน้า (pretraining) ไม่แตกต่างจากคลังข้อมูลที่ใช้ในการปรับแต่งอย่างละเอียดมากนัก การเรียนรู้แบบถ่ายโอน (transfer learning) มักจะให้ผลลัพธ์ที่ดี
+
+อย่างไรก็ตาม มีบางกรณีที่คุณจะต้องปรับแต่งโมเดลภาษาในข้อมูลของคุณก่อน ก่อนที่จะฝึกหัวหน้างานเฉพาะด้าน ตัวอย่างเช่น หากชุดข้อมูลของคุณมีสัญญาทางกฎหมายหรือบทความทางวิทยาศาสตร์ โมเดล Transformer ธรรมดา เช่น BERT โดยทั่วไปจะถือว่าคำเฉพาะโดเมนในคลังข้อมูลของคุณเป็นโทเค็นที่หายาก และประสิทธิภาพผลลัพธ์ที่ได้อาจน้อยกว่าที่น่าพอใจ ด้วยการปรับแต่งโมเดลภาษาบนข้อมูลในโดเมน คุณจะเพิ่มประสิทธิภาพของงานดาวน์สตรีมหลายๆ งานได้ ซึ่งหมายความว่าโดยปกติคุณจะต้องทำขั้นตอนนี้เพียงครั้งเดียวเท่านั้น!
+
+กระบวนการปรับแต่งโมเดลภาษาที่ได้รับการฝึกล่วงหน้าอย่างละเอียดในข้อมูลในโดเมนนี้มักจะเรียกว่า _domain adaptation_ ได้รับความนิยมในปี 2018 โดย [ULMFiT](https://arxiv.org/abs/1801.06146) ซึ่งเป็นหนึ่งในสถาปัตยกรรมประสาทแรกๆ (อิงจาก LSTM) ที่ทำให้การเรียนรู้แบบถ่ายโอนใช้งานได้จริงสำหรับ NLP ตัวอย่างการปรับโดเมนด้วย ULMFiT แสดงอยู่ในภาพด้านล่าง ในส่วนนี้ เราจะทำสิ่งที่คล้ายกัน แต่ใช้ Transformer แทน LSTM!
+
+
+
+
+คุณค้นหาโมเดลที่เราจะฝึกและอัปโหลดไปยัง Hub และตรวจสอบการคาดการณ์อีกครั้งได้ [ที่นี่](https://huggingface.co/huggingface-course/bert-finetuned-ner?text=My+name+is+Sylvain+and+I+work+at+Hugging+Face+in+Brooklyn).
+
+## การเตรียมข้อมูล[[การเตรียมข้อมูล]]
+
+ก่อนอื่น เราต้องการชุดข้อมูลที่เหมาะสำหรับการจำแนกคำ ในส่วนนี้ เราจะใช้ [CoNLL-2003 dataset](https://huggingface.co/datasets/conll2003) ซึ่งรวบรวมข่าวจาก Reuters
+
+
+
+💡 ตราบใดที่ชุดข้อมูลของคุณประกอบด้วยข้อความที่แบ่งออกเป็นคำโดยมีป้ายกำกับที่เกี่ยวข้อง คุณจะสามารถปรับขั้นตอนการประมวลผลข้อมูลที่อธิบายไว้ที่นี่กับชุดข้อมูลของคุณเองได้ ย้อนกลับไปที่ [บทที่ 5](/course/th/chapter5) หากคุณต้องการทบทวนวิธีโหลดข้อมูลที่คุณกำหนดเองใน `ชุดข้อมูล`
+
+
+
+### The CoNLL-2003 dataset[[the-conll-2003-dataset]]
+
+ในการโหลดชุดข้อมูล CoNLL-2003 เราใช้เมธอด `load_dataset()` จากไลบรารี 🤗 ชุดข้อมูล:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("conll2003")
+```
+
+การดำเนินการนี้จะดาวน์โหลดและแคชชุดข้อมูล ดังที่เราเห็นใน [บทที่ 3](/course/th/chapter3) สำหรับชุดข้อมูล GLUE MRPC การตรวจสอบออบเจ็กต์นี้จะแสดงให้เราเห็นคอลัมน์ที่มีอยู่และการแบ่งระหว่างชุดการฝึก การตรวจสอบ และการทดสอบ:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 14041
+ })
+ validation: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3250
+ })
+ test: Dataset({
+ features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
+ num_rows: 3453
+ })
+})
+```
+
+โดยเฉพาะอย่างยิ่ง เราจะเห็นว่าชุดข้อมูลมีป้ายกำกับ (label) สำหรับงานสามอย่างที่เรากล่าวถึงก่อนหน้านี้: NER, POS และ chunking จะเห็นว่าความแตกต่างอย่างมากจากชุดข้อมูลอื่นๆ ก็คือข้อความที่ป้อนไม่ได้ถูกนำเสนอเป็นประโยคหรือเอกสาร แต่เป็นรายการของคำ (คอลัมน์สุดท้ายเรียกว่า `โทเค็น` แต่มีคำในแง่ที่ว่าสิ่งเหล่านี้เป็นอินพุตโทเค็นล่วงหน้าที่ยังคงต้องการ เพื่อผ่านโทเค็นไนเซอร์สำหรับโทเค็นคำย่อย)
+
+มาดูองค์ประกอบแรกของชุดการฝึกกันดีกว่า:
+
+```py
+raw_datasets["train"][0]["tokens"]
+```
+
+```python out
+['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
+```
+
+เนื่องจากเราต้องการดำเนินการจดจำเอนทิตีที่มีชื่อ เราจะดูที่แท็ก NER:
+
+```py
+raw_datasets["train"][0]["ner_tags"]
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+```
+
+สิ่งเหล่านี้คือป้ายกำกับว่าเป็นจำนวนเต็มพร้อมสำหรับการฝึก แต่ก็ไม่จำเป็นเสมอไปเมื่อเราต้องการตรวจสอบข้อมูล เช่นเดียวกับการจัดหมวดหมู่ข้อความ เราสามารถเข้าถึงความสอดคล้องระหว่างจำนวนเต็มเหล่านั้นกับชื่อป้ายกำกับได้โดยดูที่แอตทริบิวต์ `features` ของชุดข้อมูลของเรา:
+
+```py
+ner_feature = raw_datasets["train"].features["ner_tags"]
+ner_feature
+```
+
+```python out
+Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
+```
+
+ดังนั้นคอลัมน์นี้จึงมีองค์ประกอบที่เป็นลำดับของ `ClassLabel`s ประเภทขององค์ประกอบของลำดับอยู่ในแอตทริบิวต์ `feature` ของ `ner_feature` นี้ และเราสามารถเข้าถึงรายชื่อได้โดยดูที่แอตทริบิวต์ `names` ของ `feature` นั้น:
+
+```py
+label_names = ner_feature.feature.names
+label_names
+```
+
+```python out
+['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
+```
+
+เราเห็นป้ายกำกับ (label) เหล่านี้แล้วเมื่อเจาะลึกไปป์ไลน์ `การจำแนกคำ` ใน [บทที่ 6](/course/th/chapter6/3) แต่เพื่อการทบทวนอย่างรวดเร็ว:
+
+- `O` หมายความว่าคำนี้ไม่สอดคล้องกับเอนทิตีใด ๆ
+- `B-PER`/`I-PER` หมายถึงคำที่ตรงกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *บุคคล*
+- `B-ORG`/`I-ORG` หมายถึงคำที่ตรงกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *องค์กร*
+- `B-LOC`/`I-LOC` หมายถึงคำที่สอดคล้องกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *สถานที่*
+- `B-MISC`/`I-MISC` หมายถึงคำที่สอดคล้องกับจุดเริ่มต้นของ หรือ อยู่ภายในเอนทิตี *เบ็ดเตล็ด*
+
+มาดูการถอดรหัสป้ายกำกับที่เราเห็นก่อนหน้านี้ ซึ่งทำให้เราได้สิ่งนี้:
+
+```python
+words = raw_datasets["train"][0]["tokens"]
+labels = raw_datasets["train"][0]["ner_tags"]
+line1 = ""
+line2 = ""
+for word, label in zip(words, labels):
+ full_label = label_names[label]
+ max_length = max(len(word), len(full_label))
+ line1 += word + " " * (max_length - len(word) + 1)
+ line2 += full_label + " " * (max_length - len(full_label) + 1)
+
+print(line1)
+print(line2)
+```
+
+```python out
+'EU rejects German call to boycott British lamb .'
+'B-ORG O B-MISC O O O B-MISC O O'
+```
+
+และสำหรับตัวอย่างการผสมป้ายกำกับ `B-` และ `I-` นี่คือสิ่งที่โค้ดเดียวกันนี้ให้กับองค์ประกอบของชุดการฝึกที่ดัชนี 4:
+
+```python out
+'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
+'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
+```
+
+ดังที่เราเห็น เอนทิตีที่ประกอบด้วยคำสองคำ เช่น "European Union" และ "Werner Zwingmann" จะถูกจัดว่าเป็นป้ายกำกับ `B-` สำหรับคำแรก และป้ายกำกับ 'I-` สำหรับคำที่สอง
+
+
+
+✏️ **ถึงตาคุณแล้ว!** พิมพ์สองประโยคเดียวกันด้วย POS หรือป้ายกำกับแบบแยกส่วน
+
+
+
+### การประมวลผลข้อมูล[[การประมวลผลข้อมูล]]
+
+
+
+ตามปกติ ข้อความของเราต้องแปลงเป็นรหัสโทเค็นก่อนที่โมเดลจะเข้าใจได้ ดังที่เราเห็นใน [บทที่ 6](/course/th/chapter6/) ความแตกต่างที่สำคัญในกรณีของงานการจำแนกโทเค็นก็คือ เรามีอินพุตโทเค็นล่วงหน้า โชคดีที่ tokenizer API สามารถจัดการกับสิ่งนั้นได้อย่างง่ายดาย เราแค่ต้องเตือน `tokenizer` ด้วยแฟล็กพิเศษ
+
+ขั้นแรก เรามาสร้างออบเจ็กต์ `tokenizer` กัน ดังที่เราได้กล่าวไว้ก่อนหน้านี้ เราจะใช้โมเดลที่ได้รับการฝึกล่วงหน้าของ BERT ดังนั้นเราจะเริ่มต้นด้วยการดาวน์โหลดและแคชโทเค็นไนเซอร์ที่เกี่ยวข้อง:
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "bert-base-cased"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+```
+
+คุณสามารถแทนที่ `model_checkpoint` ด้วยโมเดลอื่นใดก็ได้ที่คุณต้องการจาก [Hub](https://huggingface.co/models) หรือด้วยโฟลเดอร์ในเครื่องที่คุณได้บันทึกโมเดลที่ฝึกไว้ล่วงหน้าและ tokenizer. มีข้อจำกัดเพียงอย่างเดียวคือโทเค็นต้องได้รับการสนับสนุนโดยไลบรารี 🤗 Tokenizers ดังนั้นจึงมีเวอร์ชัน "fast" ให้ใช้งาน คุณสามารถดูสถาปัตยกรรมทั้งหมดที่มาพร้อมกับเวอร์ชันที่รวดเร็วได้ใน [ตารางใหญ่นี้](https://huggingface.co/transformers/#supported-frameworks) และเพื่อตรวจสอบว่าวัตถุ `tokenizer` ที่คุณใช้อยู่นั้นเป็นจริง สนับสนุนโดย 🤗 Tokenizers คุณสามารถดูแอตทริบิวต์ `is_fast` ได้:
+
+```py
+tokenizer.is_fast
+```
+
+```python out
+True
+```
+
+หากต้องการโทเค็นอินพุตที่แปลงเป็นโทเค็นล่วงหน้า (a pre-tokenized input) เราสามารถใช้ `tokenizer` ตามปกติและเพียงเพิ่ม `is_split_into_words=True`:
+
+```py
+inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
+inputs.tokens()
+```
+
+```python out
+['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
+```
+
+ดังที่เราเห็น Tokenizer ได้เพิ่มโทเค็นพิเศษที่ใช้โดยโมเดล (`[CLS]` ที่จุดเริ่มต้นและ `[SEP]` ในตอนท้าย) และปล่อยให้คำส่วนใหญ่ไม่ถูกแตะต้อง อย่างไรก็ตาม คำว่า `lamb` ถูกแปลงเป็นคำย่อย 2 คำ คือ `la` และ `##mb` สิ่งนี้ทำให้เกิดความไม่ตรงกันระหว่างอินพุตของเราและป้ายกำกับ: รายการป้ายกำกับมีเพียง 9 องค์ประกอบ ในขณะที่อินพุตของเราตอนนี้มี 12 โทเค็น การบัญชีสำหรับโทเค็นพิเศษเป็นเรื่องง่าย (เรารู้ว่ามันอยู่ที่จุดเริ่มต้นและจุดสิ้นสุด) แต่เรายังต้องตรวจสอบให้แน่ใจด้วยว่าเราจัดตำแหน่งป้ายกำกับทั้งหมดด้วยคำที่เหมาะสม
+
+โชคดีมาก เนื่องจากเราใช้ tokenizer ที่รวดเร็ว เราจึงสามารถเข้าถึง 🤗 Tokenizers มหาอำนาจได้ ซึ่งหมายความว่าเราสามารถจับคู่โทเค็นแต่ละโทเค็นกับคำที่เกี่ยวข้องได้อย่างง่ายดาย (ดังที่เห็นใน [บทที่ 6](/course/th/chapter6/3)):
+
+```py
+inputs.word_ids()
+```
+
+```python out
+[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
+```
+
+ด้วยการทำงานเพียงเล็กน้อย เราก็สามารถขยายรายการป้ายกำกับของเราให้ตรงกับโทเค็นได้ กฎข้อแรกที่เราจะใช้คือโทเค็นพิเศษจะมีป้ายกำกับ `-100` เนื่องจากโดยค่าเริ่มต้น `-100` คือดัชนีที่ถูกละเว้นในฟังก์ชันการสูญเสีย (loss function) ที่เราจะใช้ (cross entropy) จากนั้น แต่ละโทเค็นจะมีป้ายกำกับเดียวกันกับโทเค็นที่ขึ้นต้นด้วยคำว่าอยู่ข้างใน เนื่องจากเป็นส่วนหนึ่งของเอนทิตีเดียวกัน สำหรับโทเค็นที่อยู่ในคำ แต่ไม่ใช่ที่จุดเริ่มต้น เราจะแทนที่ `B-` ด้วย `I-` (เนื่องจากโทเค็นไม่ได้ขึ้นต้นเอนทิตี):
+
+```python
+def align_labels_with_tokens(labels, word_ids):
+ new_labels = []
+ current_word = None
+ for word_id in word_ids:
+ if word_id != current_word:
+ # Start of a new word!
+ current_word = word_id
+ label = -100 if word_id is None else labels[word_id]
+ new_labels.append(label)
+ elif word_id is None:
+ # Special token
+ new_labels.append(-100)
+ else:
+ # Same word as previous token
+ label = labels[word_id]
+ # If the label is B-XXX we change it to I-XXX
+ if label % 2 == 1:
+ label += 1
+ new_labels.append(label)
+
+ return new_labels
+```
+
+เรามาลองใช้ประโยคแรกกันดีกว่า:
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+word_ids = inputs.word_ids()
+print(labels)
+print(align_labels_with_tokens(labels, word_ids))
+```
+
+```python out
+[3, 0, 7, 0, 0, 0, 7, 0, 0]
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+```
+
+ดังที่เราเห็น ฟังก์ชั่นของเราเพิ่ม `-100` สำหรับโทเค็นพิเศษสองตัวที่จุดเริ่มต้นและจุดสิ้นสุด และ `0` ใหม่สำหรับคำของเราที่แบ่งออกเป็นสองโทเค็น
+
+
+
+✏️ **ถึงตาคุณทดลองแล้ว!** นักวิจัยบางคนชอบที่จะระบุป้ายกำกับเพียง 1 ป้ายต่อคำ และกำหนด `-100` ให้กับโทเค็นย่อยอื่นๆ ในคำที่กำหนด นี่คือการหลีกเลี่ยงคำยาวๆ ที่แบ่งออกเป็นโทเค็นย่อยจำนวนมากซึ่งมีส่วนทำให้เกิดการสูญเสียอย่างมาก เปลี่ยนฟังก์ชันก่อนหน้าเพื่อจัดแนวป้ายกำกับกับ ID อินพุตโดยปฏิบัติตามกฎนี้
+
+
+
+ในการประมวลผลชุดข้อมูลทั้งหมดของเราล่วงหน้า เราจำเป็นต้องแปลงโทเค็นอินพุตทั้งหมดและใช้ `align_labels_with_tokens()` กับป้ายกำกับทั้งหมด เพื่อใช้ประโยชน์จากความเร็วของโทเค็นเซอร์ที่รวดเร็วของเรา วิธีที่ดีที่สุดคือโทเค็นข้อความจำนวนมากในเวลาเดียวกัน ดังนั้นเราจะเขียนฟังก์ชันที่ประมวลผลรายการตัวอย่างและใช้เมธอด `Dataset.map()` พร้อมตัวเลือก `batched=True` สิ่งเดียวที่แตกต่างจากตัวอย่างก่อนหน้านี้คือฟังก์ชัน `word_ids()` จำเป็นต้องได้รับดัชนีของตัวอย่างที่เราต้องการ ID คำเมื่ออินพุตไปยังโทเค็นไนเซอร์เป็นรายการข้อความ (หรือในกรณีของเรา รายการ ของรายการคำศัพท์) เราก็เลยเพิ่มเข้าไปด้วย:
+
+```py
+def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples["tokens"], truncation=True, is_split_into_words=True
+ )
+ all_labels = examples["ner_tags"]
+ new_labels = []
+ for i, labels in enumerate(all_labels):
+ word_ids = tokenized_inputs.word_ids(i)
+ new_labels.append(align_labels_with_tokens(labels, word_ids))
+
+ tokenized_inputs["labels"] = new_labels
+ return tokenized_inputs
+```
+
+โปรดทราบว่าเรายังไม่ได้เพิ่มอินพุตของเรา เราจะดำเนินการดังกล่าวในภายหลัง เมื่อสร้างแบทช์ด้วยตัวรวบรวมข้อมูล
+
+ตอนนี้เราสามารถใช้การประมวลผลล่วงหน้าทั้งหมดนั้นในคราวเดียวกับการแยกชุดข้อมูลอื่นๆ ของเรา:
+
+```py
+tokenized_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+)
+```
+
+เราได้ทำส่วนที่ยากที่สุดแล้ว! เมื่อข้อมูลได้รับการประมวลผลล่วงหน้าแล้ว การฝึกอบรมจริงจะมีลักษณะเหมือนกับที่เราทำใน [บทที่ 3](/course/th/chapter3) มาก
+
+{#if fw === 'pt'}
+
+## ปรับแต่งโมเดลอย่างละเอียดด้วย `Trainer` API
+
+โค้ดจริงที่ใช้ `Trainer` จะเหมือนกับเมื่อก่อน การเปลี่ยนแปลงเพียงอย่างเดียวคือวิธีการจัดเรียงข้อมูลเป็นชุดและฟังก์ชันการคำนวณหน่วยเมตริก
+
+{:else}
+
+## ปรับแต่งโมเดลอย่างละเอียดด้วย Keras
+
+โค้ดจริงที่ใช้ Keras จะคล้ายกับเมื่อก่อนมาก การเปลี่ยนแปลงเพียงอย่างเดียวคือวิธีการจัดเรียงข้อมูลเป็นชุดและฟังก์ชันการคำนวณหน่วยเมตริก
+
+{/if}
+
+
+### การจัดเรียงข้อมูล[[การจัดเรียงข้อมูล]]
+
+เราไม่สามารถใช้ `DataCollatorWithPadding` เหมือนใน [บทที่ 3](/course/th/chapter3) ได้ เพราะนั่นเป็นเพียงการแพดอินพุตเท่านั้น (ID อินพุต, attention mask และ ID ประเภทโทเค็น) ในที่นี้ป้ายกำกับของเราควรได้รับการบุในลักษณะเดียวกับอินพุตเพื่อให้มีขนาดเท่ากัน โดยใช้ค่า "-100" เพื่อที่การคาดการณ์ที่เกี่ยวข้องจะถูกละเว้นในการคำนวณการสูญเสีย
+
+ทั้งหมดนี้ทำโดย [`DataCollatorForTokenClassification`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorfortokenclassification) เช่นเดียวกับ `DataCollatorWithPadding` จะใช้ `tokenizer` ที่ใช้ในการประมวลผลอินพุตล่วงหน้า:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForTokenClassification
+
+data_collator = DataCollatorForTokenClassification(
+ tokenizer=tokenizer, return_tensors="tf"
+)
+```
+
+{/if}
+
+เพื่อทดสอบสิ่งนี้กับตัวอย่างบางส่วน เราสามารถเรียกมันในรายการตัวอย่างจากชุดการฝึกโทเค็นของเรา:
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
+batch["labels"]
+```
+
+```python out
+tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
+ [-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
+```
+
+ลองเปรียบเทียบสิ่งนี้กับป้ายกำกับสำหรับองค์ประกอบที่หนึ่งและที่สองในชุดข้อมูลของเรา:
+
+```py
+for i in range(2):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
+[-100, 1, 2, -100]
+```
+
+{#if fw === 'pt'}
+
+ดังที่เราเห็น ป้ายกำกับชุดที่สองได้รับการเสริมให้เท่ากับความยาวของป้ายกำกับแรกโดยใช้ "-100"
+
+{:else}
+
+เครื่องมือรวบรวมข้อมูลของเราพร้อมแล้ว! ตอนนี้เรามาใช้เพื่อสร้าง `tf.data.Dataset` ด้วยเมธอด `to_tf_dataset()` คุณยังสามารถใช้ `model.prepare_tf_dataset()` เพื่อทำสิ่งนี้โดยใช้โค้ดสำเร็จรูปน้อยลงเล็กน้อย คุณจะเห็นสิ่งนี้ในส่วนอื่นๆ บางส่วนของบทนี้
+
+```py
+tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=16,
+)
+
+tf_eval_dataset = tokenized_datasets["validation"].to_tf_dataset(
+ columns=["attention_mask", "input_ids", "labels", "token_type_ids"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+
+ จุดต่อไป: โมเดลนั่นเอง
+
+{/if}
+
+{#if fw === 'tf'}
+
+### การกำหนดโมเดล[[การกำหนดโมเดล]]
+
+เนื่องจากเรากำลังแก้ไขปัญหาการจำแนกโทเค็น เราจะใช้คลาส `TFAutoModelForTokenClassification` สิ่งสำคัญที่ต้องจำเมื่อกำหนดโมเดลนี้คือการส่งข้อมูลบางอย่างเกี่ยวกับจำนวนป้ายกำกับที่เรามี วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการส่งผ่านตัวเลขนั้นด้วยอาร์กิวเมนต์ `num_labels` แต่หากเราต้องการให้วิดเจ็ตการอนุมานที่ดีทำงานเหมือนกับที่เราเห็นในตอนต้นของส่วนนี้ จะเป็นการดีกว่าถ้าตั้งค่าการโต้ตอบป้ายกำกับที่ถูกต้องแทน
+
+ควรกำหนดโดยพจนานุกรม 2 ฉบับ ได้แก่ `id2label` และ `label2id` ซึ่งมีการจับคู่จาก ID ไปยัง label และในทางกลับกัน:
+
+```py
+id2label = {i: label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+ตอนนี้เราสามารถส่งต่อไปยังเมธอด `TFAutoModelForTokenClassification.from_pretrained()` ได้ และพวกมันจะถูกตั้งค่าในการกำหนดค่าของโมเดล จากนั้นจึงบันทึกและอัปโหลดไปยัง Hub อย่างเหมาะสม:
+
+```py
+from transformers import TFAutoModelForTokenClassification
+
+model = TFAutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+เช่นเดียวกับเมื่อเรากำหนด `TFAutoModelForSequenceClassification` ของเราใน [บทที่ 3](/course/th/chapter3) การสร้างแบบจำลองจะออกคำเตือนว่าน้ำหนัก (weight) บางอย่างไม่ได้ถูกใช้ (น้ำหนักจากส่วนหัวของการฝึกล่วงหน้า) และน้ำหนักอื่น ๆ บางส่วนจะถูกเตรียมใช้งานแบบสุ่ม (weight จากส่วนหัวการจัดประเภทโทเค็นใหม่) และโมเดลนี้ควรได้รับการฝึกอบรม เราจะดำเนินการดังกล่าวภายในไม่กี่นาที แต่ก่อนอื่น โปรดตรวจสอบอีกครั้งว่าโมเดลของเรามีจำนวนป้ายกำกับ (label) ที่ถูกต้อง:
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ หากคุณมีโมเดลที่มีจำนวนป้ายกำกับไม่ถูกต้อง คุณจะได้รับข้อผิดพลาดที่ไม่ชัดเจนเมื่อเรียก `model.fit()` ในภายหลัง การแก้ไขข้อบกพร่องนี้อาจสร้างความรำคาญได้ ดังนั้นโปรดตรวจสอบให้แน่ใจว่าคุณมีป้ายกำกับถึงจำนวนที่คาดไว้
+
+
+
+### การปรับแต่งโมเดล[[การปรับแต่งโมเดล]]
+
+ตอนนี้เราพร้อมที่จะฝึกโมเดลของเราแล้ว! เรายังมีงานดูแลบ้านอีกเล็กน้อยที่ต้องทำก่อน: เราควรเข้าสู่ระบบ Hugging Face และกำหนดไฮเปอร์พารามิเตอร์การฝึกอบรมของเรา หากคุณกำลังใช้งานโน้ตบุ๊ก มีฟังก์ชันอำนวยความสะดวกที่จะช่วยคุณในเรื่องนี้:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+นี่จะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองการเข้าสู่ระบบ Hugging Face ของคุณได้
+
+หากคุณไม่ได้ทำงานในโน้ตบุ๊ก เพียงพิมพ์บรรทัดต่อไปนี้ในเทอร์มินัลของคุณ:
+
+```bash
+huggingface-cli login
+```
+
+หลังจากเข้าสู่ระบบแล้ว เราก็สามารถเตรียมทุกอย่างที่จำเป็นเพื่อคอมไพล์โมเดลของเราได้ 🤗 Transformers มีฟังก์ชัน `create_optimizer()` ที่สะดวกสบาย ซึ่งจะให้เครื่องมือเพิ่มประสิทธิภาพ `AdamW` แก่คุณพร้อมการตั้งค่าที่เหมาะสมสำหรับการลดน้ำหนักและการลดอัตราการเรียนรู้ ซึ่งทั้งสองอย่างนี้จะช่วยปรับปรุงประสิทธิภาพของโมเดลของคุณเมื่อเทียบกับเครื่องมือเพิ่มประสิทธิภาพ `Adam` ในตัว :
+
+```python
+from transformers import create_optimizer
+import tensorflow as tf
+
+# Train in mixed-precision float16
+# Comment this line out if you're using a GPU that will not benefit from this
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
+# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
+# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+```
+
+โปรดทราบว่าเราไม่ได้ระบุอาร์กิวเมนต์ `loss` ให้กับ `compile()` เนื่องจากแบบจำลองสามารถคำนวณการสูญเสียภายในได้จริง หากคุณคอมไพล์โดยไม่มีการสูญเสียและระบุป้ายกำกับของคุณในพจนานุกรมอินพุต (เช่นเดียวกับที่เราทำในชุดข้อมูลของเรา) แบบจำลองจะฝึกโดยใช้การสูญเสียภายในนั้น ซึ่งจะเหมาะสมสำหรับ งานและประเภทโมเดลที่คุณเลือก
+
+ต่อไป เราจะกำหนด `PushToHubCallback` เพื่ออัปโหลดโมเดลของเราไปยัง Hub ในระหว่างการฝึก และปรับโมเดลให้เข้ากับคอลแบ็กนั้น:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(output_dir="bert-finetuned-ner", tokenizer=tokenizer)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+คุณสามารถระบุชื่อเต็มของพื้นที่เก็บข้อมูลที่คุณต้องการพุชด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักดันโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/bert-finetuned-ner"` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่าไว้ เช่น `"cool_huggingface_user/bert-finetuned-ner"`
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อเรียก `model.fit()` และจะต้องตั้งชื่อใหม่
+
+
+
+โปรดทราบว่าในขณะที่การฝึกเกิดขึ้น แต่ละครั้งที่มีการบันทึกโมเดล (ที่นี่ ทุก epoch) โมเดลจะถูกอัปโหลดไปยัง Hub ในเบื้องหลัง ด้วยวิธีนี้ คุณจะสามารถกลับมาฝึกต่อในเครื่องอื่นได้หากจำเป็น
+
+ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณได้ปรับแต่งโมเดลในงานจำแนกโทเค็นสำเร็จแล้ว ขอแสดงความยินดีด้วย! แต่โมเดลของเราดีจริงแค่ไหน? เราควรประเมินตัวชี้วัดบางอย่างต่อ
+
+{/if}
+
+
+### เมตริก[[เมตริก]]
+
+{#if fw === 'pt'}
+
+หากต้องการให้ `Trainer` คำนวณเมตริกทุก epoch เราจะต้องกำหนดฟังก์ชัน `compute_metrics()` ที่จะรับอาร์เรย์ของการคาดคะเนและป้ายกำกับ แล้วส่งคืนพจนานุกรมพร้อมชื่อและค่าเมตริก
+
+เฟรมเวิร์คแบบดั้งเดิมที่ใช้ในการประเมินการทำนายการจัดหมวดหมู่โทเค็นคือ [*seqeval*](https://github.com/chakki-works/seqeval) หากต้องการใช้หน่วยวัดนี้ เราต้องติดตั้งไลบรารี *seqeval* ก่อน:
+
+```py
+!pip install seqeval
+```
+
+จากนั้นเราสามารถโหลดมันผ่านฟังก์ชัน `evaluate.load()` เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3):
+
+{:else}
+
+เฟรมเวิร์คแบบดั้งเดิมที่ใช้ในการประเมินการทำนายการจัดหมวดหมู่โทเค็นคือ [*seqeval*](https://github.com/chakki-works/seqeval). หากต้องการใช้หน่วยวัดนี้ เราต้องติดตั้งไลบรารี *seqeval* ก่อน:
+
+```py
+!pip install seqeval
+```
+
+จากนั้นเราสามารถโหลดมันผ่านฟังก์ชัน `evaluate.load()` เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3):
+
+{/if}
+
+```py
+import evaluate
+
+metric = evaluate.load("seqeval")
+```
+
+เมตริกนี้ไม่ทำงานเหมือนความแม่นยำมาตรฐาน โดยจะใช้รายการป้ายกำกับเป็นสตริง ไม่ใช่จำนวนเต็ม ดังนั้นเราจะต้องถอดรหัสการคาดคะเนและป้ายกำกับทั้งหมดก่อนที่จะส่งต่อไปยังเมตริก มาดูกันว่ามันทำงานอย่างไร ขั้นแรก เราจะได้ป้ายกำกับสำหรับตัวอย่างการฝึกอบรมแรกของเรา:
+
+```py
+labels = raw_datasets["train"][0]["ner_tags"]
+labels = [label_names[i] for i in labels]
+labels
+```
+
+```python out
+['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
+```
+
+จากนั้นเราสามารถสร้างการคาดการณ์ปลอมสำหรับสิ่งเหล่านั้นได้โดยเพียงแค่เปลี่ยนค่าที่ดัชนี 2:
+
+```py
+predictions = labels.copy()
+predictions[2] = "O"
+metric.compute(predictions=[predictions], references=[labels])
+```
+
+โปรดทราบว่าเมตริกจะใช้รายการการคาดการณ์ (ไม่ใช่แค่รายการเดียว) และรายการป้ายกำกับ นี่คือผลลัพธ์:
+
+```python out
+{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
+ 'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
+ 'overall_precision': 1.0,
+ 'overall_recall': 0.67,
+ 'overall_f1': 0.8,
+ 'overall_accuracy': 0.89}
+```
+
+{#if fw === 'pt'}
+
+นี่เป็นการส่งข้อมูลกลับมาจำนวนมาก! เราได้รับความแม่นยำ การเรียกคืน (recall) และคะแนน F1 สำหรับแต่ละเอนทิตีที่แยกจากกัน รวมถึงโดยรวมด้วย สำหรับการคำนวณตัวชี้วัดของเรา เราจะเก็บเฉพาะคะแนนโดยรวมเท่านั้น แต่คุณสามารถปรับแต่งฟังก์ชัน `compute_metrics()` เพื่อส่งคืนตัวชี้วัดทั้งหมดที่คุณต้องการรายงาน
+
+ฟังก์ชัน `compute_metrics()` นี้จะนำ argmax ของ logits มาแปลงเป็นการคาดการณ์ (ตามปกติ logits และความน่าจะเป็นอยู่ในลำดับเดียวกัน ดังนั้นเราจึงไม่จำเป็นต้องใช้ softmax) จากนั้นเราจะต้องแปลงทั้งป้ายกำกับและการทำนายจากจำนวนเต็มเป็นสตริง เราจะลบค่าทั้งหมดที่มีป้ายกำกับเป็น `-100` จากนั้นส่งผลลัพธ์ไปยังเมธอด `metric.compute()`:
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ logits, labels = eval_preds
+ predictions = np.argmax(logits, axis=-1)
+
+ # Remove ignored index (special tokens) and convert to labels
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
+ return {
+ "precision": all_metrics["overall_precision"],
+ "recall": all_metrics["overall_recall"],
+ "f1": all_metrics["overall_f1"],
+ "accuracy": all_metrics["overall_accuracy"],
+ }
+```
+
+เมื่อเสร็จแล้ว เราก็เกือบจะพร้อมที่จะให้คำจำกัดความ `Trainer` ของเราแล้ว เราแค่ต้องการ `model` เพื่อปรับแต่ง!
+
+{:else}
+
+นี่เป็นการส่งข้อมูลกลับมาจำนวนมาก! เราได้รับความแม่นยำ การเรียกคืน (recall) และคะแนน F1 สำหรับแต่ละเอนทิตีที่แยกจากกัน รวมถึงโดยรวมด้วย ทีนี้มาดูว่าจะเกิดอะไรขึ้นถ้าเราลองใช้การทำนายแบบจำลองจริงเพื่อคำนวณคะแนนจริง
+
+TensorFlow ไม่ชอบการเชื่อมโยงการคาดการณ์ของเราเข้าด้วยกัน เนื่องจากมีความยาวลำดับที่แปรผันได้ ซึ่งหมายความว่าเราไม่สามารถใช้ `model.predict()` ได้เพียงอย่างเดียว -- แต่นั่นจะไม่หยุดเรา เราจะรับการคาดการณ์ทีละชุดและนำมาต่อกันเป็นรายการใหญ่ๆ รายการเดียวในระหว่างที่เราดำเนินการ โดยทิ้งโทเค็น `-100` ที่ระบุการมาสก์/การเติม จากนั้นจึงคำนวณเมตริกในรายการที่ตอนท้าย:
+
+```py
+import numpy as np
+
+all_predictions = []
+all_labels = []
+for batch in tf_eval_dataset:
+ logits = model.predict_on_batch(batch)["logits"]
+ labels = batch["labels"]
+ predictions = np.argmax(logits, axis=-1)
+ for prediction, label in zip(predictions, labels):
+ for predicted_idx, label_idx in zip(prediction, label):
+ if label_idx == -100:
+ continue
+ all_predictions.append(label_names[predicted_idx])
+ all_labels.append(label_names[label_idx])
+metric.compute(predictions=[all_predictions], references=[all_labels])
+```
+
+
+```python out
+{'LOC': {'precision': 0.91, 'recall': 0.92, 'f1': 0.91, 'number': 1668},
+ 'MISC': {'precision': 0.70, 'recall': 0.79, 'f1': 0.74, 'number': 702},
+ 'ORG': {'precision': 0.85, 'recall': 0.90, 'f1': 0.88, 'number': 1661},
+ 'PER': {'precision': 0.95, 'recall': 0.95, 'f1': 0.95, 'number': 1617},
+ 'overall_precision': 0.87,
+ 'overall_recall': 0.91,
+ 'overall_f1': 0.89,
+ 'overall_accuracy': 0.97}
+```
+
+โมเดลของคุณเป็นอย่างไรบ้าง เมื่อเทียบกับของเรา? หากคุณมีตัวเลขใกล้เคียงกัน แสดงว่าการฝึกของคุณสำเร็จ!
+
+{/if}
+
+{#if fw === 'pt'}
+
+### การกำหนดโมเดล[[การกำหนดโมเดล]]
+
+เนื่องจากเรากำลังแก้ไขปัญหาการจำแนกโทเค็น เราจะใช้คลาส `AutoModelForTokenClassification` สิ่งสำคัญที่ต้องจำเมื่อกำหนดโมเดลนี้คือการส่งข้อมูลบางอย่างเกี่ยวกับจำนวนป้ายกำกับที่เรามี วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการส่งผ่านตัวเลขนั้นด้วยอาร์กิวเมนต์ `num_labels` แต่หากเราต้องการให้วิดเจ็ตการอนุมานที่ดีทำงานเหมือนกับที่เราเห็นในตอนต้นของส่วนนี้ จะเป็นการดีกว่าถ้าตั้งค่าการโต้ตอบป้ายกำกับที่ถูกต้องแทน
+
+ควรกำหนดโดยพจนานุกรม 2 ฉบับ ได้แก่ `id2label` และ `label2id` ซึ่งมีการแมปจาก ID ไปยัง label และในทางกลับกัน:
+
+```py
+id2label = {i: label for i, label in enumerate(label_names)}
+label2id = {v: k for k, v in id2label.items()}
+```
+
+ตอนนี้เราสามารถส่งต่อไปยังเมธอด `AutoModelForTokenClassification.from_pretrained()` ได้ และพวกมันจะถูกตั้งค่าในการกำหนดค่าของโมเดล จากนั้นจึงบันทึกและอัปโหลดไปยัง Hub อย่างเหมาะสม:
+
+```py
+from transformers import AutoModelForTokenClassification
+
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+เช่นเดียวกับเมื่อเรากำหนด `AutoModelForSequenceClassification` ของเราใน [บทที่ 3](/course/th/chapter3) การสร้างแบบจำลองจะออกคำเตือนว่าน้ำหนักบางอย่างไม่ได้ถูกใช้ (น้ำหนักจากส่วนหัวของการฝึกล่วงหน้า) และน้ำหนักอื่นๆ บางส่วนจะถูกเตรียมใช้งานแบบสุ่ม (น้ำหนักนั้น จากส่วนหัวการจัดประเภทโทเค็นใหม่) และโมเดลนี้ควรได้รับการฝึกอบรม เราจะดำเนินการดังกล่าวภายในไม่กี่นาที แต่ก่อนอื่น โปรดตรวจสอบอีกครั้งว่าโมเดลของเรามีจำนวนป้ายกำกับที่ถูกต้อง:
+
+```python
+model.config.num_labels
+```
+
+```python out
+9
+```
+
+
+
+⚠️ หากคุณมีโมเดลที่มีจำนวนป้ายกำกับไม่ถูกต้อง คุณจะได้รับข้อผิดพลาดที่ไม่ชัดเจนเมื่อเรียกใช้เมธอด `Trainer.train()` ในภายหลัง (บางอย่างเช่น "CUDA error: device-side assert triggered") นี่คือสาเหตุอันดับหนึ่งของข้อบกพร่องที่ผู้ใช้รายงานเกี่ยวกับข้อผิดพลาดดังกล่าว ดังนั้นโปรดตรวจสอบให้แน่ใจว่าคุณได้ตรวจสอบนี้เพื่อยืนยันว่าคุณมีป้ายกำกับตามจำนวนที่คาดไว้
+
+
+
+### การปรับแต่งโมเดล[[การปรับแต่งโมเดล]]
+
+ตอนนี้เราพร้อมที่จะฝึกโมเดลของเราแล้ว! เราเพียงแค่ต้องทำสองสิ่งสุดท้ายก่อนที่เราจะกำหนด `Trainer` ของเรา: เข้าสู่ระบบ Hugging Face และกำหนดข้อโต้แย้งในการฝึกของเรา หากคุณกำลังใช้งานโน้ตบุ๊ก มีฟังก์ชันอำนวยความสะดวกที่จะช่วยคุณในเรื่องนี้:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+นี่จะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองการเข้าสู่ระบบ Hugging Face ของคุณได้
+
+หากคุณไม่ได้ทำงานในโน้ตบุ๊ก เพียงพิมพ์บรรทัดต่อไปนี้ในเทอร์มินัลของคุณ:
+
+```bash
+huggingface-cli login
+```
+
+เมื่อเสร็จแล้ว เราก็สามารถกำหนด `TrainingArguments` ของเราได้:
+
+```python
+from transformers import TrainingArguments
+
+args = TrainingArguments(
+ "bert-finetuned-ner",
+ evaluation_strategy="epoch",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ num_train_epochs=3,
+ weight_decay=0.01,
+ push_to_hub=True,
+)
+```
+
+คุณเคยเห็นสิ่งเหล่านี้มาแล้วส่วนใหญ่: เราตั้งค่าไฮเปอร์พารามิเตอร์บางอย่าง (เช่น อัตราการเรียนรู้ จำนวน epoch ที่จะฝึก และการลดของน้ำหนัก) และเราระบุ `push_to_hub=True` เพื่อระบุว่าเราต้องการบันทึกโมเดล และประเมินผลในตอนท้ายของทุก epoch และเราต้องการอัปโหลดผลลัพธ์ของเราไปยัง Model Hub โปรดทราบว่าคุณสามารถระบุชื่อของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/bert-finetuned-ner"` ลงใน `TrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นในกรณีของเราจะเป็น `"sgugger/bert-finetuned-ner"`
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อกำหนด `Trainer` ของคุณและจะต้องตั้งชื่อใหม่
+
+
+
+ในที่สุด เราก็ส่งทุกอย่างให้กับ `Trainer` และเริ่มต้นการฝึกอบรม:
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ tokenizer=tokenizer,
+)
+trainer.train()
+```
+
+โปรดทราบว่าในขณะที่การฝึกเกิดขึ้น แต่ละครั้งที่มีการบันทึกโมเดล (ที่นี่ ทุก epoch) โมเดลจะถูกอัปโหลดไปยัง Hub ในเบื้องหลัง ด้วยวิธีนี้ คุณจะสามารถกลับมาฝึกต่อในเครื่องอื่นได้หากจำเป็น
+
+เมื่อการฝึกอบรมเสร็จสิ้น เราจะใช้เมธอด `push_to_hub()` เพื่อให้แน่ใจว่าเราจะอัปโหลดโมเดลเวอร์ชันล่าสุด:
+
+```py
+trainer.push_to_hub(commit_message="Training complete")
+```
+
+คำสั่งนี้จะส่งคืน URL ของการคอมมิตที่เพิ่งทำไป หากคุณต้องการตรวจสอบ:
+
+```python out
+'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
+```
+
+`Trainer` ยังร่างการ์ดโมเดลพร้อมผลการประเมินทั้งหมดแล้วอัปโหลด ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณได้ปรับแต่งโมเดลในงานจำแนกโทเค็นสำเร็จแล้ว ขอแสดงความยินดีด้วย!
+
+หากคุณต้องการเจาะลึกลงไปในวงจรการฝึกซ้อมอีกสักหน่อย ตอนนี้เราจะแสดงให้คุณเห็นถึงวิธีการทำสิ่งเดียวกันโดยใช้ 🤗 Accelerate
+
+## การกำหนดเทร็นนิ่งลูปเฉพาะ[[การกำหนดเทร็นนิ่งลูปเฉพาะ]]
+
+ตอนนี้เรามาดูวงจรการฝึกซ้อมทั้งหมดกัน เพื่อให้คุณปรับแต่งส่วนต่างๆ ที่ต้องการได้อย่างง่ายดาย มันจะดูเหมือนกับสิ่งที่เราทำใน [บทที่ 3](/course/th/chapter3/4) มาก โดยมีการเปลี่ยนแปลงเล็กน้อยสำหรับการประเมิน
+
+### เตรียมทุกอย่างเพื่อการฝึก[[เตรียมทุกอย่างเพื่อการฝึก]]
+
+ก่อนอื่นเราต้องสร้าง `DataLoader`s จากชุดข้อมูลของเรา เราจะใช้ `data_collator` ของเราซ้ำเป็น `collate_fn` และสับเปลี่ยนชุดการฝึก แต่ไม่ใช่ชุดการตรวจสอบ:
+
+```py
+from torch.utils.data import DataLoader
+
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+ต่อไป เราจะสร้างโมเดลของเราขึ้นมาใหม่ เพื่อให้แน่ใจว่าเราจะไม่ทำการปรับแต่งแบบละเอียดจากเมื่อก่อนต่อไป แต่เริ่มต้นจากโมเดล BERT ที่ได้รับการฝึกไว้ล่วงหน้าอีกครั้ง:
+
+```py
+model = AutoModelForTokenClassification.from_pretrained(
+ model_checkpoint,
+ id2label=id2label,
+ label2id=label2id,
+)
+```
+
+จากนั้นเราจะต้องมีเครื่องมือเพิ่มประสิทธิภาพ เราจะใช้ `AdamW` แบบคลาสสิกซึ่งคล้ายกับ 'Adam` แต่มีการแก้ไขวิธีการลดน้ำหนัก:
+
+```py
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+เมื่อเรามีอ็อบเจ็กต์ทั้งหมดแล้ว เราก็สามารถส่งมันไปที่เมธอด `accelerator.prepare()` ได้:
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+
+
+🚨 หากคุณกำลังฝึกบน TPU คุณจะต้องย้ายโค้ดทั้งหมดที่เริ่มต้นจากเซลล์ด้านบนไปยังฟังก์ชันการฝึกเฉพาะ ดู [บทที่ 3](/course/th/chapter3) สำหรับรายละเอียดเพิ่มเติม
+
+
+
+ตอนนี้เราได้ส่ง `train_dataloader` ไปที่ `accelerator.prepare()` แล้ว เราสามารถใช้ความยาวของมันเพื่อคำนวณจำนวนขั้นตอนการฝึกได้ โปรดจำไว้ว่าเราควรทำเช่นนี้เสมอหลังจากเตรียม dataloader เนื่องจากวิธีการนั้นจะเปลี่ยนความยาวของมัน เราใช้กำหนดการเชิงเส้นแบบคลาสสิกจากอัตราการเรียนรู้ถึง 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+สุดท้ายนี้ ในการผลักดันโมเดลของเราไปที่ Hub เราจะต้องสร้างออบเจ็กต์ `Repository` ในโฟลเดอร์ที่ใช้งานได้ ขั้นแรกให้เข้าสู่ระบบ Hugging Face หากคุณยังไม่ได้เข้าสู่ระบบ เราจะกำหนดชื่อที่เก็บจาก ID โมเดลที่เราต้องการให้กับโมเดลของเรา (อย่าลังเลที่จะแทนที่ `repo_name` ด้วยตัวเลือกของคุณเอง เพียงต้องมีชื่อผู้ใช้ของคุณ ซึ่งเป็นสิ่งที่ฟังก์ชัน `get_full_repo_name()` ทำ ):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "bert-finetuned-ner-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/bert-finetuned-ner-accelerate'
+```
+
+จากนั้นเราสามารถโคลนพื้นที่เก็บข้อมูลนั้นในโฟลเดอร์ในเครื่องได้ หากมีอยู่แล้ว โฟลเดอร์ในเครื่องนี้ควรเป็นโคลนของพื้นที่เก็บข้อมูลที่เรากำลังทำงานด้วย:
+
+```py
+output_dir = "bert-finetuned-ner-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+ตอนนี้เราสามารถอัปโหลดทุกสิ่งที่เราบันทึกไว้ใน `output_dir` ได้โดยการเรียกเมธอด `repo.push_to_hub()` ซึ่งจะช่วยให้เราอัปโหลดโมเดลระดับกลางในตอนท้ายของแต่ละ epoch ได้
+
+### ลูปการฝึกอบรม[[ลูปการฝึกอบรม]]
+
+ตอนนี้เราพร้อมที่จะเขียนลูปการฝึกอบรม (training loop) ฉบับเต็มแล้ว เพื่อให้ส่วนการประเมินง่ายขึ้น เราได้กำหนดฟังก์ชัน `postprocess()` นี้ ซึ่งใช้การคาดการณ์และป้ายกำกับและแปลงเป็นรายการสตริง เหมือนกับที่วัตถุ `เมตริก` ของเราคาดหวัง:
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.detach().cpu().clone().numpy()
+ labels = labels.detach().cpu().clone().numpy()
+
+ # Remove ignored index (special tokens) and convert to labels
+ true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
+ true_predictions = [
+ [label_names[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ return true_labels, true_predictions
+```
+
+จากนั้นเราก็สามารถเขียนลูปการฝึกอบรมได้ หลังจากกำหนดแถบความคืบหน้าเพื่อติดตามว่าการฝึกดำเนินไปอย่างไร ลูปจะมีสามส่วน:
+
+- การฝึกในตัวเอง ซึ่งเป็นการวนซ้ำแบบคลาสสิกบน `train_dataloader` คือการส่งต่อผ่านโมเดล จากนั้นย้อนกลับและขั้นตอนการเพิ่มประสิทธิภาพ
+- การประเมิน ซึ่งมีความแปลกใหม่หลังจากได้รับผลลัพธ์ของแบบจำลองของเราเป็นชุด: เนื่องจากกระบวนการสองกระบวนการอาจมีการเสริมอินพุตและป้ายกำกับเป็นรูปร่างที่แตกต่างกัน เราจึงจำเป็นต้องใช้ `accelerator.pad_across_processes()` เพื่อทำการคาดการณ์และ ติดป้ายกำกับรูปร่างเดียวกันก่อนที่จะเรียกเมธอด `gather()` หากเราไม่ทำเช่นนี้ การประเมินจะเกิดข้อผิดพลาดหรือหยุดทำงานตลอดไป จากนั้นเราจะส่งผลลัพธ์ไปที่ `metric.add_batch()` และเรียก `metric.compute()` เมื่อลูปการประเมินสิ้นสุดลง
+- การบันทึกและการอัปโหลด โดยที่เราจะบันทึกโมเดลและโทเค็นไนเซอร์ก่อน จากนั้นจึงเรียก `repo.push_to_hub()` โปรดสังเกตว่าเราใช้อาร์กิวเมนต์ `blocking=False` เพื่อบอกไลบรารี 🤗 Hub ให้พุชในกระบวนการอะซิงโครนัส ด้วยวิธีนี้ การฝึกอบรมจะดำเนินต่อไปตามปกติและคำสั่ง (แบบยาว) นี้จะดำเนินการในเบื้องหลัง
+
+นี่คือโค้ดที่สมบูรณ์สำหรับลูปการฝึกอบรม:
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Training
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in eval_dataloader:
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ predictions = outputs.logits.argmax(dim=-1)
+ labels = batch["labels"]
+
+ # Necessary to pad predictions and labels for being gathered
+ predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(predictions)
+ labels_gathered = accelerator.gather(labels)
+
+ true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=true_predictions, references=true_labels)
+
+ results = metric.compute()
+ print(
+ f"epoch {epoch}:",
+ {
+ key: results[f"overall_{key}"]
+ for key in ["precision", "recall", "f1", "accuracy"]
+ },
+ )
+
+ # Save and upload
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+ในกรณีที่นี่เป็นครั้งแรกที่คุณเห็นโมเดลที่บันทึกไว้ด้วย 🤗 Accelerate ลองใช้เวลาสักครู่เพื่อตรวจสอบโค้ดสามบรรทัดที่มาพร้อมกับโมเดลนั้น:
+
+```py
+accelerator.wait_for_everyone()
+unwrapped_model = accelerator.unwrap_model(model)
+unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+```
+
+บรรทัดแรกอธิบายในตัวมันเอง: มันบอกกระบวนการทั้งหมดให้รอจนกว่าทุกคนจะถึงขั้นตอนนั้นก่อนจะดำเนินการต่อ เพื่อให้แน่ใจว่าเรามีโมเดลเดียวกันในทุกกระบวนการก่อนที่จะบันทึก จากนั้นเราก็คว้า `unwrapped_model` ซึ่งเป็นโมเดลพื้นฐานที่เรากำหนดไว้ เมธอด `accelerator.prepare()` เปลี่ยนโมเดลให้ทำงานในการฝึกแบบกระจาย ดังนั้นจะไม่มีเมธอด `save_pretrained()` อีกต่อไป เมธอด `accelerator.unwrap_model()` จะยกเลิกขั้นตอนนั้น สุดท้ายนี้ เราเรียก `save_pretrained()` แต่บอกวิธีการนั้นให้ใช้ `accelerator.save()` แทน `torch.save()`
+
+เมื่อเสร็จแล้ว คุณควรมีโมเดลที่สร้างผลลัพธ์ที่ค่อนข้างคล้ายกับโมเดลที่ได้รับการฝึกกับ `Trainer` คุณสามารถตรวจสอบโมเดลที่เราฝึกได้โดยใช้โค้ดนี้ที่ [*huggingface-course/bert-finetuned-ner-accelerate*](https://huggingface.co/huggingface-course/bert-finetuned-ner-accelerate) และหากคุณต้องการทดสอบการปรับแต่งใดๆ ในลูปการฝึก คุณสามารถนำไปใช้ได้โดยตรงโดยแก้ไขโค้ดที่แสดงด้านบน!
+
+{/if}
+
+## การใช้โมเดลที่ปรับแต่งแล้ว[[การใช้โมเดลที่ปรับแต่งแล้ว]]
+
+เราได้แสดงให้คุณเห็นแล้วว่าคุณสามารถใช้โมเดลที่เราปรับแต่งอย่างละเอียดบน Model Hub ด้วยวิดเจ็ตการอนุมานได้อย่างไร หากต้องการใช้ภายในเครื่องใน `pipeline` คุณเพียงแค่ต้องระบุตัวระบุโมเดลที่เหมาะสม:
+
+```py
+from transformers import pipeline
+
+# Replace this with your own checkpoint
+model_checkpoint = "huggingface-course/bert-finetuned-ner"
+token_classifier = pipeline(
+ "token-classification", model=model_checkpoint, aggregation_strategy="simple"
+)
+token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")
+```
+
+```python out
+[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
+ {'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
+ {'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
+```
+
+ยอดเยี่ยม! โมเดลของเราใช้งานได้เช่นเดียวกับโมเดลเริ่มต้นสำหรับไปป์ไลน์นี้
diff --git a/chapters/th/chapter7/3.mdx b/chapters/th/chapter7/3.mdx
new file mode 100644
index 000000000..09f657bfb
--- /dev/null
+++ b/chapters/th/chapter7/3.mdx
@@ -0,0 +1,1045 @@
+
+
+# การปรับแต่งโมเดลภาษา[[การปรับแต่งโมเดลภาษา]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+สำหรับแอปพลิเคชัน NLP จำนวนมากที่เกี่ยวข้องกับโมเดล Transformer คุณสามารถใช้โมเดลที่ได้รับการฝึกล่วงหน้าจาก Hugging Face Hub และปรับแต่งข้อมูลของคุณโดยตรงสำหรับงานที่มีอยู่ โดยมีเงื่อนไขว่าคลังข้อมูลที่ใช้สำหรับการฝึกล่วงหน้า (pretraining) ไม่แตกต่างจากคลังข้อมูลที่ใช้ในการปรับแต่งอย่างละเอียดมากนัก การเรียนรู้แบบถ่ายโอน (transfer learning) มักจะให้ผลลัพธ์ที่ดี
+
+อย่างไรก็ตาม มีบางกรณีที่คุณจะต้องปรับแต่งโมเดลภาษาในข้อมูลของคุณก่อน ก่อนที่จะฝึกหัวหน้างานเฉพาะด้าน ตัวอย่างเช่น หากชุดข้อมูลของคุณมีสัญญาทางกฎหมายหรือบทความทางวิทยาศาสตร์ โมเดล Transformer ธรรมดา เช่น BERT โดยทั่วไปจะถือว่าคำเฉพาะโดเมนในคลังข้อมูลของคุณเป็นโทเค็นที่หายาก และประสิทธิภาพผลลัพธ์ที่ได้อาจน้อยกว่าที่น่าพอใจ ด้วยการปรับแต่งโมเดลภาษาบนข้อมูลในโดเมน คุณจะเพิ่มประสิทธิภาพของงานดาวน์สตรีมหลายๆ งานได้ ซึ่งหมายความว่าโดยปกติคุณจะต้องทำขั้นตอนนี้เพียงครั้งเดียวเท่านั้น!
+
+กระบวนการปรับแต่งโมเดลภาษาที่ได้รับการฝึกล่วงหน้าอย่างละเอียดในข้อมูลในโดเมนนี้มักจะเรียกว่า _domain adaptation_ ได้รับความนิยมในปี 2018 โดย [ULMFiT](https://arxiv.org/abs/1801.06146) ซึ่งเป็นหนึ่งในสถาปัตยกรรมประสาทแรกๆ (อิงจาก LSTM) ที่ทำให้การเรียนรู้แบบถ่ายโอนใช้งานได้จริงสำหรับ NLP ตัวอย่างการปรับโดเมนด้วย ULMFiT แสดงอยู่ในภาพด้านล่าง ในส่วนนี้ เราจะทำสิ่งที่คล้ายกัน แต่ใช้ Transformer แทน LSTM!
+
+
+

+

+
+
+
Songs are good. Tanushree Datta looks awesome. Rajpal Yadav is irritating, and Tusshar is not a whole lot better. Kunal Khemu is OK, and Sharman Joshi is the best.'
+'>>> Label: 0'
+
+'>>> Review: Okay, the story makes no sense, the characters lack any dimensionally, the best dialogue is ad-libs about the low quality of movie, the cinematography is dismal, and only editing saves a bit of the muddle, but Sam" Peckinpah directed the film. Somehow, his direction is not enough. For those who appreciate Peckinpah and his great work, this movie is a disappointment. Even a great cast cannot redeem the time the viewer wastes with this minimal effort.
The proper response to the movie is the contempt that the director San Peckinpah, James Caan, Robert Duvall, Burt Young, Bo Hopkins, Arthur Hill, and even Gig Young bring to their work. Watch the great Peckinpah films. Skip this mess.'
+'>>> Label: 0'
+
+'>>> Review: I saw this movie at the theaters when I was about 6 or 7 years old. I loved it then, and have recently come to own a VHS version.
My 4 and 6 year old children love this movie and have been asking again and again to watch it.
I have enjoyed watching it again too. Though I have to admit it is not as good on a little TV.
I do not have older children so I do not know what they would think of it.
The songs are very cute. My daughter keeps singing them over and over.
Hope this helps.'
+'>>> Label: 1'
+```
+
+ใช่แล้ว นี่คือบทวิจารณ์ภาพยนตร์อย่างแน่นอน และหากคุณอายุมากพอ คุณอาจจะเข้าใจความคิดเห็นในรีวิวที่แล้วเกี่ยวกับการเป็นเจ้าของเวอร์ชัน VHS 😜! แม้ว่าเราจะไม่จำเป็นต้องมีป้ายกำกับสำหรับการสร้างแบบจำลองภาษา แต่เราก็เห็นแล้วว่า `0` หมายถึงบทวิจารณ์เชิงลบ ในขณะที่ `1` สอดคล้องกับบทวิจารณ์เชิงบวก
+
+
+
+✏️ **ลองเลย!** สร้างตัวอย่างแบบสุ่มของการแยก `unsupervised` และตรวจสอบว่าป้ายกำกับไม่ใช่ `0` หรือ `1` ขณะที่คุณดำเนินการอยู่ คุณสามารถตรวจสอบได้ว่าป้ายกำกับในการแบ่ง `train` และ `test` นั้นเป็น `0` หรือ `1` จริงๆ นี่เป็นการตรวจสอบสุขภาพที่เป็นประโยชน์ที่ผู้ปฏิบัติงาน NLP ทุกคนควรทำตั้งแต่เริ่มต้น ของโปรเจ็กต์ใหม่!
+
+
+
+ตอนนี้เราได้ดูข้อมูลโดยสรุปแล้ว เรามาเจาะลึกในการเตรียมข้อมูลสำหรับการสร้างแบบจำลองภาษาที่ปกปิดกัน ดังที่เราจะได้เห็น มีขั้นตอนเพิ่มเติมบางอย่างที่ต้องทำเปรียบเทียบกับงานการจำแนกลำดับที่เราเห็นใน [บทที่ 3](/course/th/chapter3) ไปกันเถอะ!
+
+## การประมวลผลข้อมูลล่วงหน้า[[การประมวลผลข้อมูลล่วงหน้า]]
+
+
+
+สำหรับการสร้างแบบจำลองภาษาแบบถดถอยอัตโนมัติและแบบมาสก์ ขั้นตอนก่อนการประมวลผลทั่วไปคือการต่อตัวอย่างทั้งหมดเข้าด้วยกัน จากนั้นแยกคลังข้อมูลทั้งหมดออกเป็นชิ้นที่มีขนาดเท่ากัน สิ่งนี้ค่อนข้างแตกต่างจากแนวทางปกติของเรา โดยที่เราเพียงแต่สร้างโทเค็นตัวอย่างแต่ละรายการ ทำไมต้องเชื่อมทุกอย่างเข้าด้วยกัน? เหตุผลก็คือแต่ละตัวอย่างอาจถูกตัดทอนหากยาวเกินไป และอาจส่งผลให้สูญเสียข้อมูลที่อาจเป็นประโยชน์สำหรับงานการสร้างแบบจำลองภาษา!
+
+ในการเริ่มต้น ก่อนอื่นเราจะโทเค็นคลังข้อมูลของเราตามปกติ แต่ `ไม่มี`_ การตั้งค่าตัวเลือก `truncation=True` ในโทเค็นของเรา นอกจากนี้เรายังจะคว้ารหัสคำหากมี ((ซึ่งจะเป็นหากเราใช้โทเค็นไนเซอร์แบบเร็ว ดังที่อธิบายไว้ใน [บทที่ 6](/course/th/chapter6/3)) เนื่องจากเราต้องการในภายหลัง เพื่อปิดบังคำทั้งหมด เราจะสรุปสิ่งนี้ด้วยฟังก์ชันง่ายๆ และในขณะที่เรากำลังดำเนินการอยู่ เราจะลบคอลัมน์ `text` และ `label` เนื่องจากเราไม่ต้องการมันอีกต่อไปแล้ว:
+
+```python
+def tokenize_function(examples):
+ result = tokenizer(examples["text"])
+ if tokenizer.is_fast:
+ result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))]
+ return result
+
+
+# Use batched=True to activate fast multithreading!
+tokenized_datasets = imdb_dataset.map(
+ tokenize_function, batched=True, remove_columns=["text", "label"]
+)
+tokenized_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 25000
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 25000
+ })
+ unsupervised: Dataset({
+ features: ['attention_mask', 'input_ids', 'word_ids'],
+ num_rows: 50000
+ })
+})
+```
+
+เนื่องจาก DistilBERT เป็นโมเดลที่คล้ายกับ BERT เราจะเห็นได้ว่าข้อความที่เข้ารหัสประกอบด้วย `input_ids` และ `attention_mask` ที่เราเคยเห็นในบทอื่นๆ เช่นเดียวกับ `word_ids` ที่เราเพิ่มเข้าไป
+
+ตอนนี้เราได้โทเค็นบทวิจารณ์ภาพยนตร์ของเราแล้ว ขั้นตอนต่อไปคือการจัดกลุ่มบทวิจารณ์ทั้งหมดเข้าด้วยกันและแบ่งผลลัพธ์ออกเป็นชิ้น ๆ แต่ชิ้นเหล่านี้ควรใหญ่แค่ไหน? ในที่สุดสิ่งนี้จะถูกกำหนดโดยจำนวนหน่วยความจำ GPU ที่คุณมีอยู่ แต่จุดเริ่มต้นที่ดีคือการดูว่าขนาดบริบทสูงสุดของโมเดลคือเท่าใด สามารถอนุมานได้โดยการตรวจสอบแอตทริบิวต์ `model_max_length` ของโทเค็น:
+
+```python
+tokenizer.model_max_length
+```
+
+```python out
+512
+```
+
+ค่านี้ได้มาจากไฟล์ *tokenizer_config.json* ที่เกี่ยวข้องกับจุดตรวจสอบ ในกรณีนี้เราจะเห็นว่าขนาดบริบทคือ 512 โทเค็น เช่นเดียวกับ BERT
+
+
+
+✏️ **ลองดูสิ!** Transformer บางรุ่น เช่น [BigBird](https://huggingface.co/google/bigbird-roberta-base) และ [Longformer](hf.co/allenai/longformer-base-4096) มีความยาวบริบทที่ยาวกว่า BERT และ Transformer รุ่นแรกๆ มาก สร้างอินสแตนซ์โทเค็นไนเซอร์สำหรับจุดตรวจสอบจุดใดจุดหนึ่งเหล่านี้ และตรวจสอบว่า `model_max_length` สอดคล้องกับสิ่งที่อ้างถึงในการ์ดโมเดล
+
+
+
+
+ดังนั้น เพื่อทำการทดลองกับ GPU เช่นเดียวกับที่พบใน Google Colab เราจะเลือกสิ่งที่เล็กกว่าเล็กน้อยที่สามารถใส่ในหน่วยความจำได้:
+
+```python
+chunk_size = 128
+```
+
+
+
+โปรดทราบว่าการใช้ขนาดก้อนเล็กอาจส่งผลเสียในสถานการณ์จริง ดังนั้น คุณควรใช้ขนาดที่สอดคล้องกับกรณีการใช้งานที่คุณจะนำโมเดลไปใช้
+
+
+
+ตอนนี้ส่วนที่สนุกมา เพื่อแสดงให้เห็นว่าการต่อข้อมูลทำงานอย่างไร เรามาทบทวนบางส่วนจากชุดการฝึกอบรมโทเค็นของเรา และพิมพ์จำนวนโทเค็นต่อการตรวจสอบ:
+
+```python
+# Slicing produces a list of lists for each feature
+tokenized_samples = tokenized_datasets["train"][:3]
+
+for idx, sample in enumerate(tokenized_samples["input_ids"]):
+ print(f"'>>> Review {idx} length: {len(sample)}'")
+```
+
+```python out
+'>>> Review 0 length: 200'
+'>>> Review 1 length: 559'
+'>>> Review 2 length: 192'
+```
+
+จากนั้นเราสามารถเชื่อมตัวอย่างเหล่านี้ทั้งหมดเข้าด้วยกันด้วยความเข้าใจในพจนานุกรมง่ายๆ ดังนี้:
+
+```python
+concatenated_examples = {
+ k: sum(tokenized_samples[k], []) for k in tokenized_samples.keys()
+}
+total_length = len(concatenated_examples["input_ids"])
+print(f"'>>> Concatenated reviews length: {total_length}'")
+```
+
+```python out
+'>>> Concatenated reviews length: 951'
+```
+
+เยี่ยมมาก ตรวจสอบความยาวทั้งหมดแล้ว ตอนนี้เรามาแบ่งบทวิจารณ์ที่ต่อกันออกเป็นส่วนๆ ตามขนาดที่กำหนดโดย `chunk_size` ในการทำเช่นนั้น เราจะทำซ้ำคุณลักษณะต่างๆ ใน `concatenated_examples` และใช้รายการความเข้าใจเพื่อสร้างชิ้นส่วนของแต่ละคุณลักษณะ ผลลัพธ์ที่ได้คือพจนานุกรมที่ประกอบด้วยส่วนต่างๆ สำหรับแต่ละฟีเจอร์:
+
+```python
+chunks = {
+ k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
+ for k, t in concatenated_examples.items()
+}
+
+for chunk in chunks["input_ids"]:
+ print(f"'>>> Chunk length: {len(chunk)}'")
+```
+
+```python out
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 128'
+'>>> Chunk length: 55'
+```
+
+ดังที่คุณเห็นในตัวอย่างนี้ โดยทั่วไปชิ้นสุดท้ายจะเล็กกว่าขนาดชิ้นสูงสุด มีสองกลยุทธ์หลักในการจัดการกับสิ่งนี้:
+
+* ลบชิ้นสุดท้ายหากมีขนาดเล็กกว่า `chunk_size`
+* แพดชิ้นสุดท้ายจนกระทั่งความยาวเท่ากับ `chunk_size`
+
+เราจะใช้แนวทางแรกที่นี่ ดังนั้นเราจะรวมตรรกะข้างต้นทั้งหมดไว้ในฟังก์ชันเดียวที่เราสามารถนำไปใช้กับชุดข้อมูลโทเค็นของเราได้:
+
+```python
+def group_texts(examples):
+ # Concatenate all texts
+ concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+ # Compute length of concatenated texts
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the last chunk if it's smaller than chunk_size
+ total_length = (total_length // chunk_size) * chunk_size
+ # Split by chunks of max_len
+ result = {
+ k: [t[i : i + chunk_size] for i in range(0, total_length, chunk_size)]
+ for k, t in concatenated_examples.items()
+ }
+ # Create a new labels column
+ result["labels"] = result["input_ids"].copy()
+ return result
+```
+
+โปรดทราบว่าในขั้นตอนสุดท้ายของ `group_texts()` เราจะสร้างคอลัมน์ `labels` ใหม่ ซึ่งเป็นสำเนาของคอลัมน์ `input_ids` ดังที่เราจะได้เห็นในเร็วๆ นี้ นั่นเป็นเพราะในการสร้างแบบจำลองภาษาที่สวมหน้ากากนั้น มีวัตถุประสงค์เพื่อคาดการณ์โทเค็นที่สวมหน้ากากแบบสุ่มในชุดอินพุต และด้วยการสร้างคอลัมน์ `labels` เราจึงจัดเตรียมความจริงพื้นฐานสำหรับโมเดลภาษาของเราในการเรียนรู้
+
+ตอนนี้ลองใช้ `group_texts()` กับชุดข้อมูลโทเค็นของเราโดยใช้ฟังก์ชัน `Dataset.map()` ที่เชื่อถือได้ของเรา:
+
+```python
+lm_datasets = tokenized_datasets.map(group_texts, batched=True)
+lm_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 61289
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 59905
+ })
+ unsupervised: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 122963
+ })
+})
+```
+
+คุณจะเห็นว่าการจัดกลุ่มและการแบ่งส่วนข้อความทำให้เกิดตัวอย่างมากกว่า 25,000 แบบเดิมของเราสำหรับการแยกแบบ `train` และ `test` นั่นเป็นเพราะว่าตอนนี้เรามีตัวอย่างที่เกี่ยวข้องกับ _contiguous tokens_ ที่ครอบคลุมหลายตัวอย่างจากคลังข้อมูลดั้งเดิม คุณสามารถดูสิ่งนี้ได้อย่างชัดเจนโดยมองหาโทเค็นพิเศษ `[SEP]` และ `[CLS]` ในส่วนใดส่วนหนึ่ง:
+
+```python
+tokenizer.decode(lm_datasets["train"][1]["input_ids"])
+```
+
+```python out
+".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
+```
+
+ในตัวอย่างนี้ คุณจะเห็นบทวิจารณ์ภาพยนตร์สองเรื่องที่ทับซ้อนกัน เรื่องหนึ่งเกี่ยวกับภาพยนตร์ระดับมัธยมศึกษาตอนปลาย และอีกเรื่องเกี่ยวกับคนไร้บ้าน นอกจากนี้ เรามาดูกันว่าป้ายกำกับสำหรับการสร้างแบบจำลองภาษาที่สวมหน้ากากมีลักษณะอย่างไร:
+
+```python out
+tokenizer.decode(lm_datasets["train"][1]["labels"])
+```
+
+```python out
+".... at.......... high. a classic line : inspector : i'm here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn't! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless"
+```
+
+ตามที่คาดไว้จากฟังก์ชัน `group_texts()` ด้านบน สิ่งนี้ดูเหมือนกับ `input_ids` ที่ถอดรหัสแล้ว -- แต่แล้วแบบจำลองของเราจะเรียนรู้อะไรได้อย่างไร เราขาดขั้นตอนสำคัญ: การแทรกโทเค็น `[MASK]` ที่ตำแหน่งสุ่มในอินพุต! มาดูกันว่าเราสามารถดำเนินการนี้ได้ทันทีระหว่างการปรับแต่งแบบละเอียดโดยใช้ตัวรวบรวมข้อมูลพิเศษได้อย่างไร
+
+## ปรับแต่ง DistilBERT อย่างละเอียดด้วย `Trainer` API
+
+การปรับแต่งโมเดลภาษามาสก์อย่างละเอียดเกือบจะเหมือนกับการปรับแต่งโมเดลการจำแนกลำดับอย่างละเอียด เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3) ข้อแตกต่างเพียงอย่างเดียวคือเราต้องการตัวรวบรวมข้อมูลพิเศษที่สามารถสุ่มปกปิดโทเค็นบางส่วนในข้อความแต่ละชุดได้ โชคดีที่ 🤗 Transformers มาพร้อมกับ `DataCollatorForLanguageModeling` โดยเฉพาะสำหรับงานนี้ เราแค่ต้องส่งโทเค็นไนเซอร์และอาร์กิวเมนต์ `mlm_probability` ที่ระบุเศษส่วนของโทเค็นที่จะปกปิด เราจะเลือก 15% ซึ่งเป็นจำนวนที่ใช้สำหรับ BERT และตัวเลือกทั่วไปในวรรณกรรม:
+
+```python
+from transformers import DataCollatorForLanguageModeling
+
+data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
+```
+
+หากต้องการดูวิธีการทำงานของการมาสก์แบบสุ่ม เราจะป้อนตัวอย่างบางส่วนให้กับผู้รวบรวมข้อมูล เนื่องจากคาดว่าจะมีรายการ `dict` โดยที่ `dict` แต่ละอันแสดงถึงข้อความที่ต่อเนื่องกันเพียงก้อนเดียว เราจึงวนซ้ำชุดข้อมูลก่อนก่อนที่จะป้อนแบทช์ให้กับผู้เปรียบเทียบ เราลบคีย์ `"word_ids"` สำหรับผู้รวบรวมข้อมูลนี้เนื่องจากไม่ได้คาดหวัง:
+
+```python
+samples = [lm_datasets["train"][i] for i in range(2)]
+for sample in samples:
+ _ = sample.pop("word_ids")
+
+for chunk in data_collator(samples)["input_ids"]:
+ print(f"\n'>>> {tokenizer.decode(chunk)}'")
+```
+
+```python output
+'>>> [CLS] bromwell [MASK] is a cartoon comedy. it ran at the same [MASK] as some other [MASK] about school life, [MASK] as " teachers ". [MASK] [MASK] [MASK] in the teaching [MASK] lead [MASK] to believe that bromwell high\'[MASK] satire is much closer to reality than is " teachers ". the scramble [MASK] [MASK] financially, the [MASK]ful students whogn [MASK] right through [MASK] pathetic teachers\'pomp, the pettiness of the whole situation, distinction remind me of the schools i knew and their students. when i saw [MASK] episode in [MASK] a student repeatedly tried to burn down the school, [MASK] immediately recalled. [MASK]...'
+
+'>>> .... at.. [MASK]... [MASK]... high. a classic line plucked inspector : i\'[MASK] here to [MASK] one of your [MASK]. student : welcome to bromwell [MASK]. i expect that many adults of my age think that [MASK]mwell [MASK] is [MASK] fetched. what a pity that it isn\'t! [SEP] [CLS] [MASK]ness ( or [MASK]lessness as george 宇in stated )公 been an issue for years but never [MASK] plan to help those on the street that were once considered human [MASK] did everything from going to school, [MASK], [MASK] vote for the matter. most people think [MASK] the homeless'
+```
+
+เยี่ยมเลย มันได้ผล! เราจะเห็นว่าโทเค็น `[MASK]` ได้รับการสุ่มแทรกในตำแหน่งต่างๆ ในข้อความของเรา สิ่งเหล่านี้จะเป็นโทเค็นที่แบบจำลองของเราจะต้องทำนายระหว่างการฝึก และข้อดีของผู้รวบรวมข้อมูลก็คือ มันจะสุ่มการแทรก `[MASK]` ในทุกชุด!
+
+
+
+✏️ **ลองดูสิ!** เรียกใช้ข้อมูลโค้ดด้านบนหลายๆ ครั้งเพื่อดูว่าการมาสก์แบบสุ่มเกิดขึ้นต่อหน้าต่อตาคุณ! นอกจากนี้ ให้แทนที่เมธอด `tokenizer.decode()` ด้วย `tokenizer.convert_ids_to_tokens()` เพื่อดูว่าบางครั้งโทเค็นเดียวจากคำที่กำหนดจะถูกปกปิด ไม่ใช่โทเค็นอื่นๆ
+
+
+
+{#if fw === 'pt'}
+
+ผลข้างเคียงอย่างหนึ่งของการมาสก์แบบสุ่มคือเมตริกการประเมินของเราจะไม่ถูกกำหนดไว้เมื่อใช้ `Trainer` เนื่องจากเราใช้ตัวเปรียบเทียบข้อมูลเดียวกันสำหรับชุดการฝึกและการทดสอบ เราจะเห็นในภายหลังเมื่อเราดูการปรับแต่งอย่างละเอียดด้วย 🤗 Accelerate เราจะใช้ความยืดหยุ่นของลูปการประเมินแบบกำหนดเองเพื่อหยุดการสุ่มได้อย่างไร
+
+{/if}
+
+เมื่อฝึกโมเดลสำหรับการสร้างแบบจำลองภาษาที่ปกปิด เทคนิคหนึ่งที่สามารถใช้ได้คือการมาสก์ทั้งคำเข้าด้วยกัน ไม่ใช่แค่โทเค็นเดี่ยวๆ วิธีการนี้เรียกว่า _whole word masking_ หากเราต้องการใช้การมาสก์ทั้งคำ เราจะต้องสร้างตัวเปรียบเทียบข้อมูลด้วยตัวเอง ตัวรวบรวมข้อมูลเป็นเพียงฟังก์ชันที่รับรายการตัวอย่างและแปลงเป็นชุด ดังนั้นเรามาเริ่มกันเลย! เราจะใช้รหัสคำที่คำนวณไว้ก่อนหน้านี้เพื่อสร้างแผนที่ระหว่างดัชนีคำและโทเค็นที่เกี่ยวข้อง จากนั้นสุ่มตัดสินใจว่าจะปกปิดคำใดและใช้มาสก์นั้นกับอินพุต โปรดทราบว่าป้ายกำกับทั้งหมดเป็น "-100" ยกเว้นป้ายกำกับที่เกี่ยวข้องกับคำมาสก์
+
+{#if fw === 'pt'}
+
+```py
+import collections
+import numpy as np
+
+from transformers import default_data_collator
+
+wwm_probability = 0.2
+
+
+def whole_word_masking_data_collator(features):
+ for feature in features:
+ word_ids = feature.pop("word_ids")
+
+ # Create a map between words and corresponding token indices
+ mapping = collections.defaultdict(list)
+ current_word_index = -1
+ current_word = None
+ for idx, word_id in enumerate(word_ids):
+ if word_id is not None:
+ if word_id != current_word:
+ current_word = word_id
+ current_word_index += 1
+ mapping[current_word_index].append(idx)
+
+ # Randomly mask words
+ mask = np.random.binomial(1, wwm_probability, (len(mapping),))
+ input_ids = feature["input_ids"]
+ labels = feature["labels"]
+ new_labels = [-100] * len(labels)
+ for word_id in np.where(mask)[0]:
+ word_id = word_id.item()
+ for idx in mapping[word_id]:
+ new_labels[idx] = labels[idx]
+ input_ids[idx] = tokenizer.mask_token_id
+ feature["labels"] = new_labels
+
+ return default_data_collator(features)
+```
+
+{:else}
+
+```py
+import collections
+import numpy as np
+
+from transformers.data.data_collator import tf_default_data_collator
+
+wwm_probability = 0.2
+
+
+def whole_word_masking_data_collator(features):
+ for feature in features:
+ word_ids = feature.pop("word_ids")
+
+ # Create a map between words and corresponding token indices
+ mapping = collections.defaultdict(list)
+ current_word_index = -1
+ current_word = None
+ for idx, word_id in enumerate(word_ids):
+ if word_id is not None:
+ if word_id != current_word:
+ current_word = word_id
+ current_word_index += 1
+ mapping[current_word_index].append(idx)
+
+ # Randomly mask words
+ mask = np.random.binomial(1, wwm_probability, (len(mapping),))
+ input_ids = feature["input_ids"]
+ labels = feature["labels"]
+ new_labels = [-100] * len(labels)
+ for word_id in np.where(mask)[0]:
+ word_id = word_id.item()
+ for idx in mapping[word_id]:
+ new_labels[idx] = labels[idx]
+ input_ids[idx] = tokenizer.mask_token_id
+ feature["labels"] = new_labels
+
+ return tf_default_data_collator(features)
+```
+
+{/if}
+
+ต่อไป เราสามารถลองใช้ตัวอย่างเดียวกันกับเมื่อก่อนได้:
+
+```py
+samples = [lm_datasets["train"][i] for i in range(2)]
+batch = whole_word_masking_data_collator(samples)
+
+for chunk in batch["input_ids"]:
+ print(f"\n'>>> {tokenizer.decode(chunk)}'")
+```
+
+```python out
+'>>> [CLS] bromwell high is a cartoon comedy [MASK] it ran at the same time as some other programs about school life, such as " teachers ". my 35 years in the teaching profession lead me to believe that bromwell high\'s satire is much closer to reality than is " teachers ". the scramble to survive financially, the insightful students who can see right through their pathetic teachers\'pomp, the pettiness of the whole situation, all remind me of the schools i knew and their students. when i saw the episode in which a student repeatedly tried to burn down the school, i immediately recalled.....'
+
+'>>> .... [MASK] [MASK] [MASK] [MASK]....... high. a classic line : inspector : i\'m here to sack one of your teachers. student : welcome to bromwell high. i expect that many adults of my age think that bromwell high is far fetched. what a pity that it isn\'t! [SEP] [CLS] homelessness ( or houselessness as george carlin stated ) has been an issue for years but never a plan to help those on the street that were once considered human who did everything from going to school, work, or vote for the matter. most people think of the homeless'
+```
+
+
+
+✏️ **ลองดูสิ!** เรียกใช้ข้อมูลโค้ดด้านบนหลายๆ ครั้งเพื่อดูว่าการมาสก์แบบสุ่มเกิดขึ้นต่อหน้าต่อตาคุณ! นอกจากนี้ ให้แทนที่เมธอด `tokenizer.decode()` ด้วย `tokenizer.convert_ids_to_tokens()` เพื่อดูว่าโทเค็นจากคำที่กำหนดจะถูกมาสก์ไว้ด้วยกันเสมอ
+
+
+
+ตอนนี้เรามีผู้รวบรวมข้อมูลสองกลุ่มแล้ว ขั้นตอนการปรับแต่งที่เหลือถือเป็นมาตรฐาน การฝึกอบรมอาจใช้เวลาสักระยะบน Google Colab หากคุณโชคดีไม่พอที่จะได้ P100 GPU อันเป็นตำนาน 😭 ดังนั้นก่อนอื่นเราจะลดขนาดชุดการฝึกลงเหลือเพียงไม่กี่พันตัวอย่างก่อน ไม่ต้องกังวล เรายังคงได้รับโมเดลภาษาที่ดีพอสมควร! วิธีที่รวดเร็วในการสุ่มตัวอย่างชุดข้อมูลใน 🤗 ชุดข้อมูลคือผ่านฟังก์ชัน `Dataset.train_test_split()` ที่เราเห็นใน [บทที่ 5](/course/th/chapter5):
+
+```python
+train_size = 10_000
+test_size = int(0.1 * train_size)
+
+downsampled_dataset = lm_datasets["train"].train_test_split(
+ train_size=train_size, test_size=test_size, seed=42
+)
+downsampled_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 10000
+ })
+ test: Dataset({
+ features: ['attention_mask', 'input_ids', 'labels', 'word_ids'],
+ num_rows: 1000
+ })
+})
+```
+
+สิ่งนี้ได้สร้างการแยก `train` และ `test` ใหม่โดยอัตโนมัติ โดยกำหนดขนาดชุดการฝึกไว้ที่ 10,000 ตัวอย่าง และการตรวจสอบความถูกต้องตั้งไว้ที่ 10% ของจำนวนนั้น คุณสามารถเพิ่มสิ่งนี้ได้ตามใจชอบ หากคุณมี GPU ที่แข็งแกร่ง! สิ่งต่อไปที่เราต้องทำคือเข้าสู่ระบบ Hugging Face Hub หากคุณใช้โค้ดนี้ในโน้ตบุ๊ก คุณสามารถทำได้โดยใช้ฟังก์ชันยูทิลิตีต่อไปนี้:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+ซึ่งจะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองของคุณได้ หรือคุณสามารถเรียกใช้:
+
+```
+huggingface-cli login
+```
+
+ในเทอร์มินัลที่คุณชื่นชอบและเข้าสู่ระบบที่นั่น
+
+{#if fw === 'tf'}
+
+เมื่อเราเข้าสู่ระบบแล้ว เราสามารถสร้างชุดข้อมูล `tf.data` ได้ ในการดำเนินการดังกล่าว เราจะใช้เมธอด `prepare_tf_dataset()` ซึ่งใช้แบบจำลองของเราในการอนุมานโดยอัตโนมัติว่าคอลัมน์ใดควรอยู่ในชุดข้อมูล หากคุณต้องการควบคุมคอลัมน์ที่จะใช้อย่างชัดเจน คุณสามารถใช้เมธอด `Dataset.to_tf_dataset()` แทนได้ เพื่อให้ทุกอย่างง่ายขึ้น เราจะใช้ตัวรวบรวมข้อมูลมาตรฐานที่นี่ แต่คุณยังสามารถลองใช้ตัวเปรียบเทียบการปกปิดคำทั้งหมดและเปรียบเทียบผลลัพธ์เป็นแบบฝึกหัดได้:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ downsampled_dataset["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+
+tf_eval_dataset = model.prepare_tf_dataset(
+ downsampled_dataset["test"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=32,
+)
+```
+
+ต่อไป เราจะตั้งค่าไฮเปอร์พารามิเตอร์การฝึกอบรมและคอมไพล์โมเดลของเรา เราใช้ฟังก์ชัน `create_optimizer()` จากไลบรารี 🤗 Transformers ซึ่งให้เครื่องมือเพิ่มประสิทธิภาพ `AdamW` แก่เราพร้อมการลดอัตราการเรียนรู้เชิงเส้น นอกจากนี้เรายังใช้การสูญเสียในตัวของโมเดล ซึ่งเป็นค่าเริ่มต้นเมื่อไม่มีการระบุการสูญเสียเป็นอาร์กิวเมนต์สำหรับ `compile()` และเราตั้งค่าความแม่นยำในการฝึกอบรมเป็น `"mixed_float16"` โปรดทราบว่าหากคุณใช้ Colab GPU หรือ GPU อื่นๆ ที่ไม่รองรับการเร่งความเร็ว float16 คุณน่าจะ comment ในบรรทัดนั้นเพื่อไม่ให้คำสั่งบรรทัดนั้นทำงาน
+
+นอกจากนี้ เรายังตั้งค่า `PushToHubCallback` ที่จะบันทึกโมเดลไปที่ Hub หลังจากแต่ละ epoch คุณสามารถระบุชื่อของพื้นที่เก็บข้อมูลที่คุณต้องการพุชด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น ในการผลักดันโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นในกรณีของเราจะเป็น `"lewtun/distilbert-finetuned-imdb"`
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+num_train_steps = len(tf_train_dataset)
+optimizer, schedule = create_optimizer(
+ init_lr=2e-5,
+ num_warmup_steps=1_000,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Train in mixed-precision float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+
+model_name = model_checkpoint.split("/")[-1]
+callback = PushToHubCallback(
+ output_dir=f"{model_name}-finetuned-imdb", tokenizer=tokenizer
+)
+```
+
+ตอนนี้เราพร้อมที่จะรัน `model.fit()` แล้ว -- แต่ก่อนที่จะดำเนินการ เรามาดู _perplexity_ สั้นๆ กันก่อน ซึ่งเป็นตัวชี้วัดทั่วไปในการประเมินประสิทธิภาพของโมเดลภาษา
+
+{:else}
+
+เมื่อเราเข้าสู่ระบบแล้ว เราสามารถระบุข้อโต้แย้งสำหรับ `Trainer` ได้:
+
+```python
+from transformers import TrainingArguments
+
+batch_size = 64
+# Show the training loss with every epoch
+logging_steps = len(downsampled_dataset["train"]) // batch_size
+model_name = model_checkpoint.split("/")[-1]
+
+training_args = TrainingArguments(
+ output_dir=f"{model_name}-finetuned-imdb",
+ overwrite_output_dir=True,
+ evaluation_strategy="epoch",
+ learning_rate=2e-5,
+ weight_decay=0.01,
+ per_device_train_batch_size=batch_size,
+ per_device_eval_batch_size=batch_size,
+ push_to_hub=True,
+ fp16=True,
+ logging_steps=logging_steps,
+)
+```
+
+ที่นี่เราได้ปรับแต่งตัวเลือกเริ่มต้นบางส่วน รวมถึง `logging_steps` เพื่อให้แน่ใจว่าเราจะติดตามการสูญเสียการฝึกในแต่ละ epoch นอกจากนี้ เรายังใช้ `fp16=True` เพื่อเปิดใช้การฝึกแบบผสมความแม่นยำ ซึ่งช่วยให้เราเร่งความเร็วได้อีกครั้ง ตามค่าเริ่มต้น `Trainer` จะลบคอลัมน์ใดๆ ที่ไม่ได้เป็นส่วนหนึ่งของเมธอด `forward()` ของโมเดล ซึ่งหมายความว่าหากคุณใช้ตัวจับคู่การมาสก์ทั้งคำ คุณจะต้องตั้งค่า `remove_unused_columns=False` เพื่อให้แน่ใจว่าเราจะไม่สูญเสียคอลัมน์ `word_ids` ในระหว่างการฝึก
+
+โปรดทราบว่าคุณสามารถระบุชื่อของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/distilbert-finetuned-imdb"` ลงใน `TrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นในกรณีของเราจะเป็น `"lewtun/distilbert-finetuned-imdb"`
+
+ตอนนี้เรามีส่วนผสมทั้งหมดในการสร้างตัวอย่าง `Trainer` แล้ว ในที่นี้เราใช้ `data_collator` มาตรฐาน แต่คุณสามารถลองใช้ตัวเปรียบเทียบการปกปิดทั้งคำและเปรียบเทียบผลลัพธ์เป็นแบบฝึกหัดได้:
+
+```python
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=downsampled_dataset["train"],
+ eval_dataset=downsampled_dataset["test"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+)
+```
+
+ตอนนี้เราพร้อมที่จะรัน `trainer.train()` แล้ว -- แต่ก่อนที่จะดำเนินการ เรามาดู _perplexity_ สั้นๆ กันก่อน ซึ่งเป็นตัวชี้วัดทั่วไปในการประเมินประสิทธิภาพของโมเดลภาษา
+
+{/if}
+
+### ความฉงนสนเท่ห์สำหรับแบบจำลองภาษา[[ความฉงนสนเท่ห์สำหรับแบบจำลองภาษา]]
+
+
+
+แตกต่างจากงานอื่นๆ เช่น การจัดหมวดหมู่ข้อความ หรือการตอบคำถามโดยที่เราได้รับคลังข้อมูลที่มีป้ายกำกับไว้เพื่อฝึกฝน เนื่องจากการสร้างแบบจำลองภาษาเราไม่มีป้ายกำกับที่ชัดเจน แล้วเราจะทราบได้อย่างไรว่าอะไรคือสิ่งที่ทำให้โมเดลภาษาที่ดี? เช่นเดียวกับคุณสมบัติการแก้ไขอัตโนมัติในโทรศัพท์ของคุณ รูปแบบภาษาที่ดีคือรูปแบบที่กำหนดความน่าจะเป็นสูงให้กับประโยคที่ถูกต้องตามหลักไวยากรณ์ และความน่าจะเป็นต่ำสำหรับประโยคไร้สาระ เพื่อให้คุณเข้าใจได้ดีขึ้นว่าสิ่งนี้เป็นอย่างไร คุณสามารถค้นหา "autocorrect fails" ทั้งชุดทางออนไลน์ ซึ่งโมเดลในโทรศัพท์ของบุคคลนั้นได้สร้างการดำเนินการที่ค่อนข้างตลก (และมักไม่เหมาะสม)!
+
+{#if fw === 'pt'}
+
+สมมติว่าชุดทดสอบของเราประกอบด้วยประโยคส่วนใหญ่ที่ถูกต้องตามหลักไวยากรณ์ ดังนั้นวิธีหนึ่งในการวัดคุณภาพของแบบจำลองภาษาของเราคือการคำนวณความน่าจะเป็นที่แบบจำลองกำหนดให้กับคำถัดไปในประโยคทั้งหมดของชุดทดสอบ ความน่าจะเป็นสูงบ่งชี้ว่าโมเดลไม่ได้ "ประหลาดใจ" หรือ "งุนงง" กับตัวอย่างที่มองไม่เห็น และแนะนำว่าโมเดลได้เรียนรู้รูปแบบพื้นฐานของไวยากรณ์ในภาษาแล้ว มีคำจำกัดความทางคณิตศาสตร์หลายประการของความฉงนสนเท่ห์ แต่คำที่เราจะใช้กำหนดว่ามันเป็นเลขชี้กำลังของการสูญเสีย cross-entropy ดังนั้น เราสามารถคำนวณความงุนงงของแบบจำลองที่ฝึกไว้ล่วงหน้าได้โดยใช้ฟังก์ชัน `Trainer.evaluate()` เพื่อคำนวณการสูญเสีย cross-entropy ข้ามในชุดทดสอบ จากนั้นหาเลขชี้กำลังของผลลัพธ์:
+
+```python
+import math
+
+eval_results = trainer.evaluate()
+print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+```
+
+{:else}
+
+สมมติว่าชุดทดสอบของเราประกอบด้วยประโยคส่วนใหญ่ที่ถูกต้องตามหลักไวยากรณ์ ดังนั้นวิธีหนึ่งในการวัดคุณภาพของแบบจำลองภาษาของเราคือการคำนวณความน่าจะเป็นที่แบบจำลองกำหนดให้กับคำถัดไปในประโยคทั้งหมดของชุดทดสอบ ความน่าจะเป็นสูงบ่งชี้ว่าแบบจำลองบ่งชี้ว่าแบบจำลองนั้นไม่ "แปลกใจ" หรือ "งุนงง" กับตัวอย่างที่มองไม่เห็น และแนะนำว่าแบบจำลองได้เรียนรู้รูปแบบพื้นฐานของไวยากรณ์ในภาษาแล้ว มีคำจำกัดความทางคณิตศาสตร์หลายประการของความฉงนสนเท่ห์ แต่คำที่เราจะใช้กำหนดว่ามันเป็นเลขชี้กำลังของการสูญเสีย cross-entropy ดังนั้น เราสามารถคำนวณความฉงนสนเท่ห์ของแบบจำลองที่ฝึกไว้ล่วงหน้าได้โดยใช้วิธี `model.evaluate()` เพื่อคำนวณการสูญเสีย cross-entropy ในชุดทดสอบ จากนั้นหาเลขชี้กำลังของผลลัพธ์:
+
+```python
+import math
+
+eval_loss = model.evaluate(tf_eval_dataset)
+print(f"Perplexity: {math.exp(eval_loss):.2f}")
+```
+
+{/if}
+
+```python out
+>>> Perplexity: 21.75
+```
+
+คะแนนความฉงนสนเท่ห์ที่ต่ำกว่าหมายถึงโมเดลภาษาที่ดีกว่า และเราจะเห็นได้ที่นี่ว่าโมเดลเริ่มต้นของเรามีค่าค่อนข้างมาก มาดูกันว่าเราจะลดมันลงโดยการปรับแบบละเอียดได้ไหม! เพื่อทำเช่นนั้น ขั้นแรกเราจะรันลูปการฝึกซ้อม:
+
+{#if fw === 'pt'}
+
+```python
+trainer.train()
+```
+
+{:else}
+
+```python
+model.fit(tf_train_dataset, validation_data=tf_eval_dataset, callbacks=[callback])
+```
+
+{/if}
+
+แล้วจึงคำนวณความฉงนสนเท่ห์ที่เกิดขึ้นกับชุดทดสอบดังเดิม:
+
+{#if fw === 'pt'}
+
+```python
+eval_results = trainer.evaluate()
+print(f">>> Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+```
+
+{:else}
+
+```python
+eval_loss = model.evaluate(tf_eval_dataset)
+print(f"Perplexity: {math.exp(eval_loss):.2f}")
+```
+
+{/if}
+
+```python out
+>>> Perplexity: 11.32
+```
+
+เยี่ยมเลย -- นี่เป็นการลดความซับซ้อนได้ค่อนข้างมาก ซึ่งบอกเราว่าโมเดลได้เรียนรู้บางอย่างเกี่ยวกับขอบเขตของการวิจารณ์ภาพยนตร์!
+
+{#if fw === 'pt'}
+
+เมื่อการฝึกเสร็จสิ้น เราสามารถส่งการ์ดโมเดลพร้อมข้อมูลการฝึกไปยัง Hub ได้ (จุดตรวจสอบจะถูกบันทึกไว้ระหว่างการฝึก):
+
+```python
+trainer.push_to_hub()
+```
+
+{/if}
+
+
+
+✏️ **ตาคุณแล้ว!** ดำเนินการฝึกอบรมข้างต้นหลังจากเปลี่ยนตัวเปรียบเทียบข้อมูลเป็นตัวเปรียบเทียบการปกปิดทั้งคำ คุณได้รับผลลัพธ์ที่ดีขึ้นหรือไม่?
+
+
+
+{#if fw === 'pt'}
+
+ในกรณีการใช้งานของเรา เราไม่จำเป็นต้องทำอะไรเป็นพิเศษกับลูปการฝึกอบรม แต่ในบางกรณี คุณอาจจำเป็นต้องใช้ตรรกะแบบกำหนดเองบางอย่าง สำหรับแอปพลิเคชันเหล่านี้ คุณสามารถใช้ 🤗 Accelerate -- มาดูกัน!
+
+## ปรับแต่ง DistilBERT ปรับแต่ง 🤗 Accelerate
+
+ดังที่เราเห็นใน `Trainer` การปรับแต่งโมเดลภาษาที่สวมหน้ากากอย่างละเอียดนั้นคล้ายคลึงกับตัวอย่างการจัดประเภทข้อความจาก [บทที่ 3](/course/th/chapter3) มาก อันที่จริง รายละเอียดปลีกย่อยเพียงอย่างเดียวคือการใช้ตัวรวบรวมข้อมูลพิเศษ และเราได้กล่าวถึงไปแล้วก่อนหน้านี้ในส่วนนี้!
+
+อย่างไรก็ตาม เราพบว่า `DataCollatorForLanguageModeling` ยังใช้การมาสก์แบบสุ่มกับการประเมินแต่ละครั้ง ดังนั้นเราจะเห็นความผันผวนของคะแนนความงุนงงของเราในการฝึกแต่ละครั้ง วิธีหนึ่งในการกำจัดแหล่งที่มาของการสุ่มนี้คือการใช้การมาสก์ _once_ กับชุดการทดสอบทั้งหมด จากนั้นใช้ตัวรวบรวมข้อมูลเริ่มต้นใน 🤗 Transformers เพื่อรวบรวมแบทช์ระหว่างการประเมิน หากต้องการดูวิธีการทำงาน ลองใช้ฟังก์ชันง่ายๆ ที่ใช้การมาสก์กับแบทช์ คล้ายกับการเผชิญหน้าครั้งแรกกับ `DataCollatorForLanguageModeling`:
+
+```python
+def insert_random_mask(batch):
+ features = [dict(zip(batch, t)) for t in zip(*batch.values())]
+ masked_inputs = data_collator(features)
+ # Create a new "masked" column for each column in the dataset
+ return {"masked_" + k: v.numpy() for k, v in masked_inputs.items()}
+```
+
+ต่อไป เราจะใช้ฟังก์ชันนี้กับชุดทดสอบของเรา และวางคอลัมน์ที่ไม่ได้ปิดบังไว้ เพื่อให้เราสามารถแทนที่คอลัมน์เหล่านั้นด้วยคอลัมน์ที่ปิดบังไว้ได้ คุณสามารถใช้การมาสก์ทั้งคำได้โดยแทนที่ `data_collator` ด้านบนด้วยคำที่เหมาะสม ซึ่งในกรณีนี้คุณควรลบบรรทัดแรกที่นี่:
+
+```py
+downsampled_dataset = downsampled_dataset.remove_columns(["word_ids"])
+eval_dataset = downsampled_dataset["test"].map(
+ insert_random_mask,
+ batched=True,
+ remove_columns=downsampled_dataset["test"].column_names,
+)
+eval_dataset = eval_dataset.rename_columns(
+ {
+ "masked_input_ids": "input_ids",
+ "masked_attention_mask": "attention_mask",
+ "masked_labels": "labels",
+ }
+)
+```
+
+จากนั้นเราสามารถตั้งค่าตัวโหลดข้อมูลได้ตามปกติ แต่เราจะใช้ `default_data_collator` จาก 🤗 Transformers สำหรับชุดการประเมิน:
+
+```python
+from torch.utils.data import DataLoader
+from transformers import default_data_collator
+
+batch_size = 64
+train_dataloader = DataLoader(
+ downsampled_dataset["train"],
+ shuffle=True,
+ batch_size=batch_size,
+ collate_fn=data_collator,
+)
+eval_dataloader = DataLoader(
+ eval_dataset, batch_size=batch_size, collate_fn=default_data_collator
+)
+```
+
+แบบที่นี่เราทำตามขั้นตอนมาตรฐานด้วย 🤗 Accelerate ลำดับแรกของธุรกิจคือการโหลดโมเดลที่ผ่านการฝึกอบรมเวอร์ชันใหม่:
+
+```
+model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
+```
+
+จากนั้นเราจำเป็นต้องระบุเครื่องมือเพิ่มประสิทธิภาพ เราจะใช้มาตรฐาน `AdamW`:
+
+```python
+from torch.optim import AdamW
+
+optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+ด้วยวัตถุเหล่านี้ ตอนนี้เราสามารถเตรียมทุกอย่างสำหรับการฝึกด้วยวัตถุ 'Accelerator':
+
+```python
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+เมื่อโมเดล เครื่องมือเพิ่มประสิทธิภาพ และตัวโหลดข้อมูลของเราได้รับการกำหนดค่าแล้ว เราก็สามารถระบุตัวกำหนดเวลาอัตราการเรียนรู้ได้ดังต่อไปนี้:
+
+```python
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+มีเพียงสิ่งสุดท้ายที่ต้องทำก่อนการฝึก: สร้างที่เก็บแบบจำลองบน Hugging Face Hub! เราสามารถใช้ไลบรารี 🤗 Hub เพื่อสร้างชื่อเต็มของ repo ของเราก่อน:
+
+```python
+from huggingface_hub import get_full_repo_name
+
+model_name = "distilbert-base-uncased-finetuned-imdb-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'lewtun/distilbert-base-uncased-finetuned-imdb-accelerate'
+```
+
+จากนั้นสร้างและโคลนพื้นที่เก็บข้อมูลโดยใช้คลาส `Repository` จาก 🤗 Hub:
+
+```python
+from huggingface_hub import Repository
+
+output_dir = model_name
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+เมื่อทำเสร็จแล้ว การเขียนลูปการฝึกอบรมและการประเมินผลทั้งหมดก็เป็นเรื่องง่าย:
+
+```python
+from tqdm.auto import tqdm
+import torch
+import math
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Training
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather(loss.repeat(batch_size)))
+
+ losses = torch.cat(losses)
+ losses = losses[: len(eval_dataset)]
+ try:
+ perplexity = math.exp(torch.mean(losses))
+ except OverflowError:
+ perplexity = float("inf")
+
+ print(f">>> Epoch {epoch}: Perplexity: {perplexity}")
+
+ # Save and upload
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+>>> Epoch 0: Perplexity: 11.397545307900472
+>>> Epoch 1: Perplexity: 10.904909330983092
+>>> Epoch 2: Perplexity: 10.729503505340409
+```
+
+เยี่ยมเลย เราสามารถประเมินความซับซ้อนในแต่ละ epoch ได้ และรับรองว่าการฝึกซ้อมหลายครั้งสามารถทำซ้ำได้!
+
+{/if}
+
+## การใช้งานโมเดลที่ปรับแต่งของเรา[[การใช้งานโมเดลที่ปรับแต่งของเรา]]
+
+คุณสามารถโต้ตอบกับโมเดลที่ได้รับการปรับแต่งของคุณโดยใช้วิดเจ็ตบน Hub หรือในเครื่องด้วย `pipeline` จาก 🤗 Transformers ลองใช้อันหลังเพื่อดาวน์โหลดโมเดลของเราโดยใช้ไปป์ไลน์ `fill-mask`:
+
+```python
+from transformers import pipeline
+
+mask_filler = pipeline(
+ "fill-mask", model="huggingface-course/distilbert-base-uncased-finetuned-imdb"
+)
+```
+
+จากนั้นเราจะป้อนข้อความตัวอย่าง "This is a great [MASK]" ให้กับไปป์ไลน์ และดูว่าคำทำนาย 5 อันดับแรกคืออะไร:
+
+```python
+preds = mask_filler(text)
+
+for pred in preds:
+ print(f">>> {pred['sequence']}")
+```
+
+```python out
+'>>> this is a great movie.'
+'>>> this is a great film.'
+'>>> this is a great story.'
+'>>> this is a great movies.'
+'>>> this is a great character.'
+```
+
+เรียบร้อย -- โมเดลของเราได้ปรับน้ำหนักอย่างชัดเจนเพื่อคาดเดาคำที่เกี่ยวข้องกับภาพยนตร์มากขึ้น!
+
+
+
+นี่เป็นการสรุปการทดลองครั้งแรกของเราด้วยการฝึกโมเดลภาษา ใน [ส่วนที่ 6](/course/th/chapter7/6) คุณจะได้เรียนรู้วิธีฝึกโมเดลการถดถอยอัตโนมัติ เช่น GPT-2 ตั้งแต่เริ่มต้น ไปที่นั่นถ้าคุณต้องการดูว่าคุณสามารถฝึกโมเดล Transformer ของคุณเองล่วงหน้าได้อย่างไร!
+
+
+
+✏️ **ลองดูสิ!** หากต้องการหาปริมาณประโยชน์ของการปรับโดเมน ให้ปรับแต่งตัวแยกประเภทบนป้ายกำกับ IMDb สำหรับทั้งจุดตรวจสอบ DistilBERT ที่ได้รับการฝึกมาแล้วและที่ได้รับการปรับแต่งอย่างละเอียด หากคุณต้องการทบทวนการจัดหมวดหมู่ข้อความ โปรดดู [บทที่ 3](/course/th/chapter3)
+
+
diff --git a/chapters/th/chapter7/4.mdx b/chapters/th/chapter7/4.mdx
new file mode 100644
index 000000000..3b0301f3d
--- /dev/null
+++ b/chapters/th/chapter7/4.mdx
@@ -0,0 +1,1001 @@
+
+
+# การแปลความหมาย[[การแปลความหมาย]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+ตอนนี้มาดำดิ่งสู่การแปล นี่เป็นอีกหนึ่ง [งานลำดับต่อลำดับ](/course/chapter1/7) ซึ่งหมายความว่าเป็นปัญหาที่สามารถกำหนดได้ว่าเป็นการไปจากลำดับหนึ่งไปอีกลำดับหนึ่ง ในแง่นั้น ปัญหาค่อนข้างใกล้เคียงกับ [การสรุป](/course/th/chapter7/6) และคุณสามารถปรับสิ่งที่เราจะเห็นที่นี่กับปัญหาตามลำดับอื่นๆ เช่น:
+
+- **การถ่ายโอนรูปแบบ**: การสร้างโมเดลที่ *แปล* ข้อความที่เขียนด้วยสไตล์หนึ่งไปเป็นอีกสไตล์หนึ่ง (เช่น จากเป็นทางการไปเป็นไม่เป็นทางการ หรือจากเช็คสเปียร์จากภาษาอังกฤษเป็นภาษาอังกฤษสมัยใหม่)
+- **การตอบคำถามเชิงสร้างสรรค์**: การสร้างแบบจำลองที่สร้างคำตอบสำหรับคำถามตามบริบท
+
+
+
+หากคุณมีคลังข้อความที่ใหญ่เพียงพอในสองภาษา (หรือมากกว่า) คุณสามารถฝึกโมเดลการแปลใหม่ตั้งแต่ต้นได้เหมือนกับที่เราฝึกในหัวข้อ [การสร้างแบบจำลองภาษาเชิงสาเหตุ](/course/th/chapter7/6) อย่างไรก็ตาม การปรับแต่งโมเดลการแปลที่มีอยู่อย่างละเอียดจะเร็วขึ้น ไม่ว่าจะเป็นโมเดลหลายภาษา เช่น mT5 หรือ mBART ที่คุณต้องการปรับแต่งให้เข้ากับคู่ภาษาเฉพาะ หรือแม้แต่โมเดลเฉพาะสำหรับการแปลจากภาษาหนึ่งเป็นอีกภาษาหนึ่ง ที่คุณต้องการปรับแต่งให้เข้ากับคลังข้อมูลเฉพาะของคุณ
+
+ในส่วนนี้ เราจะปรับแต่งโมเดล Marian ที่ได้รับการฝึกล่วงหน้าเพื่อแปลจากภาษาอังกฤษเป็นภาษาฝรั่งเศส (เนื่องจากพนักงาน Hugging Face จำนวนมากพูดทั้งสองภาษาเหล่านั้น) บน [ชุดข้อมูล KDE4](https://huggingface.co/datasets/kde4 ) ซึ่งเป็นชุดข้อมูลของไฟล์ที่แปลแล้วสำหรับ [แอป KDE](https://apps.kde.org/) แบบจำลองที่เราจะใช้ได้รับการฝึกอบรมล่วงหน้าในคลังข้อความภาษาฝรั่งเศสและอังกฤษขนาดใหญ่ที่นำมาจาก [ชุดข้อมูล Opus](https://opus.nlpl.eu/) ซึ่งมีชุดข้อมูล KDE4 จริงๆ แต่ถึงแม้ว่าโมเดลที่ได้รับการฝึกล่วงหน้าที่เราใช้จะได้เห็นข้อมูลนั้นในระหว่างการฝึกล่วงหน้าแล้ว เราก็จะเห็นว่าเราสามารถรับเวอร์ชันที่ดีขึ้นได้หลังจากการปรับแต่งอย่างละเอียด
+
+เมื่อเสร็จแล้วเราจะได้โมเดลที่สามารถทำนายได้ดังนี้:
+
+
+
+
+ +
+ +
+
+เช่นเดียวกับในส่วนก่อนหน้า คุณจะพบโมเดลจริงที่เราจะฝึกและอัปโหลดไปยัง Hub โดยใช้โค้ดด้านล่าง และตรวจสอบการคาดการณ์อีกครั้ง [ที่นี่](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## การเตรียมข้อมูล[[การเตรียมข้อมูล]]
+
+หากต้องการปรับแต่งหรือฝึกโมเดลการแปลตั้งแต่เริ่มต้น เราจำเป็นต้องมีชุดข้อมูลที่เหมาะกับงานนี้ ตามที่กล่าวไว้ก่อนหน้านี้ เราจะใช้ [ชุดข้อมูล KDE4](https://huggingface.co/datasets/kde4) ในส่วนนี้ แต่คุณสามารถปรับโค้ดเพื่อใช้ข้อมูลของคุณเองได้อย่างง่ายดาย ตราบใดที่คุณมีคู่กัน ของประโยคในสองภาษาที่คุณต้องการแปลจากและเป็นไปในนั้น ย้อนกลับไปที่ [บทที่ 5](/course/th/chapter5) หากคุณต้องการคำเตือนเกี่ยวกับวิธีการโหลดข้อมูลที่กำหนดเองใน `Dataset`.
+
+### ชุดข้อมูล KDE4[[ชุดข้อมูล-kde4]]
+
+ตามปกติ เราจะดาวน์โหลดชุดข้อมูลของเราโดยใช้ฟังก์ชัน `load_dataset()`:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+หากคุณต้องการทำงานกับคู่ภาษาอื่น คุณสามารถระบุภาษาเหล่านั้นด้วยรหัสของพวกเขาได้ ชุดข้อมูลนี้มีภาษาให้เลือกทั้งหมด 92 ภาษา คุณสามารถดูทั้งหมดได้โดยขยายแท็กภาษาใน [การ์ดชุดข้อมูล](https://huggingface.co/datasets/kde4)
+
+
+
+
+เช่นเดียวกับในส่วนก่อนหน้า คุณจะพบโมเดลจริงที่เราจะฝึกและอัปโหลดไปยัง Hub โดยใช้โค้ดด้านล่าง และตรวจสอบการคาดการณ์อีกครั้ง [ที่นี่](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr?text=This+plugin+allows+you+to+automatically+translate+web+pages+between+several+languages.).
+
+## การเตรียมข้อมูล[[การเตรียมข้อมูล]]
+
+หากต้องการปรับแต่งหรือฝึกโมเดลการแปลตั้งแต่เริ่มต้น เราจำเป็นต้องมีชุดข้อมูลที่เหมาะกับงานนี้ ตามที่กล่าวไว้ก่อนหน้านี้ เราจะใช้ [ชุดข้อมูล KDE4](https://huggingface.co/datasets/kde4) ในส่วนนี้ แต่คุณสามารถปรับโค้ดเพื่อใช้ข้อมูลของคุณเองได้อย่างง่ายดาย ตราบใดที่คุณมีคู่กัน ของประโยคในสองภาษาที่คุณต้องการแปลจากและเป็นไปในนั้น ย้อนกลับไปที่ [บทที่ 5](/course/th/chapter5) หากคุณต้องการคำเตือนเกี่ยวกับวิธีการโหลดข้อมูลที่กำหนดเองใน `Dataset`.
+
+### ชุดข้อมูล KDE4[[ชุดข้อมูล-kde4]]
+
+ตามปกติ เราจะดาวน์โหลดชุดข้อมูลของเราโดยใช้ฟังก์ชัน `load_dataset()`:
+
+```py
+from datasets import load_dataset
+
+raw_datasets = load_dataset("kde4", lang1="en", lang2="fr")
+```
+
+หากคุณต้องการทำงานกับคู่ภาษาอื่น คุณสามารถระบุภาษาเหล่านั้นด้วยรหัสของพวกเขาได้ ชุดข้อมูลนี้มีภาษาให้เลือกทั้งหมด 92 ภาษา คุณสามารถดูทั้งหมดได้โดยขยายแท็กภาษาใน [การ์ดชุดข้อมูล](https://huggingface.co/datasets/kde4)
+
+ +
+มาดูชุดข้อมูลกันดีกว่า:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+เรามีประโยค 210,173 คู่ แต่ในการแยกประโยคเดียว ดังนั้น เราจะต้องสร้างชุดการตรวจสอบของเราเอง ดังที่เราเห็นใน [บทที่ 5](/course/th/chapter5) `Dataset` มีเมธอด `train_test_split()` ที่สามารถช่วยเราได้ เราจะจัดเตรียมเมล็ดพันธุ์สำหรับการทำซ้ำ:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+เราสามารถเปลี่ยนชื่อคีย์ `"test"` เป็น `"validation"` ได้ดังนี้:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+ตอนนี้เรามาดูองค์ประกอบหนึ่งของชุดข้อมูลกัน:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+เราได้รับพจนานุกรมที่มีสองประโยคในคู่ภาษาที่เราขอ ความพิเศษประการหนึ่งของชุดข้อมูลนี้ซึ่งเต็มไปด้วยคำศัพท์ทางเทคนิคด้านวิทยาการคอมพิวเตอร์ก็คือคำศัพท์ทั้งหมดได้รับการแปลเป็นภาษาฝรั่งเศสทั้งหมด อย่างไรก็ตาม วิศวกรชาวฝรั่งเศสจะทิ้งคำเฉพาะด้านวิทยาการคอมพิวเตอร์ส่วนใหญ่เป็นภาษาอังกฤษเมื่อพวกเขาพูด ตัวอย่างเช่น คำว่า "threads" อาจปรากฏในประโยคภาษาฝรั่งเศส โดยเฉพาะอย่างยิ่งในการสนทนาทางเทคนิค แต่ในชุดข้อมูลนี้ มันถูกแปลเป็น "fils de discussion" ที่ถูกต้องมากขึ้น โมเดลที่ฝึกไว้ล่วงหน้าที่เราใช้ ซึ่งได้รับการฝึกฝนกับคลังประโยคภาษาฝรั่งเศสและอังกฤษที่มีขนาดใหญ่กว่า เลือกใช้ตัวเลือกที่ง่ายกว่าในการคงคำไว้ดังนี้:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+อีกตัวอย่างหนึ่งของพฤติกรรมนี้สามารถเห็นได้จากคำว่า "plugin" ซึ่งไม่ใช่คำภาษาฝรั่งเศสอย่างเป็นทางการ แต่เจ้าของภาษาส่วนใหญ่จะเข้าใจและไม่สนใจที่จะแปล
+ในชุดข้อมูล KDE4 คำนี้ได้รับการแปลเป็นภาษาฝรั่งเศสเป็นภาษา "module d'extension" ที่เป็นทางการมากขึ้น:
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+อย่างไรก็ตาม โมเดลที่ได้รับการฝึกล่วงหน้าของเรายังคงยึดตามคำภาษาอังกฤษที่กระชับและคุ้นเคย:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+น่าสนใจที่จะดูว่าโมเดลที่ได้รับการปรับแต่งของเรานั้นคำนึงถึงความเฉพาะเจาะจงของชุดข้อมูลหรือไม่ (เตือนไว้ก่อน: มันจะเป็นเช่นนั้น)
+
+
+
+
+
+✏️ **ตาคุณ!** อีกคำภาษาอังกฤษที่มักใช้ในภาษาฝรั่งเศสคือ "email" ค้นหาตัวอย่างแรกในชุดข้อมูลการฝึกอบรมที่ใช้คำนี้ มันแปลยังไงบ้าง? โมเดลที่ผ่านการฝึกอบรมจะแปลประโยคภาษาอังกฤษเดียวกันได้อย่างไร
+
+
+
+### การประมวลผลข้อมูล[[การประมวลผลข้อมูล]]
+
+
+
+ตอนนี้คุณควรรู้การเจาะลึกแล้ว: ข้อความทั้งหมดจำเป็นต้องแปลงเป็นชุดรหัสโทเค็นเพื่อให้แบบจำลองเข้าใจได้ สำหรับงานนี้ เราจะต้องสร้างโทเค็นทั้งอินพุตและเป้าหมาย ภารกิจแรกของเราคือสร้างวัตถุ `tokenizer` ของเรา ตามที่ระบุไว้ก่อนหน้านี้ เราจะใช้โมเดลฝึกภาษาอังกฤษแบบ Marian เป็นภาษาฝรั่งเศส หากคุณกำลังลองใช้โค้ดนี้กับคู่ภาษาอื่น ตรวจสอบให้แน่ใจว่าได้ปรับจุดตรวจสอบโมเดลแล้ว องค์กร [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) มีโมเดลมากกว่าพันรายการในหลายภาษา
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
+```
+
+คุณยังสามารถแทนที่ `model_checkpoint` ด้วยโมเดลอื่นๆ ที่คุณต้องการจาก [Hub](https://huggingface.co/models) หรือโฟลเดอร์ในเครื่องที่คุณได้บันทึกโมเดลที่ฝึกไว้ล่วงหน้าและ tokenizer
+
+
+
+💡 หากคุณใช้โทเค็นไนเซอร์หลายภาษา เช่น mBART, mBART-50 หรือ M2M100 คุณจะต้องตั้งค่ารหัสภาษาของอินพุตและเป้าหมายของคุณในโทเค็นโดยการตั้งค่า `tokenizer.src_lang` และ `tokenizer.tgt_lang` ทางด้านขวา ค่านิยม
+
+
+
+การจัดเตรียมข้อมูลของเราค่อนข้างตรงไปตรงมา มีเพียงสิ่งเดียวที่ต้องจำ คุณต้องแน่ใจว่า tokenizer ประมวลผลเป้าหมายในภาษาเอาต์พุต (ในที่นี้คือภาษาฝรั่งเศส) คุณสามารถทำได้โดยส่งเป้าหมายไปยังอาร์กิวเมนต์ `text_targets` ของเมธอด `__call__` ของ tokenizer
+
+หากต้องการดูวิธีการทำงาน เราจะประมวลผลตัวอย่างของแต่ละภาษาในชุดการฝึกอบรมหนึ่งตัวอย่าง:
+
+```python
+en_sentence = split_datasets["train"][1]["translation"]["en"]
+fr_sentence = split_datasets["train"][1]["translation"]["fr"]
+
+inputs = tokenizer(en_sentence, text_target=fr_sentence)
+inputs
+```
+
+```python out
+{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
+```
+
+ดังที่เราเห็น ผลลัพธ์มี ID อินพุตที่เกี่ยวข้องกับประโยคภาษาอังกฤษ ในขณะที่ ID ที่เกี่ยวข้องกับภาษาฝรั่งเศสจะถูกเก็บไว้ในฟิลด์ `labels` หากคุณลืมระบุว่าคุณกำลังโทเค็นป้ายกำกับ ป้ายเหล่านั้นจะถูกโทเค็นโดยอินพุตโทเค็นไนเซอร์ ซึ่งในกรณีของโมเดล Marian จะทำงานได้ไม่ดีเลย:
+
+```python
+wrong_targets = tokenizer(fr_sentence)
+print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
+print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
+```
+
+```python out
+['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
+['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
+```
+
+ดังที่เราเห็น การใช้ tokenizer ภาษาอังกฤษเพื่อประมวลผลประโยคภาษาฝรั่งเศสล่วงหน้าส่งผลให้มี token มากขึ้น เนื่องจาก tokenizer ไม่รู้จักคำภาษาฝรั่งเศสใดๆ (ยกเว้นคำที่ปรากฏในภาษาอังกฤษ เช่น "discussion")
+
+เนื่องจาก `inputs` เป็นพจนานุกรมที่มีคีย์ปกติของเรา (ID อินพุต มาสก์ความสนใจ ฯลฯ) ขั้นตอนสุดท้ายคือการกำหนดฟังก์ชันการประมวลผลล่วงหน้าที่เราจะนำไปใช้กับชุดข้อมูล:
+
+```python
+max_length = 128
+
+
+def preprocess_function(examples):
+ inputs = [ex["en"] for ex in examples["translation"]]
+ targets = [ex["fr"] for ex in examples["translation"]]
+ model_inputs = tokenizer(
+ inputs, text_target=targets, max_length=max_length, truncation=True
+ )
+ return model_inputs
+```
+
+โปรดทราบว่าเราตั้งค่าความยาวสูงสุดเท่ากันสำหรับอินพุตและเอาต์พุตของเรา เนื่องจากข้อความที่เรากำลังพูดถึงดูค่อนข้างสั้น เราจึงใช้ 128
+
+
+
+💡 หากคุณกำลังใช้โมเดล T5 (โดยเฉพาะอย่างยิ่ง หนึ่งในจุดตรวจสอบ `t5-xxx`) โมเดลจะคาดหวังว่าอินพุตข้อความจะมีคำนำหน้าระบุงานที่ทำอยู่ เช่น `translate: English to French:`
+
+
+
+
+
+⚠️ เราไม่ใส่ใจกับหน้ากากความสนใจของเป้าหมาย เนื่องจากโมเดลไม่ได้คาดหวังไว้ แต่ควรตั้งค่าป้ายกำกับที่สอดคล้องกับโทเค็นการเติมเป็น `-100` แทน เพื่อที่ป้ายเหล่านั้นจะถูกละเว้นในการคำนวณการสูญเสีย ผู้รวบรวมข้อมูลของเราจะดำเนินการนี้ในภายหลัง เนื่องจากเราใช้การเติมแบบไดนามิก แต่หากคุณใช้การเติมภายในที่นี่ คุณควรปรับฟังก์ชันการประมวลผลล่วงหน้าเพื่อตั้งค่าป้ายกำกับทั้งหมดที่สอดคล้องกับโทเค็นการเติมเป็น `-100`
+
+
+
+ตอนนี้เราสามารถใช้การประมวลผลล่วงหน้านั้นกับการแยกชุดข้อมูลทั้งหมดของเราได้ในคราวเดียว:
+
+```py
+tokenized_datasets = split_datasets.map(
+ preprocess_function,
+ batched=True,
+ remove_columns=split_datasets["train"].column_names,
+)
+```
+
+เมื่อข้อมูลได้รับการประมวลผลล่วงหน้าแล้ว เราก็พร้อมที่จะปรับแต่งโมเดลที่ฝึกไว้ล่วงหน้าของเราแล้ว!
+
+{#if fw === 'pt'}
+
+## การปรับแต่งโมเดลอย่างละเอียดด้วย `Trainer` API[[การปรับแต่งโมเดลอย่างละเอียดด้วย-trainer-api]]
+
+โค้ดจริงที่ใช้ `Trainer` จะเหมือนเดิม โดยมีการเปลี่ยนแปลงเพียงเล็กน้อย: เราใช้ [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) ที่นี่ ซึ่งเป็นคลาสย่อยของ `Trainer` ที่จะช่วยให้เราจัดการกับการประเมินได้อย่างเหมาะสม โดยใช้เมธอด `generate()` เพื่อทำนายเอาต์พุตจากอินพุต เราจะเจาะลึกรายละเอียดมากขึ้นเมื่อเราพูดถึงการคำนวณหน่วยเมตริก
+
+ก่อนอื่น เราต้องการโมเดลจริงเพื่อปรับแต่งอย่างละเอียด เราจะใช้ `AutoModel` API ตามปกติ:
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+## การปรับแต่งโมเดลอย่างละเอียดด้วย Keras[[การปรับแต่งโมเดลอย่างละเอียดด้วย-keras]]
+
+ก่อนอื่น เราต้องการโมเดลจริงเพื่อปรับแต่งอย่างละเอียด เราจะใช้ `AutoModel` API ตามปกติ:
+
+```py
+from transformers import TFAutoModelForSeq2SeqLM
+
+model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
+```
+
+
+
+💡 จุด checkpoint `Helsinki-NLP/opus-mt-en-fr` มีเพียงน้ำหนักของ PyTorch ดังนั้น
+คุณจะได้รับข้อผิดพลาดหากคุณพยายามโหลดโมเดลโดยไม่ใช้
+อาร์กิวเมนต์ `from_pt=True` ในเมธอด `from_pretrained()` เมื่อคุณระบุ
+`from_pt=True` ไลบรารีจะดาวน์โหลดและแปลงน้ำหนัก PyTorch สำหรับคุณโดยอัตโนมัติ อย่างที่คุณเห็น มันง่ายมากที่จะสลับไปมาระหว่าง
+เฟรมเวิร์กใน 🤗 Transformers!
+
+
+
+{/if}
+
+ปรดทราบว่าครั้งนี้ เรากำลังใช้แบบจำลองที่ได้รับการฝึกในงานแปลและสามารถใช้งานได้จริงแล้ว ดังนั้นจึงไม่มีคำเตือนเกี่ยวกับน้ำหนักที่หายไปหรือน้ำหนักที่เริ่มต้นใหม่
+
+### การรวบรวมข้อมูล[[การรวบรวมข้อมูล]]
+
+เราจะต้องมีตัวเปรียบเทียบข้อมูลเพื่อจัดการกับช่องว่างภายในสำหรับการจัดชุดแบบไดนามิก เราไม่สามารถใช้ `DataCollatorWithPadding` เหมือนใน [บทที่ 3](/course/th/chapter3) ในกรณีนี้ไม่ได้ เนื่องจากนั่นเป็นเพียงการเสริมอินพุตเท่านั้น (ID อินพุต, มาสก์ความสนใจ และ ID ประเภทโทเค็น) ฉลากของเราควรได้รับการบุให้มีความยาวสูงสุดที่พบในฉลาก และตามที่กล่าวไว้ก่อนหน้านี้ ค่าการเสริมที่ใช้ในการเสริมป้ายกำกับควรเป็น `-100` และไม่ใช่โทเค็นการเสริมของโทเค็น เพื่อให้แน่ใจว่าค่าที่เสริมไว้เหล่านั้นจะถูกละเว้นในการคำนวณการสูญเสีย
+
+ทั้งหมดนี้ทำโดย [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq) เช่นเดียวกับ `DataCollatorWithPadding` มันต้องใช้ `tokenizer` ที่ใช้ในการประมวลผลอินพุตล่วงหน้า แต่ก็ใช้ `model` ด้วย เนื่องจากตัวรวบรวมข้อมูลนี้ยังต้องรับผิดชอบในการเตรียม ID อินพุตตัวถอดรหัส ซึ่งเป็นเวอร์ชันที่ถูกเลื่อนของป้ายกำกับด้วยโทเค็นพิเศษที่จุดเริ่มต้น เนื่องจากการเปลี่ยนแปลงนี้ทำแตกต่างกันเล็กน้อยสำหรับสถาปัตยกรรมที่แตกต่างกัน `DataCollatorForSeq2Seq` จำเป็นต้องทราบอ็อบเจ็กต์ `model`:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
+```
+
+{/if}
+
+เพื่อทดสอบสิ่งนี้กับตัวอย่างบางส่วน เราเพียงเรียกมันในรายการตัวอย่างจากชุดการฝึกโทเค็นของเรา:
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
+batch.keys()
+```
+
+```python out
+dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
+```
+
+เราสามารถตรวจสอบได้ว่าฉลากของเราได้รับการเสริมความยาวสูงสุดของชุดโดยใช้ `-100`:
+
+```py
+batch["labels"]
+```
+
+```python out
+tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
+ -100, -100, -100, -100, -100, -100],
+ [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
+ 550, 7032, 5821, 7907, 12649, 0]])
+```
+
+และเรายังสามารถดู ID อินพุตของตัวถอดรหัสเพื่อดูว่าเป็นเวอร์ชันที่เลื่อนของป้ายกำกับ:
+
+```py
+batch["decoder_input_ids"]
+```
+
+```python out
+tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
+ 59513, 59513, 59513, 59513, 59513, 59513],
+ [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
+ 817, 550, 7032, 5821, 7907, 12649]])
+```
+
+ต่อไปนี้เป็นป้ายกำกับสำหรับองค์ประกอบที่หนึ่งและที่สองในชุดข้อมูลของเรา:
+
+```py
+for i in range(1, 3):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
+[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
+```
+
+{#if fw === 'pt'}
+
+เราจะส่ง `data_collator` นี้ไปยัง `Seq2SeqTrainer` ต่อไปเรามาดูตัวชี้วัดกัน
+
+{:else}
+
+ตอนนี้เราสามารถใช้ `data_collator` นี้เพื่อแปลงชุดข้อมูลแต่ละชุดของเราเป็น `tf.data.Dataset` พร้อมสำหรับการฝึกอบรม:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+tf_eval_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+{/if}
+
+
+### เมตริก[[เมตริก]]
+
+
+
+{#if fw === 'pt'}
+
+คุณลักษณะที่ `Seq2SeqTrainer` เพิ่มให้กับ `Trainer` ระดับซูเปอร์คลาสคือความสามารถในการใช้เมธอด `generate()` ในระหว่างการประเมินหรือการทำนาย ในระหว่างการฝึก โมเดลจะใช้ `decoder_input_ids` พร้อมกับมาส์กความสนใจเพื่อให้แน่ใจว่าจะไม่ใช้โทเค็นหลังจากโทเค็นที่พยายามคาดการณ์ เพื่อเร่งความเร็วในการฝึก ในระหว่างการอนุมาน เราจะไม่สามารถใช้สิ่งเหล่านั้นได้เนื่องจากเราไม่มีป้ายกำกับ ดังนั้นจึงเป็นความคิดที่ดีที่จะประเมินแบบจำลองของเราด้วยการตั้งค่าเดียวกัน
+
+ดังที่เราเห็นใน [บทที่ 1](/course/th/chapter1/6) ตัวถอดรหัสทำการอนุมานโดยการทำนายโทเค็นทีละรายการ ซึ่งเป็นสิ่งที่นำไปใช้เบื้องหลังใน 🤗 Transformers ด้วยเมธอด `generate()` `Seq2SeqTrainer` จะให้เราใช้วิธีการนั้นในการประเมินหากเราตั้งค่า `predict_with_generate=True`
+
+{/if}
+
+ตัวชี้วัดแบบดั้งเดิมที่ใช้สำหรับการแปลคือ [คะแนน BLEU](https://en.wikipedia.org/wiki/BLEU) ซึ่งนำมาใช้ใน [บทความปี 2002](https://aclanthology.org/P02-1040.pdf) โดย Kishore Papineni และคณะ คะแนน BLEU จะประเมินว่าคำแปลใกล้เคียงกับป้ายกำกับเพียงใด ไม่ได้วัดความชัดเจนหรือความถูกต้องทางไวยากรณ์ของผลลัพธ์ที่สร้างของแบบจำลอง แต่ใช้กฎทางสถิติเพื่อให้แน่ใจว่าคำทั้งหมดในผลลัพธ์ที่สร้างขึ้นจะปรากฏในเป้าหมายด้วย นอกจากนี้ ยังมีกฎที่ลงโทษการใช้คำเดียวกันซ้ำๆ หากไม่ซ้ำกันในเป้าหมายด้วย (เพื่อหลีกเลี่ยงรูปแบบที่ส่งออกประโยค เช่น `"the the the the"`) และประโยคเอาต์พุตที่สั้นกว่าที่อยู่ใน เป้าหมาย (เพื่อหลีกเลี่ยงโมเดลที่ส่งออกประโยคเช่น `"the"`)
+
+จุดอ่อนประการหนึ่งของ BLEU คือคาดว่าข้อความจะถูกโทเค็นไนซ์แล้ว ซึ่งทำให้ยากต่อการเปรียบเทียบคะแนนระหว่างโมเดลที่ใช้โทเค็นไนเซอร์ที่แตกต่างกัน ดังนั้น เมตริกที่ใช้บ่อยที่สุดสำหรับการเปรียบเทียบโมเดลการแปลในปัจจุบันคือ [SacreBLEU](https://github.com/mjpost/sacrebleu) ซึ่งจัดการกับจุดอ่อนนี้ (และอื่นๆ) ด้วยการกำหนดขั้นตอนโทเค็นให้เป็นมาตรฐาน หากต้องการใช้ตัวชี้วัดนี้ เราต้องติดตั้งไลบรารี SacreBLEU ก่อน:
+
+```py
+!pip install sacrebleu
+```
+
+จากนั้นเราสามารถโหลดมันผ่าน `evaluate.load()` เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3):
+
+```py
+import evaluate
+
+metric = evaluate.load("sacrebleu")
+```
+
+เมตริกนี้จะใช้ข้อความเป็นอินพุตและเป้าหมาย ได้รับการออกแบบมาเพื่อยอมรับเป้าหมายที่ยอมรับได้หลายเป้าหมาย เนื่องจากมักจะมีการแปลประโยคเดียวกันที่ยอมรับได้หลายรายการ ชุดข้อมูลที่เราใช้จะมีเพียงเป้าหมายเดียว แต่ไม่ใช่เรื่องแปลกใน NLP ที่จะค้นหาชุดข้อมูลที่มีหลายประโยคเป็นป้ายกำกับ ดังนั้นการคาดคะเนควรเป็นรายการประโยค แต่การอ้างอิงควรเป็นรายการประโยค
+
+มาทดสอบตัวอย่างกัน:
+
+```py
+predictions = [
+ "This plugin lets you translate web pages between several languages automatically."
+]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 46.750469682990165,
+ 'counts': [11, 6, 4, 3],
+ 'totals': [12, 11, 10, 9],
+ 'precisions': [91.67, 54.54, 40.0, 33.33],
+ 'bp': 0.9200444146293233,
+ 'sys_len': 12,
+ 'ref_len': 13}
+```
+
+ซึ่งได้คะแนน BLEU ที่ 46.75 ซึ่งค่อนข้างดี สำหรับการอ้างอิง โมเดล Transformer ดั้งเดิมในเอกสาร ["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf) ได้รับ คะแนน BLEU 41.8 ในงานแปลที่คล้ายกันระหว่างภาษาอังกฤษและภาษาฝรั่งเศส! (สำหรับข้อมูลเพิ่มเติมเกี่ยวกับตัวชี้วัดแต่ละรายการ เช่น `counts` และ `bp` โปรดดูที่ [พื้นที่เก็บข้อมูล SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74 ).) ในทางกลับกัน ถ้าเราลองใช้การทำนายที่ไม่ดีสองประเภท (การซ้ำหลายครั้งหรือสั้นเกินไป) ซึ่งมักจะมาจากโมเดลการแปล เราจะได้คะแนน BLEU ที่ค่อนข้างแย่:
+
+```py
+predictions = ["This This This This"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 1.683602693167689,
+ 'counts': [1, 0, 0, 0],
+ 'totals': [4, 3, 2, 1],
+ 'precisions': [25.0, 16.67, 12.5, 12.5],
+ 'bp': 0.10539922456186433,
+ 'sys_len': 4,
+ 'ref_len': 13}
+```
+
+```py
+predictions = ["This plugin"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 0.0,
+ 'counts': [2, 1, 0, 0],
+ 'totals': [2, 1, 0, 0],
+ 'precisions': [100.0, 100.0, 0.0, 0.0],
+ 'bp': 0.004086771438464067,
+ 'sys_len': 2,
+ 'ref_len': 13}
+```
+
+คะแนนสามารถอยู่ระหว่าง 0 ถึง 100 และยิ่งสูงก็ยิ่งดี
+
+{#if fw === 'tf'}
+
+หากต้องการรับจากเอาต์พุตของโมเดลเป็นข้อความที่หน่วยวัดสามารถใช้ได้ เราจะใช้เมธอด `tokenizer.batch_decode()` เราแค่ต้องทำความสะอาด `-100` ทั้งหมดในฉลาก โทเค็นไนเซอร์จะทำเช่นเดียวกันกับโทเค็นการเติมโดยอัตโนมัติ เรามากำหนดฟังก์ชันที่ใช้โมเดลและชุดข้อมูลของเราและคำนวณเมตริกจากโมเดลนั้น นอกจากนี้เรายังจะใช้เคล็ดลับที่เพิ่มประสิทธิภาพได้อย่างมาก ด้วยการคอมไพล์โค้ดการสร้างของเราด้วย [XLA](https://www.tensorflow.org/xla) ซึ่งเป็นคอมไพเลอร์พีชคณิตเชิงเส้นแบบเร่งของ TensorFlow XLA ใช้การปรับให้เหมาะสมต่างๆ กับกราฟการคำนวณของโมเดล และส่งผลให้มีการปรับปรุงความเร็วและการใช้หน่วยความจำอย่างมีนัยสำคัญ ตามที่อธิบายไว้ใน Hugging Face [บล็อก](https://huggingface.co/blog/tf-xla-generate) XLA ทำงานได้ดีที่สุดเมื่อรูปร่างอินพุตของเราไม่แตกต่างกันมากเกินไป เพื่อจัดการสิ่งนี้ เราจะแพดอินพุตของเราให้เป็นทวีคูณของ 128 และสร้างชุดข้อมูลใหม่ด้วยตัวเปรียบเทียบการแพด จากนั้นเราจะใช้มัณฑนากร `@tf.function(jit_compile=True)` กับฟังก์ชันการสร้างของเรา ซึ่ง ทำเครื่องหมายฟังก์ชันทั้งหมดสำหรับการคอมไพล์ด้วย XLA
+
+```py
+import numpy as np
+import tensorflow as tf
+from tqdm import tqdm
+
+generation_data_collator = DataCollatorForSeq2Seq(
+ tokenizer, model=model, return_tensors="tf", pad_to_multiple_of=128
+)
+
+tf_generate_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=generation_data_collator,
+ shuffle=False,
+ batch_size=8,
+)
+
+
+@tf.function(jit_compile=True)
+def generate_with_xla(batch):
+ return model.generate(
+ input_ids=batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_new_tokens=128,
+ )
+
+
+def compute_metrics():
+ all_preds = []
+ all_labels = []
+
+ for batch, labels in tqdm(tf_generate_dataset):
+ predictions = generate_with_xla(batch)
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = labels.numpy()
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ all_preds.extend(decoded_preds)
+ all_labels.extend(decoded_labels)
+
+ result = metric.compute(predictions=all_preds, references=all_labels)
+ return {"bleu": result["score"]}
+```
+
+{:else}
+
+หากต้องการรับจากเอาต์พุตของโมเดลเป็นข้อความที่หน่วยวัดสามารถใช้ได้ เราจะใช้เมธอด `tokenizer.batch_decode()` เราเพียงแค่ต้องล้าง `-100` ทั้งหมดในป้ายกำกับ (โทเค็นจะทำเช่นเดียวกันกับโทเค็นการเติมโดยอัตโนมัติ):
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # In case the model returns more than the prediction logits
+ if isinstance(preds, tuple):
+ preds = preds[0]
+
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+ # Replace -100s in the labels as we can't decode them
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ return {"bleu": result["score"]}
+```
+
+{/if}
+
+เมื่อเสร็จแล้ว เราก็พร้อมที่จะปรับแต่งโมเดลของเรา!
+
+
+### การปรับแต่งโมเดลอย่างละเอียด[[การปรับแต่งโมเดลอย่างละเอียด]]
+
+ขั้นตอนแรกคือการเข้าสู่ระบบ Hugging Face เพื่อให้คุณสามารถอัปโหลดผลลัพธ์ของคุณไปยัง Model Hub มีฟังก์ชันอำนวยความสะดวกที่จะช่วยคุณในเรื่องนี้ในโน้ตบุ๊ก:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+นี่จะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองการเข้าสู่ระบบ Hugging Face ของคุณได้
+
+หากคุณไม่ได้ทำงานในโน้ตบุ๊ก เพียงพิมพ์บรรทัดต่อไปนี้ในเทอร์มินัลของคุณ:
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'tf'}
+
+ก่อนที่เราจะเริ่มต้น มาดูกันว่าเราได้รับผลลัพธ์ประเภทใดจากโมเดลของเราโดยไม่มีการฝึกอบรมใดๆ:
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 33.26983701454733}
+```
+
+เมื่อเสร็จแล้ว เราก็เตรียมทุกอย่างที่จำเป็นเพื่อคอมไพล์และฝึกโมเดลของเราได้ โปรดสังเกตการใช้ `tf.keras.mixed_precision.set_global_policy("mixed_float16")` -- ซึ่งจะเป็นการบอกให้ Keras ฝึกฝนการใช้ float16 ซึ่งสามารถเร่งความเร็วได้อย่างมากบน GPU ที่รองรับ (Nvidia 20xx/V100 หรือใหม่กว่า)
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
+# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
+# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=5e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Train in mixed-precision float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+ต่อไป เราจะกำหนด `PushToHubCallback` เพื่ออัปโหลดโมเดลของเราไปยัง Hub ในระหว่างการฝึก ดังที่เราเห็นใน [ส่วนที่ 2]((/course/th/chapter7/2)) จากนั้นเราก็ปรับโมเดลให้เข้ากับ callback นั้น:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(
+ output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
+)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+โปรดทราบว่าคุณสามารถระบุชื่อของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` ถึง `Seq2SeqTrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นที่นี่จะเป็น `"sgugger/marian-finetuned-kde4-en-to-fr"` (ซึ่งเป็นโมเดลที่เราเชื่อมโยงด้วย ในตอนต้นของส่วนนี้)
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อเรียก `model.fit()` และจะต้องตั้งชื่อใหม่
+
+
+
+สุดท้ายนี้ เรามาดูกันว่าเมตริกของเราจะเป็นอย่างไรเมื่อการฝึกอบรมเสร็จสิ้นแล้ว:
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 57.334066271545865}
+```
+
+ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณปรับแต่งโมเดลในงานแปลได้สำเร็จ ขอแสดงความยินดีด้วย!
+
+{:else}
+
+เมื่อเสร็จแล้ว เราก็สามารถกำหนด `Seq2SeqTrainingArguments` ของเราได้ เช่นเดียวกับ `Trainer` เราใช้คลาสย่อยของ `TrainingArguments` ที่มีตัวแปลเพิ่มเติมสองสามตัว:
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+args = Seq2SeqTrainingArguments(
+ f"marian-finetuned-kde4-en-to-fr",
+ evaluation_strategy="no",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=64,
+ weight_decay=0.01,
+ save_total_limit=3,
+ num_train_epochs=3,
+ predict_with_generate=True,
+ fp16=True,
+ push_to_hub=True,
+)
+```
+
+นอกเหนือจากไฮเปอร์พารามิเตอร์ตามปกติ (เช่น learning rate, number of epochs, batch size, and some weight decay), ต่อไปนี้คือการเปลี่ยนแปลงเล็กๆ น้อยๆ เมื่อเทียบกับสิ่งที่เราเห็นในส่วนที่แล้ว:
+
+- เราไม่ได้กำหนดการประเมินเป็นประจำ เนื่องจากการประเมินจะใช้เวลาระยะหนึ่ง เราจะประเมินแบบจำลองของเราหนึ่งครั้งก่อนการฝึกและหลังการฝึก
+- เราตั้งค่า `fp16=True` ซึ่งจะช่วยเร่งความเร็วการฝึกอบรมบน GPU สมัยใหม่
+- เราตั้งค่า `predict_with_generate=True` ตามที่กล่าวไว้ข้างต้น
+- เราใช้ `push_to_hub=True` เพื่ออัปโหลดโมเดลไปยัง Hub เมื่อสิ้นสุดแต่ละ epoch
+
+โปรดทราบว่าคุณสามารถระบุชื่อเต็มของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` ถึง `Seq2SeqTrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นในกรณีของเราจะเป็น `"sgugger/marian-finetuned-kde4-en-to-fr"` (ซึ่งเป็นโมเดลที่เรา เชื่อมโยงกับตอนต้นของส่วนนี้)
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อกำหนด `Seq2SeqTrainer` ของคุณและจะต้องตั้งชื่อใหม่
+
+
+
+
+ในที่สุด เราก็ส่งทุกอย่างไปที่ `Seq2SeqTrainer`:
+
+```python
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ model,
+ args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+ก่อนการฝึก เราจะดูคะแนนที่โมเดลของเราได้รับก่อน เพื่อตรวจสอบอีกครั้งว่าเราไม่ได้ทำให้สิ่งต่าง ๆ แย่ลงด้วยการปรับแต่งของเรา คำสั่งนี้จะใช้เวลาสักครู่ ดังนั้นคุณจึงสามารถดื่มกาแฟในขณะที่ดำเนินการได้:
+
+```python
+trainer.evaluate(max_length=max_length)
+```
+
+```python out
+{'eval_loss': 1.6964408159255981,
+ 'eval_bleu': 39.26865061007616,
+ 'eval_runtime': 965.8884,
+ 'eval_samples_per_second': 21.76,
+ 'eval_steps_per_second': 0.341}
+```
+
+คะแนน BLEU ที่ 39 ก็ไม่ได้แย่นัก ซึ่งสะท้อนให้เห็นว่าแบบจำลองของเราแปลประโยคภาษาอังกฤษเป็นภาษาฝรั่งเศสได้ดีอยู่แล้ว
+
+ต่อไปคือการฝึกอบรมซึ่งจะใช้เวลาสักหน่อย:
+
+```python
+trainer.train()
+```
+
+โปรดทราบว่าในขณะที่การฝึกเกิดขึ้น แต่ละครั้งที่มีการบันทึกโมเดล (ที่นี่ ทุก epoch) โมเดลจะถูกอัปโหลดไปยัง Hub ในเบื้องหลัง ด้วยวิธีนี้ คุณจะสามารถกลับมาฝึกต่อในเครื่องอื่นได้หากจำเป็น
+
+เมื่อการฝึกอบรมเสร็จสิ้น เราจะประเมินแบบจำลองของเราอีกครั้ง หวังว่าเราจะได้เห็นการปรับปรุงในคะแนน BLEU
+
+```py
+trainer.evaluate(max_length=max_length)
+```
+
+```python out
+{'eval_loss': 0.8558505773544312,
+ 'eval_bleu': 52.94161337775576,
+ 'eval_runtime': 714.2576,
+ 'eval_samples_per_second': 29.426,
+ 'eval_steps_per_second': 0.461,
+ 'epoch': 3.0}
+```
+
+นั่นเป็นการปรับปรุงเกือบ 14 แต้มซึ่งดีมาก
+
+สุดท้ายนี้ เราใช้เมธอด `push_to_hub()` เพื่อให้แน่ใจว่าเราจะอัปโหลดโมเดลเวอร์ชันล่าสุด `Trainer` ยังร่างการ์ดโมเดลพร้อมผลการประเมินทั้งหมดแล้วอัปโหลด การ์ดโมเดลนี้มีข้อมูลเมตาที่ช่วยให้ Model Hub เลือกวิดเจ็ตสำหรับการสาธิตการอนุมาน โดยปกติแล้ว ไม่จำเป็นต้องพูดอะไร เนื่องจากสามารถอนุมานวิดเจ็ตที่ถูกต้องจากคลาสโมเดลได้ แต่ในกรณีนี้ สามารถใช้คลาสโมเดลเดียวกันสำหรับปัญหาลำดับต่อลำดับทุกประเภท ดังนั้นเราจึงระบุว่าเป็นการแปล แบบอย่าง:
+
+```py
+trainer.push_to_hub(tags="translation", commit_message="Training complete")
+```
+
+คำสั่งนี้จะส่งคืน URL ของการคอมมิตที่เพิ่งทำไป หากคุณต้องการตรวจสอบ:
+
+```python out
+'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
+```
+
+ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณปรับแต่งโมเดลในงานแปลได้สำเร็จ ขอแสดงความยินดีด้วย!
+
+หากคุณต้องการเจาะลึกลงไปในลูปการฝึกซ้อมมากขึ้น ตอนนี้เราจะแสดงวิธีทำสิ่งเดียวกันโดยใช้ 🤗 Accelerate
+
+{/if}
+
+{#if fw === 'pt'}
+
+## การวนลูปฝึกอบรมแบบกำหนดเอง[[การวนลูปฝึกอบรมแบบกำหนดเอง]]
+
+ตอนนี้เรามาดูวงจรการฝึกซ้อมทั้งหมดกัน เพื่อให้คุณปรับแต่งส่วนต่างๆ ที่ต้องการได้อย่างง่ายดาย มันจะดูเหมือนกับสิ่งที่เราทำใน [ส่วนที 2](/course/th/chapter7/2) และ [บทที่ 3](/course/th/chapter3/4) มาก
+
+### เตรียมทุกอย่างเพื่อการฝึก[[เตรียมทุกอย่างเพื่อการฝึก]]
+
+คุณเคยเห็นทั้งหมดนี้มาสองสามครั้งแล้ว ดังนั้นเราจะอธิบายโค้ดอย่างรวดเร็ว ก่อนอื่น เราจะสร้าง `DataLoader`s จากชุดข้อมูลของเรา หลังจากตั้งค่าชุดข้อมูลเป็นรูปแบบ `"torch"` แล้ว เราก็จะได้ PyTorch tensors:
+
+```py
+from torch.utils.data import DataLoader
+
+tokenized_datasets.set_format("torch")
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+ต่อไป เราจะสร้างโมเดลของเราขึ้นมาใหม่ เพื่อให้แน่ใจว่าเราจะไม่ทำการปรับแต่งแบบละเอียดจากเมื่อก่อนอีกต่อไป แต่เริ่มต้นจากโมเดลที่ได้รับการฝึกไว้ล่วงหน้าอีกครั้ง:
+
+```py
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+จากนั้นเราจะต้องมีเครื่องมือเพิ่มประสิทธิภาพ:
+
+```py
+from transformers import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+เมื่อเรามีอ็อบเจ็กต์ทั้งหมดแล้ว เราก็สามารถส่งมันไปที่เมธอด `accelerator.prepare()` ได้ โปรดทราบว่าหากคุณต้องการฝึก TPU ในสมุดบันทึก Colab คุณจะต้องย้ายโค้ดทั้งหมดนี้ไปยังฟังก์ชันการฝึก และไม่ควรเรียกใช้เซลล์ใดๆ ที่สร้างอินสแตนซ์ `Accelerator`.
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+ตอนนี้เราได้ส่ง `train_dataloader` ไปที่ `accelerator.prepare()` แล้ว เราสามารถใช้ความยาวของมันเพื่อคำนวณจำนวนขั้นตอนการฝึกได้ โปรดจำไว้ว่าเราควรทำเช่นนี้เสมอหลังจากเตรียม dataloader เนื่องจากวิธีการดังกล่าวจะเปลี่ยนความยาวของ `DataLoader` เราใช้กำหนดการเชิงเส้นแบบคลาสสิกจากอัตราการเรียนรู้ถึง 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+สุดท้ายนี้ ในการผลักดันโมเดลของเราไปที่ Hub เราจะต้องสร้างออบเจ็กต์ `Repository` ในโฟลเดอร์ที่ใช้งานได้ ขั้นแรกให้เข้าสู่ระบบ Hugging Face Hub หากคุณยังไม่ได้เข้าสู่ระบบ เราจะกำหนดชื่อที่เก็บจาก ID โมเดลที่เราต้องการให้กับโมเดลของเรา (อย่าลังเลที่จะแทนที่ `repo_name` ด้วยตัวเลือกของคุณเอง เพียงต้องมีชื่อผู้ใช้ของคุณ ซึ่งเป็นสิ่งที่ฟังก์ชัน `get_full_repo_name()` ทำ ):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
+```
+
+จากนั้นเราสามารถโคลนพื้นที่เก็บข้อมูลนั้นในโฟลเดอร์ในเครื่องได้ หากมีอยู่แล้ว โฟลเดอร์ในเครื่องนี้ควรเป็นโคลนของพื้นที่เก็บข้อมูลที่เรากำลังทำงานด้วย:
+
+```py
+output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+ตอนนี้เราสามารถอัปโหลดทุกสิ่งที่เราบันทึกไว้ใน `output_dir` ได้โดยการเรียกเมธอด `repo.push_to_hub()` ซึ่งจะช่วยให้เราอัปโหลดโมเดลระดับกลางในตอนท้ายของแต่ละ epoch ได้
+
+### วงจรการฝึกอบรม[[วงจรการฝึกอบรม]]
+
+ตอนนี้เราพร้อมที่จะเขียนลูปการฝึกอบรมฉบับเต็มแล้ว เพื่อให้ส่วนการประเมินง่ายขึ้น เราได้กำหนดฟังก์ชัน `postprocess()` นี้ ซึ่งใช้การคาดการณ์และป้ายกำกับ และแปลงเป็นรายการสตริงที่ออบเจ็กต์ `metric` ของเราจะคาดหวัง:
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.cpu().numpy()
+ labels = labels.cpu().numpy()
+
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+
+ # Replace -100 in the labels as we can't decode them.
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ return decoded_preds, decoded_labels
+```
+
+วงจรการฝึกอบรมมีลักษณะคล้ายกับใน [ส่วนที่ 2](/course/th/chapter7/2) และ [บทที่ 3](/course/th/chapter3) มาก โดยมีความแตกต่างเล็กน้อยในส่วนการประเมิน ดังนั้นเรามาเน้นที่เรื่องนั้นกันดีกว่า
+
+สิ่งแรกที่ควรทราบคือเราใช้เมธอด `generate()` เพื่อคำนวณการคาดการณ์ แต่นี่เป็นวิธีการในโมเดลพื้นฐานของเรา ไม่ใช่โมเดลที่ห่อ 🤗 Accelerate สร้างขึ้นในเมธอด `prepare()` นั่นคือสาเหตุที่เราแกะโมเดลออกก่อน แล้วจึงเรียกเมธอดนี้
+
+อย่างที่สองก็คือ เช่นเดียวกับ [การจำแนกโทเค็น](/course/th/chapter7/2) สองกระบวนการอาจมีการเสริมอินพุตและป้ายกำกับเป็นรูปร่างที่แตกต่างกัน ดังนั้นเราจึงใช้ `accelerator.pad_across_processes()` เพื่อทำการคาดการณ์และป้ายกำกับ รูปร่างเดียวกันก่อนที่จะเรียกเมธอด `gather()` หากเราไม่ทำเช่นนี้ การประเมินจะเกิดข้อผิดพลาดหรือหยุดทำงานตลอดไป
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Training
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in tqdm(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_length=128,
+ )
+ labels = batch["labels"]
+
+ # Necessary to pad predictions and labels for being gathered
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(generated_tokens)
+ labels_gathered = accelerator.gather(labels)
+
+ decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ results = metric.compute()
+ print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
+
+ # Save and upload
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+epoch 0, BLEU score: 53.47
+epoch 1, BLEU score: 54.24
+epoch 2, BLEU score: 54.44
+```
+
+เมื่อเสร็จแล้ว คุณควรมีโมเดลที่มีผลลัพธ์ค่อนข้างคล้ายกับโมเดลที่ได้รับการฝึกด้วย `Seq2SeqTrainer` คุณสามารถตรวจสอบอันที่เราฝึกได้โดยใช้โค้ดนี้ที่ [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate) และหากคุณต้องการทดสอบการปรับแต่งใดๆ ในลูปการฝึก คุณสามารถนำไปใช้ได้โดยตรงโดยแก้ไขโค้ดที่แสดงด้านบน!
+
+{/if}
+
+## การใช้โมเดลที่ปรับแต่งแล้ว[[การใช้โมเดลที่ปรับแต่งแล้ว]]
+
+เราได้แสดงให้คุณเห็นแล้วว่าคุณสามารถใช้โมเดลที่เราปรับแต่งอย่างละเอียดบน Model Hub ด้วยวิดเจ็ตการอนุมานได้อย่างไร หากต้องการใช้ภายในเครื่องใน `pipeline` เราเพียงแค่ต้องระบุตัวระบุโมเดลที่เหมาะสม:
+
+```py
+from transformers import pipeline
+
+# Replace this with your own checkpoint
+model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut, développer les fils de discussion'}]
+```
+
+ตามที่คาดไว้ โมเดลที่ได้รับการฝึกล่วงหน้าของเราจะปรับความรู้ให้เข้ากับคลังข้อมูลที่เราปรับแต่ง และแทนที่จะปล่อยให้คำว่า "threads" ในภาษาอังกฤษเพียงอย่างเดียว ตอนนี้กลับแปลเป็นเวอร์ชันทางการของภาษาฝรั่งเศส เช่นเดียวกับ "plugin":
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
+```
+
+อีกตัวอย่างที่ดีของการปรับใช้โดเมน!
+
+
+
+✏️ **ตาคุณแล้ว!** โมเดลส่งคืนอะไรในตัวอย่างที่มีคำว่า "email" ที่คุณระบุไว้ก่อนหน้านี้
+
+
diff --git a/chapters/th/chapter7/5.mdx b/chapters/th/chapter7/5.mdx
new file mode 100644
index 000000000..090f19d48
--- /dev/null
+++ b/chapters/th/chapter7/5.mdx
@@ -0,0 +1,1072 @@
+
+
+# การสรุปความหมาย[[การสรุปความหมาย]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+
+ในส่วนนี้ เราจะมาดูกันว่าโมเดล Transformer สามารถใช้เพื่อย่อเอกสารขนาดยาวให้เป็นบทสรุปได้อย่างไร งานที่เรียกว่า _text summarization_ นี่เป็นหนึ่งในงาน NLP ที่ท้าทายที่สุด เนื่องจากต้องใช้ความสามารถที่หลากหลาย เช่น การทำความเข้าใจข้อความที่ยาว และการสร้างข้อความที่สอดคล้องกันซึ่งรวบรวมหัวข้อหลักในเอกสาร อย่างไรก็ตาม เมื่อทำได้ดี การสรุปข้อความเป็นเครื่องมืออันทรงพลังที่สามารถเพิ่มความเร็วให้กับกระบวนการทางธุรกิจต่างๆ โดยแบ่งเบาภาระของผู้เชี่ยวชาญโดเมนในการอ่านเอกสารขนาดยาวอย่างละเอียด
+
+
+
+แม้ว่าจะมีโมเดลที่ได้รับการปรับแต่งอย่างละเอียดสำหรับการสรุปอยู่แล้วบน [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads) แต่โมเดลเกือบทั้งหมดเหมาะสำหรับเอกสารภาษาอังกฤษเท่านั้น ดังนั้น เพื่อเพิ่มความแปลกใหม่ในส่วนนี้ เราจะฝึกโมเดลสองภาษาสำหรับภาษาอังกฤษและสเปน ในตอนท้ายของส่วนนี้ คุณจะมี [model](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es) ที่สามารถสรุปบทวิจารณ์ของลูกค้าได้เหมือนกับที่แสดงไว้ที่นี่ :
+
+
+
+ดังที่เราจะเห็นว่าการสรุปเหล่านี้มีความกระชับเนื่องจากได้เรียนรู้จากชื่อที่ลูกค้าระบุไว้ในการวิจารณ์ผลิตภัณฑ์ของตน เริ่มต้นด้วยการรวบรวมคลังข้อมูลสองภาษาที่เหมาะสมสำหรับงานนี้
+
+## การเตรียมคลังข้อมูลหลายภาษา[[การเตรียมคลังข้อมูลหลายภาษา]]
+
+เราจะใช้ [Multilingual Amazon Reviews Corpus](https://huggingface.co/datasets/amazon_reviews_multi) เพื่อสร้างตัวสรุปสองภาษาของเรา คลังข้อมูลนี้ประกอบด้วยบทวิจารณ์ผลิตภัณฑ์ของ Amazon ในหกภาษา และโดยทั่วไปจะใช้เพื่อเปรียบเทียบตัวแยกประเภทหลายภาษา อย่างไรก็ตาม เนื่องจากการรีวิวแต่ละครั้งมีชื่อย่อประกอบ เราจึงสามารถใช้ชื่อดังกล่าวเป็นบทสรุปเป้าหมายเพื่อให้โมเดลของเราเรียนรู้ได้! ในการเริ่มต้น ให้ดาวน์โหลดชุดย่อยภาษาอังกฤษและสเปนจาก Hugging Face Hub:
+
+```python
+from datasets import load_dataset
+
+spanish_dataset = load_dataset("amazon_reviews_multi", "es")
+english_dataset = load_dataset("amazon_reviews_multi", "en")
+english_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 200000
+ })
+ validation: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 5000
+ })
+ test: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 5000
+ })
+})
+```
+
+อย่างที่คุณเห็น สำหรับแต่ละภาษา มีบทวิจารณ์ 200,000 รายการสำหรับการแยก 'train' และ 5,000 บทวิจารณ์สำหรับการแยก `validation` และ `test` แต่ละรายการ ข้อมูลบทวิจารณ์ที่เราสนใจมีอยู่ในคอลัมน์ `review_body` และ `review_title` ลองมาดูตัวอย่างบางส่วนโดยการสร้างฟังก์ชันง่ายๆ ที่จะสุ่มตัวอย่างจากชุดการฝึกด้วยเทคนิคที่เราเรียนรู้ใน [บทที่ 5](/course/th/chapter5):
+
+```python
+def show_samples(dataset, num_samples=3, seed=42):
+ sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
+ for example in sample:
+ print(f"\n'>> Title: {example['review_title']}'")
+ print(f"'>> Review: {example['review_body']}'")
+
+
+show_samples(english_dataset)
+```
+
+```python out
+'>> Title: Worked in front position, not rear'
+'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
+
+'>> Title: meh'
+'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
+
+'>> Title: Can\'t beat these for the money'
+'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
+```
+
+
+
+✏️ **ลองดูสิ!** เปลี่ยนการสุ่ม seed ในคำสั่ง `Dataset.shuffle()` เพื่อสำรวจบทวิจารณ์อื่นๆ ในคลังข้อมูล หากคุณเป็นผู้พูดภาษาสเปน ลองดูบทวิจารณ์บางส่วนใน `spanish_dataset` เพื่อดูว่าชื่อต่างๆ ดูเหมือนเป็นบทสรุปที่สมเหตุสมผลหรือไม่
+
+
+
+ตัวอย่างนี้แสดงความหลากหลายของบทวิจารณ์ที่มักพบทางออนไลน์ ตั้งแต่เชิงบวกไปจนถึงเชิงลบ (และทุกอย่างในระหว่างนั้น!) แม้ว่าตัวอย่างที่มีชื่อ "meh" จะไม่ได้ให้ข้อมูลมากนัก แต่ชื่ออื่นๆ ก็ดูเหมือนเป็นการสรุปบทวิจารณ์ที่ดีพอสมควร การฝึกอบรมโมเดลการสรุปสำหรับการตรวจสอบทั้งหมด 400,000 รายการอาจใช้เวลานานเกินไปบน GPU ตัวเดียว ดังนั้น เราจะมุ่งเน้นไปที่การสร้างข้อมูลสรุปสำหรับโดเมนเดียวของผลิตภัณฑ์แทน เพื่อให้เข้าใจว่าเราสามารถเลือกโดเมนใดได้ ให้แปลง `english_dataset` เป็น `pandas.DataFrame` และคำนวณจำนวนบทวิจารณ์ต่อหมวดหมู่ผลิตภัณฑ์:
+
+```python
+english_dataset.set_format("pandas")
+english_df = english_dataset["train"][:]
+# Show counts for top 20 products
+english_df["product_category"].value_counts()[:20]
+```
+
+```python out
+home 17679
+apparel 15951
+wireless 15717
+other 13418
+beauty 12091
+drugstore 11730
+kitchen 10382
+toy 8745
+sports 8277
+automotive 7506
+lawn_and_garden 7327
+home_improvement 7136
+pet_products 7082
+digital_ebook_purchase 6749
+pc 6401
+electronics 6186
+office_product 5521
+shoes 5197
+grocery 4730
+book 3756
+Name: product_category, dtype: int64
+```
+
+สินค้ายอดนิยมในชุดข้อมูลภาษาอังกฤษคือสินค้าในครัวเรือน เสื้อผ้า และอุปกรณ์อิเล็กทรอนิกส์ไร้สาย อย่างไรก็ตาม เพื่อให้ยึดถือธีมของ Amazon ต่อไป เราจะมุ่งเน้นไปที่การสรุปบทวิจารณ์หนังสือ เพราะนี่คือสิ่งที่บริษัทก่อตั้งขึ้น! เราเห็นหมวดหมู่ผลิตภัณฑ์สองหมวดหมู่ที่เหมาะกับใบเรียกเก็บเงิน (`หนังสือ` และ `digital_ebook_purchase`) ดังนั้น เรามากรองชุดข้อมูลทั้งสองภาษาสำหรับผลิตภัณฑ์เหล่านี้เท่านั้น ดังที่เราเห็นใน [บทที่ 5](/course/th/chapter5) ฟังก์ชัน `Dataset.filter()` ช่วยให้เราสามารถแบ่งชุดข้อมูลได้อย่างมีประสิทธิภาพมาก ดังนั้นเราจึงกำหนดฟังก์ชันง่ายๆ เพื่อทำสิ่งนี้ได้:
+
+```python
+def filter_books(example):
+ return (
+ example["product_category"] == "book"
+ or example["product_category"] == "digital_ebook_purchase"
+ )
+```
+
+ตอนนี้เมื่อเราใช้ฟังก์ชันนี้กับ `english_dataset` และ `spanish_dataset` ผลลัพธ์จะมีเฉพาะแถวที่เกี่ยวข้องกับหมวดหมู่หนังสือ ก่อนที่จะใช้ตัวกรอง มาเปลี่ยนรูปแบบของ `english_dataset` จาก `"pandas"` กลับไปเป็น `"arrow"`:
+
+```python
+english_dataset.reset_format()
+```
+
+จากนั้น เราสามารถใช้ฟังก์ชันตัวกรอง และเพื่อเป็นการตรวจสอบความเหมาะสม เราจะตรวจสอบตัวอย่างบทวิจารณ์เพื่อดูว่าเกี่ยวข้องกับหนังสือจริงหรือไม่:
+
+```python
+spanish_books = spanish_dataset.filter(filter_books)
+english_books = english_dataset.filter(filter_books)
+show_samples(english_books)
+```
+
+```python out
+'>> Title: I\'m dissapointed.'
+'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
+
+'>> Title: Good art, good price, poor design'
+'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
+
+'>> Title: Helpful'
+'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
+```
+
+โอเค เราจะเห็นว่าบทวิจารณ์ไม่ได้เกี่ยวกับหนังสืออย่างเคร่งครัด และอาจอ้างถึงสิ่งต่างๆ เช่น ปฏิทินและแอปพลิเคชันอิเล็กทรอนิกส์ เช่น OneNote อย่างไรก็ตาม ดูเหมือนว่าโดเมนจะมีสิทธิ์ในการฝึกอบรมโมเดลการสรุป ก่อนที่เราจะดูโมเดลต่างๆ ที่เหมาะกับงานนี้ เรามีการเตรียมข้อมูลขั้นตอนสุดท้ายที่ต้องทำ: รวมบทวิจารณ์ภาษาอังกฤษและสเปนเป็นออบเจ็กต์ `DatasetDict` เดียว 🤗 Dataset มีฟังก์ชัน `concatenate_datasets()` ที่มีประโยชน์ ซึ่ง (ตามชื่อที่แนะนำ) จะซ้อนวัตถุ `Dataset` สองชิ้นไว้ซ้อนกัน ดังนั้น ในการสร้างชุดข้อมูลสองภาษา เราจะวนซ้ำแต่ละการแยก เชื่อมต่อชุดข้อมูลสำหรับการแยกนั้น และสับเปลี่ยนผลลัพธ์เพื่อให้แน่ใจว่าแบบจำลองของเราจะไม่พอดีกับภาษาเดียว:
+
+```python
+from datasets import concatenate_datasets, DatasetDict
+
+books_dataset = DatasetDict()
+
+for split in english_books.keys():
+ books_dataset[split] = concatenate_datasets(
+ [english_books[split], spanish_books[split]]
+ )
+ books_dataset[split] = books_dataset[split].shuffle(seed=42)
+
+# Peek at a few examples
+show_samples(books_dataset)
+```
+
+```python out
+'>> Title: Easy to follow!!!!'
+'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
+
+'>> Title: PARCIALMENTE DAÑADO'
+'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
+
+'>> Title: no lo he podido descargar'
+'>> Review: igual que el anterior'
+```
+
+ดูเหมือนว่ารีวิวนี้เป็นการผสมผสานระหว่างรีวิวภาษาอังกฤษและสเปนอย่างแน่นอน! ตอนนี้เรามีคลังข้อมูลการฝึกอบรมแล้ว สิ่งสุดท้ายที่ต้องตรวจสอบคือการแจกแจงคำในบทวิจารณ์และชื่อเรื่อง นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับงานการสรุป โดยที่การสรุปอ้างอิงสั้นๆ ในข้อมูลสามารถโน้มน้าวโมเดลให้ส่งออกเพียงหนึ่งหรือสองคำในสรุปที่สร้างขึ้นได้ โครงเรื่องด้านล่างแสดงการแจกแจงคำ และเราจะเห็นว่าชื่อเรื่องมีการบิดเบือนอย่างมากไปเพียง 1-2 คำ:
+
+
+
+มาดูชุดข้อมูลกันดีกว่า:
+
+```py
+raw_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 210173
+ })
+})
+```
+
+เรามีประโยค 210,173 คู่ แต่ในการแยกประโยคเดียว ดังนั้น เราจะต้องสร้างชุดการตรวจสอบของเราเอง ดังที่เราเห็นใน [บทที่ 5](/course/th/chapter5) `Dataset` มีเมธอด `train_test_split()` ที่สามารถช่วยเราได้ เราจะจัดเตรียมเมล็ดพันธุ์สำหรับการทำซ้ำ:
+
+```py
+split_datasets = raw_datasets["train"].train_test_split(train_size=0.9, seed=20)
+split_datasets
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 189155
+ })
+ test: Dataset({
+ features: ['id', 'translation'],
+ num_rows: 21018
+ })
+})
+```
+
+เราสามารถเปลี่ยนชื่อคีย์ `"test"` เป็น `"validation"` ได้ดังนี้:
+
+```py
+split_datasets["validation"] = split_datasets.pop("test")
+```
+
+ตอนนี้เรามาดูองค์ประกอบหนึ่งของชุดข้อมูลกัน:
+
+```py
+split_datasets["train"][1]["translation"]
+```
+
+```python out
+{'en': 'Default to expanded threads',
+ 'fr': 'Par défaut, développer les fils de discussion'}
+```
+
+เราได้รับพจนานุกรมที่มีสองประโยคในคู่ภาษาที่เราขอ ความพิเศษประการหนึ่งของชุดข้อมูลนี้ซึ่งเต็มไปด้วยคำศัพท์ทางเทคนิคด้านวิทยาการคอมพิวเตอร์ก็คือคำศัพท์ทั้งหมดได้รับการแปลเป็นภาษาฝรั่งเศสทั้งหมด อย่างไรก็ตาม วิศวกรชาวฝรั่งเศสจะทิ้งคำเฉพาะด้านวิทยาการคอมพิวเตอร์ส่วนใหญ่เป็นภาษาอังกฤษเมื่อพวกเขาพูด ตัวอย่างเช่น คำว่า "threads" อาจปรากฏในประโยคภาษาฝรั่งเศส โดยเฉพาะอย่างยิ่งในการสนทนาทางเทคนิค แต่ในชุดข้อมูลนี้ มันถูกแปลเป็น "fils de discussion" ที่ถูกต้องมากขึ้น โมเดลที่ฝึกไว้ล่วงหน้าที่เราใช้ ซึ่งได้รับการฝึกฝนกับคลังประโยคภาษาฝรั่งเศสและอังกฤษที่มีขนาดใหญ่กว่า เลือกใช้ตัวเลือกที่ง่ายกว่าในการคงคำไว้ดังนี้:
+
+```py
+from transformers import pipeline
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut pour les threads élargis'}]
+```
+
+อีกตัวอย่างหนึ่งของพฤติกรรมนี้สามารถเห็นได้จากคำว่า "plugin" ซึ่งไม่ใช่คำภาษาฝรั่งเศสอย่างเป็นทางการ แต่เจ้าของภาษาส่วนใหญ่จะเข้าใจและไม่สนใจที่จะแปล
+ในชุดข้อมูล KDE4 คำนี้ได้รับการแปลเป็นภาษาฝรั่งเศสเป็นภาษา "module d'extension" ที่เป็นทางการมากขึ้น:
+
+```py
+split_datasets["train"][172]["translation"]
+```
+
+```python out
+{'en': 'Unable to import %1 using the OFX importer plugin. This file is not the correct format.',
+ 'fr': "Impossible d'importer %1 en utilisant le module d'extension d'importation OFX. Ce fichier n'a pas un format correct."}
+```
+
+อย่างไรก็ตาม โมเดลที่ได้รับการฝึกล่วงหน้าของเรายังคงยึดตามคำภาษาอังกฤษที่กระชับและคุ้นเคย:
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le plugin d'importateur OFX. Ce fichier n'est pas le bon format."}]
+```
+
+น่าสนใจที่จะดูว่าโมเดลที่ได้รับการปรับแต่งของเรานั้นคำนึงถึงความเฉพาะเจาะจงของชุดข้อมูลหรือไม่ (เตือนไว้ก่อน: มันจะเป็นเช่นนั้น)
+
+
+
+
+
+✏️ **ตาคุณ!** อีกคำภาษาอังกฤษที่มักใช้ในภาษาฝรั่งเศสคือ "email" ค้นหาตัวอย่างแรกในชุดข้อมูลการฝึกอบรมที่ใช้คำนี้ มันแปลยังไงบ้าง? โมเดลที่ผ่านการฝึกอบรมจะแปลประโยคภาษาอังกฤษเดียวกันได้อย่างไร
+
+
+
+### การประมวลผลข้อมูล[[การประมวลผลข้อมูล]]
+
+
+
+ตอนนี้คุณควรรู้การเจาะลึกแล้ว: ข้อความทั้งหมดจำเป็นต้องแปลงเป็นชุดรหัสโทเค็นเพื่อให้แบบจำลองเข้าใจได้ สำหรับงานนี้ เราจะต้องสร้างโทเค็นทั้งอินพุตและเป้าหมาย ภารกิจแรกของเราคือสร้างวัตถุ `tokenizer` ของเรา ตามที่ระบุไว้ก่อนหน้านี้ เราจะใช้โมเดลฝึกภาษาอังกฤษแบบ Marian เป็นภาษาฝรั่งเศส หากคุณกำลังลองใช้โค้ดนี้กับคู่ภาษาอื่น ตรวจสอบให้แน่ใจว่าได้ปรับจุดตรวจสอบโมเดลแล้ว องค์กร [Helsinki-NLP](https://huggingface.co/Helsinki-NLP) มีโมเดลมากกว่าพันรายการในหลายภาษา
+
+```python
+from transformers import AutoTokenizer
+
+model_checkpoint = "Helsinki-NLP/opus-mt-en-fr"
+tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, return_tensors="pt")
+```
+
+คุณยังสามารถแทนที่ `model_checkpoint` ด้วยโมเดลอื่นๆ ที่คุณต้องการจาก [Hub](https://huggingface.co/models) หรือโฟลเดอร์ในเครื่องที่คุณได้บันทึกโมเดลที่ฝึกไว้ล่วงหน้าและ tokenizer
+
+
+
+💡 หากคุณใช้โทเค็นไนเซอร์หลายภาษา เช่น mBART, mBART-50 หรือ M2M100 คุณจะต้องตั้งค่ารหัสภาษาของอินพุตและเป้าหมายของคุณในโทเค็นโดยการตั้งค่า `tokenizer.src_lang` และ `tokenizer.tgt_lang` ทางด้านขวา ค่านิยม
+
+
+
+การจัดเตรียมข้อมูลของเราค่อนข้างตรงไปตรงมา มีเพียงสิ่งเดียวที่ต้องจำ คุณต้องแน่ใจว่า tokenizer ประมวลผลเป้าหมายในภาษาเอาต์พุต (ในที่นี้คือภาษาฝรั่งเศส) คุณสามารถทำได้โดยส่งเป้าหมายไปยังอาร์กิวเมนต์ `text_targets` ของเมธอด `__call__` ของ tokenizer
+
+หากต้องการดูวิธีการทำงาน เราจะประมวลผลตัวอย่างของแต่ละภาษาในชุดการฝึกอบรมหนึ่งตัวอย่าง:
+
+```python
+en_sentence = split_datasets["train"][1]["translation"]["en"]
+fr_sentence = split_datasets["train"][1]["translation"]["fr"]
+
+inputs = tokenizer(en_sentence, text_target=fr_sentence)
+inputs
+```
+
+```python out
+{'input_ids': [47591, 12, 9842, 19634, 9, 0], 'attention_mask': [1, 1, 1, 1, 1, 1], 'labels': [577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]}
+```
+
+ดังที่เราเห็น ผลลัพธ์มี ID อินพุตที่เกี่ยวข้องกับประโยคภาษาอังกฤษ ในขณะที่ ID ที่เกี่ยวข้องกับภาษาฝรั่งเศสจะถูกเก็บไว้ในฟิลด์ `labels` หากคุณลืมระบุว่าคุณกำลังโทเค็นป้ายกำกับ ป้ายเหล่านั้นจะถูกโทเค็นโดยอินพุตโทเค็นไนเซอร์ ซึ่งในกรณีของโมเดล Marian จะทำงานได้ไม่ดีเลย:
+
+```python
+wrong_targets = tokenizer(fr_sentence)
+print(tokenizer.convert_ids_to_tokens(wrong_targets["input_ids"]))
+print(tokenizer.convert_ids_to_tokens(inputs["labels"]))
+```
+
+```python out
+['▁Par', '▁dé', 'f', 'aut', ',', '▁dé', 've', 'lop', 'per', '▁les', '▁fil', 's', '▁de', '▁discussion', '']
+['▁Par', '▁défaut', ',', '▁développer', '▁les', '▁fils', '▁de', '▁discussion', '']
+```
+
+ดังที่เราเห็น การใช้ tokenizer ภาษาอังกฤษเพื่อประมวลผลประโยคภาษาฝรั่งเศสล่วงหน้าส่งผลให้มี token มากขึ้น เนื่องจาก tokenizer ไม่รู้จักคำภาษาฝรั่งเศสใดๆ (ยกเว้นคำที่ปรากฏในภาษาอังกฤษ เช่น "discussion")
+
+เนื่องจาก `inputs` เป็นพจนานุกรมที่มีคีย์ปกติของเรา (ID อินพุต มาสก์ความสนใจ ฯลฯ) ขั้นตอนสุดท้ายคือการกำหนดฟังก์ชันการประมวลผลล่วงหน้าที่เราจะนำไปใช้กับชุดข้อมูล:
+
+```python
+max_length = 128
+
+
+def preprocess_function(examples):
+ inputs = [ex["en"] for ex in examples["translation"]]
+ targets = [ex["fr"] for ex in examples["translation"]]
+ model_inputs = tokenizer(
+ inputs, text_target=targets, max_length=max_length, truncation=True
+ )
+ return model_inputs
+```
+
+โปรดทราบว่าเราตั้งค่าความยาวสูงสุดเท่ากันสำหรับอินพุตและเอาต์พุตของเรา เนื่องจากข้อความที่เรากำลังพูดถึงดูค่อนข้างสั้น เราจึงใช้ 128
+
+
+
+💡 หากคุณกำลังใช้โมเดล T5 (โดยเฉพาะอย่างยิ่ง หนึ่งในจุดตรวจสอบ `t5-xxx`) โมเดลจะคาดหวังว่าอินพุตข้อความจะมีคำนำหน้าระบุงานที่ทำอยู่ เช่น `translate: English to French:`
+
+
+
+
+
+⚠️ เราไม่ใส่ใจกับหน้ากากความสนใจของเป้าหมาย เนื่องจากโมเดลไม่ได้คาดหวังไว้ แต่ควรตั้งค่าป้ายกำกับที่สอดคล้องกับโทเค็นการเติมเป็น `-100` แทน เพื่อที่ป้ายเหล่านั้นจะถูกละเว้นในการคำนวณการสูญเสีย ผู้รวบรวมข้อมูลของเราจะดำเนินการนี้ในภายหลัง เนื่องจากเราใช้การเติมแบบไดนามิก แต่หากคุณใช้การเติมภายในที่นี่ คุณควรปรับฟังก์ชันการประมวลผลล่วงหน้าเพื่อตั้งค่าป้ายกำกับทั้งหมดที่สอดคล้องกับโทเค็นการเติมเป็น `-100`
+
+
+
+ตอนนี้เราสามารถใช้การประมวลผลล่วงหน้านั้นกับการแยกชุดข้อมูลทั้งหมดของเราได้ในคราวเดียว:
+
+```py
+tokenized_datasets = split_datasets.map(
+ preprocess_function,
+ batched=True,
+ remove_columns=split_datasets["train"].column_names,
+)
+```
+
+เมื่อข้อมูลได้รับการประมวลผลล่วงหน้าแล้ว เราก็พร้อมที่จะปรับแต่งโมเดลที่ฝึกไว้ล่วงหน้าของเราแล้ว!
+
+{#if fw === 'pt'}
+
+## การปรับแต่งโมเดลอย่างละเอียดด้วย `Trainer` API[[การปรับแต่งโมเดลอย่างละเอียดด้วย-trainer-api]]
+
+โค้ดจริงที่ใช้ `Trainer` จะเหมือนเดิม โดยมีการเปลี่ยนแปลงเพียงเล็กน้อย: เราใช้ [`Seq2SeqTrainer`](https://huggingface.co/transformers/main_classes/trainer.html#seq2seqtrainer) ที่นี่ ซึ่งเป็นคลาสย่อยของ `Trainer` ที่จะช่วยให้เราจัดการกับการประเมินได้อย่างเหมาะสม โดยใช้เมธอด `generate()` เพื่อทำนายเอาต์พุตจากอินพุต เราจะเจาะลึกรายละเอียดมากขึ้นเมื่อเราพูดถึงการคำนวณหน่วยเมตริก
+
+ก่อนอื่น เราต้องการโมเดลจริงเพื่อปรับแต่งอย่างละเอียด เราจะใช้ `AutoModel` API ตามปกติ:
+
+```py
+from transformers import AutoModelForSeq2SeqLM
+
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+{:else}
+
+## การปรับแต่งโมเดลอย่างละเอียดด้วย Keras[[การปรับแต่งโมเดลอย่างละเอียดด้วย-keras]]
+
+ก่อนอื่น เราต้องการโมเดลจริงเพื่อปรับแต่งอย่างละเอียด เราจะใช้ `AutoModel` API ตามปกติ:
+
+```py
+from transformers import TFAutoModelForSeq2SeqLM
+
+model = TFAutoModelForSeq2SeqLM.from_pretrained(model_checkpoint, from_pt=True)
+```
+
+
+
+💡 จุด checkpoint `Helsinki-NLP/opus-mt-en-fr` มีเพียงน้ำหนักของ PyTorch ดังนั้น
+คุณจะได้รับข้อผิดพลาดหากคุณพยายามโหลดโมเดลโดยไม่ใช้
+อาร์กิวเมนต์ `from_pt=True` ในเมธอด `from_pretrained()` เมื่อคุณระบุ
+`from_pt=True` ไลบรารีจะดาวน์โหลดและแปลงน้ำหนัก PyTorch สำหรับคุณโดยอัตโนมัติ อย่างที่คุณเห็น มันง่ายมากที่จะสลับไปมาระหว่าง
+เฟรมเวิร์กใน 🤗 Transformers!
+
+
+
+{/if}
+
+ปรดทราบว่าครั้งนี้ เรากำลังใช้แบบจำลองที่ได้รับการฝึกในงานแปลและสามารถใช้งานได้จริงแล้ว ดังนั้นจึงไม่มีคำเตือนเกี่ยวกับน้ำหนักที่หายไปหรือน้ำหนักที่เริ่มต้นใหม่
+
+### การรวบรวมข้อมูล[[การรวบรวมข้อมูล]]
+
+เราจะต้องมีตัวเปรียบเทียบข้อมูลเพื่อจัดการกับช่องว่างภายในสำหรับการจัดชุดแบบไดนามิก เราไม่สามารถใช้ `DataCollatorWithPadding` เหมือนใน [บทที่ 3](/course/th/chapter3) ในกรณีนี้ไม่ได้ เนื่องจากนั่นเป็นเพียงการเสริมอินพุตเท่านั้น (ID อินพุต, มาสก์ความสนใจ และ ID ประเภทโทเค็น) ฉลากของเราควรได้รับการบุให้มีความยาวสูงสุดที่พบในฉลาก และตามที่กล่าวไว้ก่อนหน้านี้ ค่าการเสริมที่ใช้ในการเสริมป้ายกำกับควรเป็น `-100` และไม่ใช่โทเค็นการเสริมของโทเค็น เพื่อให้แน่ใจว่าค่าที่เสริมไว้เหล่านั้นจะถูกละเว้นในการคำนวณการสูญเสีย
+
+ทั้งหมดนี้ทำโดย [`DataCollatorForSeq2Seq`](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorforseq2seq) เช่นเดียวกับ `DataCollatorWithPadding` มันต้องใช้ `tokenizer` ที่ใช้ในการประมวลผลอินพุตล่วงหน้า แต่ก็ใช้ `model` ด้วย เนื่องจากตัวรวบรวมข้อมูลนี้ยังต้องรับผิดชอบในการเตรียม ID อินพุตตัวถอดรหัส ซึ่งเป็นเวอร์ชันที่ถูกเลื่อนของป้ายกำกับด้วยโทเค็นพิเศษที่จุดเริ่มต้น เนื่องจากการเปลี่ยนแปลงนี้ทำแตกต่างกันเล็กน้อยสำหรับสถาปัตยกรรมที่แตกต่างกัน `DataCollatorForSeq2Seq` จำเป็นต้องทราบอ็อบเจ็กต์ `model`:
+
+{#if fw === 'pt'}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
+```
+
+{:else}
+
+```py
+from transformers import DataCollatorForSeq2Seq
+
+data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
+```
+
+{/if}
+
+เพื่อทดสอบสิ่งนี้กับตัวอย่างบางส่วน เราเพียงเรียกมันในรายการตัวอย่างจากชุดการฝึกโทเค็นของเรา:
+
+```py
+batch = data_collator([tokenized_datasets["train"][i] for i in range(1, 3)])
+batch.keys()
+```
+
+```python out
+dict_keys(['attention_mask', 'input_ids', 'labels', 'decoder_input_ids'])
+```
+
+เราสามารถตรวจสอบได้ว่าฉลากของเราได้รับการเสริมความยาวสูงสุดของชุดโดยใช้ `-100`:
+
+```py
+batch["labels"]
+```
+
+```python out
+tensor([[ 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0, -100,
+ -100, -100, -100, -100, -100, -100],
+ [ 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817,
+ 550, 7032, 5821, 7907, 12649, 0]])
+```
+
+และเรายังสามารถดู ID อินพุตของตัวถอดรหัสเพื่อดูว่าเป็นเวอร์ชันที่เลื่อนของป้ายกำกับ:
+
+```py
+batch["decoder_input_ids"]
+```
+
+```python out
+tensor([[59513, 577, 5891, 2, 3184, 16, 2542, 5, 1710, 0,
+ 59513, 59513, 59513, 59513, 59513, 59513],
+ [59513, 1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124,
+ 817, 550, 7032, 5821, 7907, 12649]])
+```
+
+ต่อไปนี้เป็นป้ายกำกับสำหรับองค์ประกอบที่หนึ่งและที่สองในชุดข้อมูลของเรา:
+
+```py
+for i in range(1, 3):
+ print(tokenized_datasets["train"][i]["labels"])
+```
+
+```python out
+[577, 5891, 2, 3184, 16, 2542, 5, 1710, 0]
+[1211, 3, 49, 9409, 1211, 3, 29140, 817, 3124, 817, 550, 7032, 5821, 7907, 12649, 0]
+```
+
+{#if fw === 'pt'}
+
+เราจะส่ง `data_collator` นี้ไปยัง `Seq2SeqTrainer` ต่อไปเรามาดูตัวชี้วัดกัน
+
+{:else}
+
+ตอนนี้เราสามารถใช้ `data_collator` นี้เพื่อแปลงชุดข้อมูลแต่ละชุดของเราเป็น `tf.data.Dataset` พร้อมสำหรับการฝึกอบรม:
+
+```python
+tf_train_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["train"],
+ collate_fn=data_collator,
+ shuffle=True,
+ batch_size=32,
+)
+tf_eval_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=data_collator,
+ shuffle=False,
+ batch_size=16,
+)
+```
+
+{/if}
+
+
+### เมตริก[[เมตริก]]
+
+
+
+{#if fw === 'pt'}
+
+คุณลักษณะที่ `Seq2SeqTrainer` เพิ่มให้กับ `Trainer` ระดับซูเปอร์คลาสคือความสามารถในการใช้เมธอด `generate()` ในระหว่างการประเมินหรือการทำนาย ในระหว่างการฝึก โมเดลจะใช้ `decoder_input_ids` พร้อมกับมาส์กความสนใจเพื่อให้แน่ใจว่าจะไม่ใช้โทเค็นหลังจากโทเค็นที่พยายามคาดการณ์ เพื่อเร่งความเร็วในการฝึก ในระหว่างการอนุมาน เราจะไม่สามารถใช้สิ่งเหล่านั้นได้เนื่องจากเราไม่มีป้ายกำกับ ดังนั้นจึงเป็นความคิดที่ดีที่จะประเมินแบบจำลองของเราด้วยการตั้งค่าเดียวกัน
+
+ดังที่เราเห็นใน [บทที่ 1](/course/th/chapter1/6) ตัวถอดรหัสทำการอนุมานโดยการทำนายโทเค็นทีละรายการ ซึ่งเป็นสิ่งที่นำไปใช้เบื้องหลังใน 🤗 Transformers ด้วยเมธอด `generate()` `Seq2SeqTrainer` จะให้เราใช้วิธีการนั้นในการประเมินหากเราตั้งค่า `predict_with_generate=True`
+
+{/if}
+
+ตัวชี้วัดแบบดั้งเดิมที่ใช้สำหรับการแปลคือ [คะแนน BLEU](https://en.wikipedia.org/wiki/BLEU) ซึ่งนำมาใช้ใน [บทความปี 2002](https://aclanthology.org/P02-1040.pdf) โดย Kishore Papineni และคณะ คะแนน BLEU จะประเมินว่าคำแปลใกล้เคียงกับป้ายกำกับเพียงใด ไม่ได้วัดความชัดเจนหรือความถูกต้องทางไวยากรณ์ของผลลัพธ์ที่สร้างของแบบจำลอง แต่ใช้กฎทางสถิติเพื่อให้แน่ใจว่าคำทั้งหมดในผลลัพธ์ที่สร้างขึ้นจะปรากฏในเป้าหมายด้วย นอกจากนี้ ยังมีกฎที่ลงโทษการใช้คำเดียวกันซ้ำๆ หากไม่ซ้ำกันในเป้าหมายด้วย (เพื่อหลีกเลี่ยงรูปแบบที่ส่งออกประโยค เช่น `"the the the the"`) และประโยคเอาต์พุตที่สั้นกว่าที่อยู่ใน เป้าหมาย (เพื่อหลีกเลี่ยงโมเดลที่ส่งออกประโยคเช่น `"the"`)
+
+จุดอ่อนประการหนึ่งของ BLEU คือคาดว่าข้อความจะถูกโทเค็นไนซ์แล้ว ซึ่งทำให้ยากต่อการเปรียบเทียบคะแนนระหว่างโมเดลที่ใช้โทเค็นไนเซอร์ที่แตกต่างกัน ดังนั้น เมตริกที่ใช้บ่อยที่สุดสำหรับการเปรียบเทียบโมเดลการแปลในปัจจุบันคือ [SacreBLEU](https://github.com/mjpost/sacrebleu) ซึ่งจัดการกับจุดอ่อนนี้ (และอื่นๆ) ด้วยการกำหนดขั้นตอนโทเค็นให้เป็นมาตรฐาน หากต้องการใช้ตัวชี้วัดนี้ เราต้องติดตั้งไลบรารี SacreBLEU ก่อน:
+
+```py
+!pip install sacrebleu
+```
+
+จากนั้นเราสามารถโหลดมันผ่าน `evaluate.load()` เหมือนที่เราทำใน [บทที่ 3](/course/th/chapter3):
+
+```py
+import evaluate
+
+metric = evaluate.load("sacrebleu")
+```
+
+เมตริกนี้จะใช้ข้อความเป็นอินพุตและเป้าหมาย ได้รับการออกแบบมาเพื่อยอมรับเป้าหมายที่ยอมรับได้หลายเป้าหมาย เนื่องจากมักจะมีการแปลประโยคเดียวกันที่ยอมรับได้หลายรายการ ชุดข้อมูลที่เราใช้จะมีเพียงเป้าหมายเดียว แต่ไม่ใช่เรื่องแปลกใน NLP ที่จะค้นหาชุดข้อมูลที่มีหลายประโยคเป็นป้ายกำกับ ดังนั้นการคาดคะเนควรเป็นรายการประโยค แต่การอ้างอิงควรเป็นรายการประโยค
+
+มาทดสอบตัวอย่างกัน:
+
+```py
+predictions = [
+ "This plugin lets you translate web pages between several languages automatically."
+]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 46.750469682990165,
+ 'counts': [11, 6, 4, 3],
+ 'totals': [12, 11, 10, 9],
+ 'precisions': [91.67, 54.54, 40.0, 33.33],
+ 'bp': 0.9200444146293233,
+ 'sys_len': 12,
+ 'ref_len': 13}
+```
+
+ซึ่งได้คะแนน BLEU ที่ 46.75 ซึ่งค่อนข้างดี สำหรับการอ้างอิง โมเดล Transformer ดั้งเดิมในเอกสาร ["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf) ได้รับ คะแนน BLEU 41.8 ในงานแปลที่คล้ายกันระหว่างภาษาอังกฤษและภาษาฝรั่งเศส! (สำหรับข้อมูลเพิ่มเติมเกี่ยวกับตัวชี้วัดแต่ละรายการ เช่น `counts` และ `bp` โปรดดูที่ [พื้นที่เก็บข้อมูล SacreBLEU](https://github.com/mjpost/sacrebleu/blob/078c440168c6adc89ba75fe6d63f0d922d42bcfe/sacrebleu/metrics/bleu.py#L74 ).) ในทางกลับกัน ถ้าเราลองใช้การทำนายที่ไม่ดีสองประเภท (การซ้ำหลายครั้งหรือสั้นเกินไป) ซึ่งมักจะมาจากโมเดลการแปล เราจะได้คะแนน BLEU ที่ค่อนข้างแย่:
+
+```py
+predictions = ["This This This This"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 1.683602693167689,
+ 'counts': [1, 0, 0, 0],
+ 'totals': [4, 3, 2, 1],
+ 'precisions': [25.0, 16.67, 12.5, 12.5],
+ 'bp': 0.10539922456186433,
+ 'sys_len': 4,
+ 'ref_len': 13}
+```
+
+```py
+predictions = ["This plugin"]
+references = [
+ [
+ "This plugin allows you to automatically translate web pages between several languages."
+ ]
+]
+metric.compute(predictions=predictions, references=references)
+```
+
+```python out
+{'score': 0.0,
+ 'counts': [2, 1, 0, 0],
+ 'totals': [2, 1, 0, 0],
+ 'precisions': [100.0, 100.0, 0.0, 0.0],
+ 'bp': 0.004086771438464067,
+ 'sys_len': 2,
+ 'ref_len': 13}
+```
+
+คะแนนสามารถอยู่ระหว่าง 0 ถึง 100 และยิ่งสูงก็ยิ่งดี
+
+{#if fw === 'tf'}
+
+หากต้องการรับจากเอาต์พุตของโมเดลเป็นข้อความที่หน่วยวัดสามารถใช้ได้ เราจะใช้เมธอด `tokenizer.batch_decode()` เราแค่ต้องทำความสะอาด `-100` ทั้งหมดในฉลาก โทเค็นไนเซอร์จะทำเช่นเดียวกันกับโทเค็นการเติมโดยอัตโนมัติ เรามากำหนดฟังก์ชันที่ใช้โมเดลและชุดข้อมูลของเราและคำนวณเมตริกจากโมเดลนั้น นอกจากนี้เรายังจะใช้เคล็ดลับที่เพิ่มประสิทธิภาพได้อย่างมาก ด้วยการคอมไพล์โค้ดการสร้างของเราด้วย [XLA](https://www.tensorflow.org/xla) ซึ่งเป็นคอมไพเลอร์พีชคณิตเชิงเส้นแบบเร่งของ TensorFlow XLA ใช้การปรับให้เหมาะสมต่างๆ กับกราฟการคำนวณของโมเดล และส่งผลให้มีการปรับปรุงความเร็วและการใช้หน่วยความจำอย่างมีนัยสำคัญ ตามที่อธิบายไว้ใน Hugging Face [บล็อก](https://huggingface.co/blog/tf-xla-generate) XLA ทำงานได้ดีที่สุดเมื่อรูปร่างอินพุตของเราไม่แตกต่างกันมากเกินไป เพื่อจัดการสิ่งนี้ เราจะแพดอินพุตของเราให้เป็นทวีคูณของ 128 และสร้างชุดข้อมูลใหม่ด้วยตัวเปรียบเทียบการแพด จากนั้นเราจะใช้มัณฑนากร `@tf.function(jit_compile=True)` กับฟังก์ชันการสร้างของเรา ซึ่ง ทำเครื่องหมายฟังก์ชันทั้งหมดสำหรับการคอมไพล์ด้วย XLA
+
+```py
+import numpy as np
+import tensorflow as tf
+from tqdm import tqdm
+
+generation_data_collator = DataCollatorForSeq2Seq(
+ tokenizer, model=model, return_tensors="tf", pad_to_multiple_of=128
+)
+
+tf_generate_dataset = model.prepare_tf_dataset(
+ tokenized_datasets["validation"],
+ collate_fn=generation_data_collator,
+ shuffle=False,
+ batch_size=8,
+)
+
+
+@tf.function(jit_compile=True)
+def generate_with_xla(batch):
+ return model.generate(
+ input_ids=batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_new_tokens=128,
+ )
+
+
+def compute_metrics():
+ all_preds = []
+ all_labels = []
+
+ for batch, labels in tqdm(tf_generate_dataset):
+ predictions = generate_with_xla(batch)
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = labels.numpy()
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ all_preds.extend(decoded_preds)
+ all_labels.extend(decoded_labels)
+
+ result = metric.compute(predictions=all_preds, references=all_labels)
+ return {"bleu": result["score"]}
+```
+
+{:else}
+
+หากต้องการรับจากเอาต์พุตของโมเดลเป็นข้อความที่หน่วยวัดสามารถใช้ได้ เราจะใช้เมธอด `tokenizer.batch_decode()` เราเพียงแค่ต้องล้าง `-100` ทั้งหมดในป้ายกำกับ (โทเค็นจะทำเช่นเดียวกันกับโทเค็นการเติมโดยอัตโนมัติ):
+
+```py
+import numpy as np
+
+
+def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # In case the model returns more than the prediction logits
+ if isinstance(preds, tuple):
+ preds = preds[0]
+
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+ # Replace -100s in the labels as we can't decode them
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ return {"bleu": result["score"]}
+```
+
+{/if}
+
+เมื่อเสร็จแล้ว เราก็พร้อมที่จะปรับแต่งโมเดลของเรา!
+
+
+### การปรับแต่งโมเดลอย่างละเอียด[[การปรับแต่งโมเดลอย่างละเอียด]]
+
+ขั้นตอนแรกคือการเข้าสู่ระบบ Hugging Face เพื่อให้คุณสามารถอัปโหลดผลลัพธ์ของคุณไปยัง Model Hub มีฟังก์ชันอำนวยความสะดวกที่จะช่วยคุณในเรื่องนี้ในโน้ตบุ๊ก:
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+นี่จะแสดงวิดเจ็ตที่คุณสามารถป้อนข้อมูลรับรองการเข้าสู่ระบบ Hugging Face ของคุณได้
+
+หากคุณไม่ได้ทำงานในโน้ตบุ๊ก เพียงพิมพ์บรรทัดต่อไปนี้ในเทอร์มินัลของคุณ:
+
+```bash
+huggingface-cli login
+```
+
+{#if fw === 'tf'}
+
+ก่อนที่เราจะเริ่มต้น มาดูกันว่าเราได้รับผลลัพธ์ประเภทใดจากโมเดลของเราโดยไม่มีการฝึกอบรมใดๆ:
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 33.26983701454733}
+```
+
+เมื่อเสร็จแล้ว เราก็เตรียมทุกอย่างที่จำเป็นเพื่อคอมไพล์และฝึกโมเดลของเราได้ โปรดสังเกตการใช้ `tf.keras.mixed_precision.set_global_policy("mixed_float16")` -- ซึ่งจะเป็นการบอกให้ Keras ฝึกฝนการใช้ float16 ซึ่งสามารถเร่งความเร็วได้อย่างมากบน GPU ที่รองรับ (Nvidia 20xx/V100 หรือใหม่กว่า)
+
+```python
+from transformers import create_optimizer
+from transformers.keras_callbacks import PushToHubCallback
+import tensorflow as tf
+
+# The number of training steps is the number of samples in the dataset, divided by the batch size then multiplied
+# by the total number of epochs. Note that the tf_train_dataset here is a batched tf.data.Dataset,
+# not the original Hugging Face Dataset, so its len() is already num_samples // batch_size.
+num_epochs = 3
+num_train_steps = len(tf_train_dataset) * num_epochs
+
+optimizer, schedule = create_optimizer(
+ init_lr=5e-5,
+ num_warmup_steps=0,
+ num_train_steps=num_train_steps,
+ weight_decay_rate=0.01,
+)
+model.compile(optimizer=optimizer)
+
+# Train in mixed-precision float16
+tf.keras.mixed_precision.set_global_policy("mixed_float16")
+```
+
+ต่อไป เราจะกำหนด `PushToHubCallback` เพื่ออัปโหลดโมเดลของเราไปยัง Hub ในระหว่างการฝึก ดังที่เราเห็นใน [ส่วนที่ 2]((/course/th/chapter7/2)) จากนั้นเราก็ปรับโมเดลให้เข้ากับ callback นั้น:
+
+```python
+from transformers.keras_callbacks import PushToHubCallback
+
+callback = PushToHubCallback(
+ output_dir="marian-finetuned-kde4-en-to-fr", tokenizer=tokenizer
+)
+
+model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ callbacks=[callback],
+ epochs=num_epochs,
+)
+```
+
+โปรดทราบว่าคุณสามารถระบุชื่อของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` ถึง `Seq2SeqTrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นที่นี่จะเป็น `"sgugger/marian-finetuned-kde4-en-to-fr"` (ซึ่งเป็นโมเดลที่เราเชื่อมโยงด้วย ในตอนต้นของส่วนนี้)
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อเรียก `model.fit()` และจะต้องตั้งชื่อใหม่
+
+
+
+สุดท้ายนี้ เรามาดูกันว่าเมตริกของเราจะเป็นอย่างไรเมื่อการฝึกอบรมเสร็จสิ้นแล้ว:
+
+```py
+print(compute_metrics())
+```
+
+```
+{'bleu': 57.334066271545865}
+```
+
+ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณปรับแต่งโมเดลในงานแปลได้สำเร็จ ขอแสดงความยินดีด้วย!
+
+{:else}
+
+เมื่อเสร็จแล้ว เราก็สามารถกำหนด `Seq2SeqTrainingArguments` ของเราได้ เช่นเดียวกับ `Trainer` เราใช้คลาสย่อยของ `TrainingArguments` ที่มีตัวแปลเพิ่มเติมสองสามตัว:
+
+```python
+from transformers import Seq2SeqTrainingArguments
+
+args = Seq2SeqTrainingArguments(
+ f"marian-finetuned-kde4-en-to-fr",
+ evaluation_strategy="no",
+ save_strategy="epoch",
+ learning_rate=2e-5,
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=64,
+ weight_decay=0.01,
+ save_total_limit=3,
+ num_train_epochs=3,
+ predict_with_generate=True,
+ fp16=True,
+ push_to_hub=True,
+)
+```
+
+นอกเหนือจากไฮเปอร์พารามิเตอร์ตามปกติ (เช่น learning rate, number of epochs, batch size, and some weight decay), ต่อไปนี้คือการเปลี่ยนแปลงเล็กๆ น้อยๆ เมื่อเทียบกับสิ่งที่เราเห็นในส่วนที่แล้ว:
+
+- เราไม่ได้กำหนดการประเมินเป็นประจำ เนื่องจากการประเมินจะใช้เวลาระยะหนึ่ง เราจะประเมินแบบจำลองของเราหนึ่งครั้งก่อนการฝึกและหลังการฝึก
+- เราตั้งค่า `fp16=True` ซึ่งจะช่วยเร่งความเร็วการฝึกอบรมบน GPU สมัยใหม่
+- เราตั้งค่า `predict_with_generate=True` ตามที่กล่าวไว้ข้างต้น
+- เราใช้ `push_to_hub=True` เพื่ออัปโหลดโมเดลไปยัง Hub เมื่อสิ้นสุดแต่ละ epoch
+
+โปรดทราบว่าคุณสามารถระบุชื่อเต็มของพื้นที่เก็บข้อมูลที่คุณต้องการพุชไปได้ด้วยอาร์กิวเมนต์ `hub_model_id` (โดยเฉพาะ คุณจะต้องใช้อาร์กิวเมนต์นี้เพื่อพุชไปยังองค์กร) ตัวอย่างเช่น เมื่อเราผลักโมเดลไปที่ [`huggingface-course` Organization](https://huggingface.co/huggingface-course) เราได้เพิ่ม `hub_model_id="huggingface-course/marian-finetuned-kde4-en- to-fr"` ถึง `Seq2SeqTrainingArguments` ตามค่าเริ่มต้น พื้นที่เก็บข้อมูลที่ใช้จะอยู่ในเนมสเปซของคุณและตั้งชื่อตามไดเร็กทอรีเอาต์พุตที่คุณตั้งค่า ดังนั้นในกรณีของเราจะเป็น `"sgugger/marian-finetuned-kde4-en-to-fr"` (ซึ่งเป็นโมเดลที่เรา เชื่อมโยงกับตอนต้นของส่วนนี้)
+
+
+
+💡 หากไดเร็กทอรีเอาต์พุตที่คุณใช้มีอยู่แล้ว จะต้องเป็นโคลนในเครื่องของที่เก็บที่คุณต้องการพุชไป หากไม่เป็นเช่นนั้น คุณจะได้รับข้อผิดพลาดเมื่อกำหนด `Seq2SeqTrainer` ของคุณและจะต้องตั้งชื่อใหม่
+
+
+
+
+ในที่สุด เราก็ส่งทุกอย่างไปที่ `Seq2SeqTrainer`:
+
+```python
+from transformers import Seq2SeqTrainer
+
+trainer = Seq2SeqTrainer(
+ model,
+ args,
+ train_dataset=tokenized_datasets["train"],
+ eval_dataset=tokenized_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=tokenizer,
+ compute_metrics=compute_metrics,
+)
+```
+
+ก่อนการฝึก เราจะดูคะแนนที่โมเดลของเราได้รับก่อน เพื่อตรวจสอบอีกครั้งว่าเราไม่ได้ทำให้สิ่งต่าง ๆ แย่ลงด้วยการปรับแต่งของเรา คำสั่งนี้จะใช้เวลาสักครู่ ดังนั้นคุณจึงสามารถดื่มกาแฟในขณะที่ดำเนินการได้:
+
+```python
+trainer.evaluate(max_length=max_length)
+```
+
+```python out
+{'eval_loss': 1.6964408159255981,
+ 'eval_bleu': 39.26865061007616,
+ 'eval_runtime': 965.8884,
+ 'eval_samples_per_second': 21.76,
+ 'eval_steps_per_second': 0.341}
+```
+
+คะแนน BLEU ที่ 39 ก็ไม่ได้แย่นัก ซึ่งสะท้อนให้เห็นว่าแบบจำลองของเราแปลประโยคภาษาอังกฤษเป็นภาษาฝรั่งเศสได้ดีอยู่แล้ว
+
+ต่อไปคือการฝึกอบรมซึ่งจะใช้เวลาสักหน่อย:
+
+```python
+trainer.train()
+```
+
+โปรดทราบว่าในขณะที่การฝึกเกิดขึ้น แต่ละครั้งที่มีการบันทึกโมเดล (ที่นี่ ทุก epoch) โมเดลจะถูกอัปโหลดไปยัง Hub ในเบื้องหลัง ด้วยวิธีนี้ คุณจะสามารถกลับมาฝึกต่อในเครื่องอื่นได้หากจำเป็น
+
+เมื่อการฝึกอบรมเสร็จสิ้น เราจะประเมินแบบจำลองของเราอีกครั้ง หวังว่าเราจะได้เห็นการปรับปรุงในคะแนน BLEU
+
+```py
+trainer.evaluate(max_length=max_length)
+```
+
+```python out
+{'eval_loss': 0.8558505773544312,
+ 'eval_bleu': 52.94161337775576,
+ 'eval_runtime': 714.2576,
+ 'eval_samples_per_second': 29.426,
+ 'eval_steps_per_second': 0.461,
+ 'epoch': 3.0}
+```
+
+นั่นเป็นการปรับปรุงเกือบ 14 แต้มซึ่งดีมาก
+
+สุดท้ายนี้ เราใช้เมธอด `push_to_hub()` เพื่อให้แน่ใจว่าเราจะอัปโหลดโมเดลเวอร์ชันล่าสุด `Trainer` ยังร่างการ์ดโมเดลพร้อมผลการประเมินทั้งหมดแล้วอัปโหลด การ์ดโมเดลนี้มีข้อมูลเมตาที่ช่วยให้ Model Hub เลือกวิดเจ็ตสำหรับการสาธิตการอนุมาน โดยปกติแล้ว ไม่จำเป็นต้องพูดอะไร เนื่องจากสามารถอนุมานวิดเจ็ตที่ถูกต้องจากคลาสโมเดลได้ แต่ในกรณีนี้ สามารถใช้คลาสโมเดลเดียวกันสำหรับปัญหาลำดับต่อลำดับทุกประเภท ดังนั้นเราจึงระบุว่าเป็นการแปล แบบอย่าง:
+
+```py
+trainer.push_to_hub(tags="translation", commit_message="Training complete")
+```
+
+คำสั่งนี้จะส่งคืน URL ของการคอมมิตที่เพิ่งทำไป หากคุณต้องการตรวจสอบ:
+
+```python out
+'https://huggingface.co/sgugger/marian-finetuned-kde4-en-to-fr/commit/3601d621e3baae2bc63d3311452535f8f58f6ef3'
+```
+
+ในขั้นตอนนี้ คุณสามารถใช้วิดเจ็ตการอนุมานบน Model Hub เพื่อทดสอบโมเดลของคุณและแบ่งปันกับเพื่อนๆ ของคุณได้ คุณปรับแต่งโมเดลในงานแปลได้สำเร็จ ขอแสดงความยินดีด้วย!
+
+หากคุณต้องการเจาะลึกลงไปในลูปการฝึกซ้อมมากขึ้น ตอนนี้เราจะแสดงวิธีทำสิ่งเดียวกันโดยใช้ 🤗 Accelerate
+
+{/if}
+
+{#if fw === 'pt'}
+
+## การวนลูปฝึกอบรมแบบกำหนดเอง[[การวนลูปฝึกอบรมแบบกำหนดเอง]]
+
+ตอนนี้เรามาดูวงจรการฝึกซ้อมทั้งหมดกัน เพื่อให้คุณปรับแต่งส่วนต่างๆ ที่ต้องการได้อย่างง่ายดาย มันจะดูเหมือนกับสิ่งที่เราทำใน [ส่วนที 2](/course/th/chapter7/2) และ [บทที่ 3](/course/th/chapter3/4) มาก
+
+### เตรียมทุกอย่างเพื่อการฝึก[[เตรียมทุกอย่างเพื่อการฝึก]]
+
+คุณเคยเห็นทั้งหมดนี้มาสองสามครั้งแล้ว ดังนั้นเราจะอธิบายโค้ดอย่างรวดเร็ว ก่อนอื่น เราจะสร้าง `DataLoader`s จากชุดข้อมูลของเรา หลังจากตั้งค่าชุดข้อมูลเป็นรูปแบบ `"torch"` แล้ว เราก็จะได้ PyTorch tensors:
+
+```py
+from torch.utils.data import DataLoader
+
+tokenized_datasets.set_format("torch")
+train_dataloader = DataLoader(
+ tokenized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=8,
+)
+eval_dataloader = DataLoader(
+ tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
+)
+```
+
+ต่อไป เราจะสร้างโมเดลของเราขึ้นมาใหม่ เพื่อให้แน่ใจว่าเราจะไม่ทำการปรับแต่งแบบละเอียดจากเมื่อก่อนอีกต่อไป แต่เริ่มต้นจากโมเดลที่ได้รับการฝึกไว้ล่วงหน้าอีกครั้ง:
+
+```py
+model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
+```
+
+จากนั้นเราจะต้องมีเครื่องมือเพิ่มประสิทธิภาพ:
+
+```py
+from transformers import AdamW
+
+optimizer = AdamW(model.parameters(), lr=2e-5)
+```
+
+เมื่อเรามีอ็อบเจ็กต์ทั้งหมดแล้ว เราก็สามารถส่งมันไปที่เมธอด `accelerator.prepare()` ได้ โปรดทราบว่าหากคุณต้องการฝึก TPU ในสมุดบันทึก Colab คุณจะต้องย้ายโค้ดทั้งหมดนี้ไปยังฟังก์ชันการฝึก และไม่ควรเรียกใช้เซลล์ใดๆ ที่สร้างอินสแตนซ์ `Accelerator`.
+
+```py
+from accelerate import Accelerator
+
+accelerator = Accelerator()
+model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+)
+```
+
+ตอนนี้เราได้ส่ง `train_dataloader` ไปที่ `accelerator.prepare()` แล้ว เราสามารถใช้ความยาวของมันเพื่อคำนวณจำนวนขั้นตอนการฝึกได้ โปรดจำไว้ว่าเราควรทำเช่นนี้เสมอหลังจากเตรียม dataloader เนื่องจากวิธีการดังกล่าวจะเปลี่ยนความยาวของ `DataLoader` เราใช้กำหนดการเชิงเส้นแบบคลาสสิกจากอัตราการเรียนรู้ถึง 0:
+
+```py
+from transformers import get_scheduler
+
+num_train_epochs = 3
+num_update_steps_per_epoch = len(train_dataloader)
+num_training_steps = num_train_epochs * num_update_steps_per_epoch
+
+lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps,
+)
+```
+
+สุดท้ายนี้ ในการผลักดันโมเดลของเราไปที่ Hub เราจะต้องสร้างออบเจ็กต์ `Repository` ในโฟลเดอร์ที่ใช้งานได้ ขั้นแรกให้เข้าสู่ระบบ Hugging Face Hub หากคุณยังไม่ได้เข้าสู่ระบบ เราจะกำหนดชื่อที่เก็บจาก ID โมเดลที่เราต้องการให้กับโมเดลของเรา (อย่าลังเลที่จะแทนที่ `repo_name` ด้วยตัวเลือกของคุณเอง เพียงต้องมีชื่อผู้ใช้ของคุณ ซึ่งเป็นสิ่งที่ฟังก์ชัน `get_full_repo_name()` ทำ ):
+
+```py
+from huggingface_hub import Repository, get_full_repo_name
+
+model_name = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo_name = get_full_repo_name(model_name)
+repo_name
+```
+
+```python out
+'sgugger/marian-finetuned-kde4-en-to-fr-accelerate'
+```
+
+จากนั้นเราสามารถโคลนพื้นที่เก็บข้อมูลนั้นในโฟลเดอร์ในเครื่องได้ หากมีอยู่แล้ว โฟลเดอร์ในเครื่องนี้ควรเป็นโคลนของพื้นที่เก็บข้อมูลที่เรากำลังทำงานด้วย:
+
+```py
+output_dir = "marian-finetuned-kde4-en-to-fr-accelerate"
+repo = Repository(output_dir, clone_from=repo_name)
+```
+
+ตอนนี้เราสามารถอัปโหลดทุกสิ่งที่เราบันทึกไว้ใน `output_dir` ได้โดยการเรียกเมธอด `repo.push_to_hub()` ซึ่งจะช่วยให้เราอัปโหลดโมเดลระดับกลางในตอนท้ายของแต่ละ epoch ได้
+
+### วงจรการฝึกอบรม[[วงจรการฝึกอบรม]]
+
+ตอนนี้เราพร้อมที่จะเขียนลูปการฝึกอบรมฉบับเต็มแล้ว เพื่อให้ส่วนการประเมินง่ายขึ้น เราได้กำหนดฟังก์ชัน `postprocess()` นี้ ซึ่งใช้การคาดการณ์และป้ายกำกับ และแปลงเป็นรายการสตริงที่ออบเจ็กต์ `metric` ของเราจะคาดหวัง:
+
+```py
+def postprocess(predictions, labels):
+ predictions = predictions.cpu().numpy()
+ labels = labels.cpu().numpy()
+
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+
+ # Replace -100 in the labels as we can't decode them.
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ decoded_labels = [[label.strip()] for label in decoded_labels]
+ return decoded_preds, decoded_labels
+```
+
+วงจรการฝึกอบรมมีลักษณะคล้ายกับใน [ส่วนที่ 2](/course/th/chapter7/2) และ [บทที่ 3](/course/th/chapter3) มาก โดยมีความแตกต่างเล็กน้อยในส่วนการประเมิน ดังนั้นเรามาเน้นที่เรื่องนั้นกันดีกว่า
+
+สิ่งแรกที่ควรทราบคือเราใช้เมธอด `generate()` เพื่อคำนวณการคาดการณ์ แต่นี่เป็นวิธีการในโมเดลพื้นฐานของเรา ไม่ใช่โมเดลที่ห่อ 🤗 Accelerate สร้างขึ้นในเมธอด `prepare()` นั่นคือสาเหตุที่เราแกะโมเดลออกก่อน แล้วจึงเรียกเมธอดนี้
+
+อย่างที่สองก็คือ เช่นเดียวกับ [การจำแนกโทเค็น](/course/th/chapter7/2) สองกระบวนการอาจมีการเสริมอินพุตและป้ายกำกับเป็นรูปร่างที่แตกต่างกัน ดังนั้นเราจึงใช้ `accelerator.pad_across_processes()` เพื่อทำการคาดการณ์และป้ายกำกับ รูปร่างเดียวกันก่อนที่จะเรียกเมธอด `gather()` หากเราไม่ทำเช่นนี้ การประเมินจะเกิดข้อผิดพลาดหรือหยุดทำงานตลอดไป
+
+```py
+from tqdm.auto import tqdm
+import torch
+
+progress_bar = tqdm(range(num_training_steps))
+
+for epoch in range(num_train_epochs):
+ # Training
+ model.train()
+ for batch in train_dataloader:
+ outputs = model(**batch)
+ loss = outputs.loss
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+
+ # Evaluation
+ model.eval()
+ for batch in tqdm(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ max_length=128,
+ )
+ labels = batch["labels"]
+
+ # Necessary to pad predictions and labels for being gathered
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+
+ predictions_gathered = accelerator.gather(generated_tokens)
+ labels_gathered = accelerator.gather(labels)
+
+ decoded_preds, decoded_labels = postprocess(predictions_gathered, labels_gathered)
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ results = metric.compute()
+ print(f"epoch {epoch}, BLEU score: {results['score']:.2f}")
+
+ # Save and upload
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False
+ )
+```
+
+```python out
+epoch 0, BLEU score: 53.47
+epoch 1, BLEU score: 54.24
+epoch 2, BLEU score: 54.44
+```
+
+เมื่อเสร็จแล้ว คุณควรมีโมเดลที่มีผลลัพธ์ค่อนข้างคล้ายกับโมเดลที่ได้รับการฝึกด้วย `Seq2SeqTrainer` คุณสามารถตรวจสอบอันที่เราฝึกได้โดยใช้โค้ดนี้ที่ [*huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate*](https://huggingface.co/huggingface-course/marian-finetuned-kde4-en-to-fr-accelerate) และหากคุณต้องการทดสอบการปรับแต่งใดๆ ในลูปการฝึก คุณสามารถนำไปใช้ได้โดยตรงโดยแก้ไขโค้ดที่แสดงด้านบน!
+
+{/if}
+
+## การใช้โมเดลที่ปรับแต่งแล้ว[[การใช้โมเดลที่ปรับแต่งแล้ว]]
+
+เราได้แสดงให้คุณเห็นแล้วว่าคุณสามารถใช้โมเดลที่เราปรับแต่งอย่างละเอียดบน Model Hub ด้วยวิดเจ็ตการอนุมานได้อย่างไร หากต้องการใช้ภายในเครื่องใน `pipeline` เราเพียงแค่ต้องระบุตัวระบุโมเดลที่เหมาะสม:
+
+```py
+from transformers import pipeline
+
+# Replace this with your own checkpoint
+model_checkpoint = "huggingface-course/marian-finetuned-kde4-en-to-fr"
+translator = pipeline("translation", model=model_checkpoint)
+translator("Default to expanded threads")
+```
+
+```python out
+[{'translation_text': 'Par défaut, développer les fils de discussion'}]
+```
+
+ตามที่คาดไว้ โมเดลที่ได้รับการฝึกล่วงหน้าของเราจะปรับความรู้ให้เข้ากับคลังข้อมูลที่เราปรับแต่ง และแทนที่จะปล่อยให้คำว่า "threads" ในภาษาอังกฤษเพียงอย่างเดียว ตอนนี้กลับแปลเป็นเวอร์ชันทางการของภาษาฝรั่งเศส เช่นเดียวกับ "plugin":
+
+```py
+translator(
+ "Unable to import %1 using the OFX importer plugin. This file is not the correct format."
+)
+```
+
+```python out
+[{'translation_text': "Impossible d'importer %1 en utilisant le module externe d'importation OFX. Ce fichier n'est pas le bon format."}]
+```
+
+อีกตัวอย่างที่ดีของการปรับใช้โดเมน!
+
+
+
+✏️ **ตาคุณแล้ว!** โมเดลส่งคืนอะไรในตัวอย่างที่มีคำว่า "email" ที่คุณระบุไว้ก่อนหน้านี้
+
+
diff --git a/chapters/th/chapter7/5.mdx b/chapters/th/chapter7/5.mdx
new file mode 100644
index 000000000..090f19d48
--- /dev/null
+++ b/chapters/th/chapter7/5.mdx
@@ -0,0 +1,1072 @@
+
+
+# การสรุปความหมาย[[การสรุปความหมาย]]
+
+{#if fw === 'pt'}
+
+
+
+{:else}
+
+
+
+{/if}
+
+
+ในส่วนนี้ เราจะมาดูกันว่าโมเดล Transformer สามารถใช้เพื่อย่อเอกสารขนาดยาวให้เป็นบทสรุปได้อย่างไร งานที่เรียกว่า _text summarization_ นี่เป็นหนึ่งในงาน NLP ที่ท้าทายที่สุด เนื่องจากต้องใช้ความสามารถที่หลากหลาย เช่น การทำความเข้าใจข้อความที่ยาว และการสร้างข้อความที่สอดคล้องกันซึ่งรวบรวมหัวข้อหลักในเอกสาร อย่างไรก็ตาม เมื่อทำได้ดี การสรุปข้อความเป็นเครื่องมืออันทรงพลังที่สามารถเพิ่มความเร็วให้กับกระบวนการทางธุรกิจต่างๆ โดยแบ่งเบาภาระของผู้เชี่ยวชาญโดเมนในการอ่านเอกสารขนาดยาวอย่างละเอียด
+
+
+
+แม้ว่าจะมีโมเดลที่ได้รับการปรับแต่งอย่างละเอียดสำหรับการสรุปอยู่แล้วบน [Hugging Face Hub](https://huggingface.co/models?pipeline_tag=summarization&sort=downloads) แต่โมเดลเกือบทั้งหมดเหมาะสำหรับเอกสารภาษาอังกฤษเท่านั้น ดังนั้น เพื่อเพิ่มความแปลกใหม่ในส่วนนี้ เราจะฝึกโมเดลสองภาษาสำหรับภาษาอังกฤษและสเปน ในตอนท้ายของส่วนนี้ คุณจะมี [model](https://huggingface.co/huggingface-course/mt5-small-finetuned-amazon-en-es) ที่สามารถสรุปบทวิจารณ์ของลูกค้าได้เหมือนกับที่แสดงไว้ที่นี่ :
+
+
+
+ดังที่เราจะเห็นว่าการสรุปเหล่านี้มีความกระชับเนื่องจากได้เรียนรู้จากชื่อที่ลูกค้าระบุไว้ในการวิจารณ์ผลิตภัณฑ์ของตน เริ่มต้นด้วยการรวบรวมคลังข้อมูลสองภาษาที่เหมาะสมสำหรับงานนี้
+
+## การเตรียมคลังข้อมูลหลายภาษา[[การเตรียมคลังข้อมูลหลายภาษา]]
+
+เราจะใช้ [Multilingual Amazon Reviews Corpus](https://huggingface.co/datasets/amazon_reviews_multi) เพื่อสร้างตัวสรุปสองภาษาของเรา คลังข้อมูลนี้ประกอบด้วยบทวิจารณ์ผลิตภัณฑ์ของ Amazon ในหกภาษา และโดยทั่วไปจะใช้เพื่อเปรียบเทียบตัวแยกประเภทหลายภาษา อย่างไรก็ตาม เนื่องจากการรีวิวแต่ละครั้งมีชื่อย่อประกอบ เราจึงสามารถใช้ชื่อดังกล่าวเป็นบทสรุปเป้าหมายเพื่อให้โมเดลของเราเรียนรู้ได้! ในการเริ่มต้น ให้ดาวน์โหลดชุดย่อยภาษาอังกฤษและสเปนจาก Hugging Face Hub:
+
+```python
+from datasets import load_dataset
+
+spanish_dataset = load_dataset("amazon_reviews_multi", "es")
+english_dataset = load_dataset("amazon_reviews_multi", "en")
+english_dataset
+```
+
+```python out
+DatasetDict({
+ train: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 200000
+ })
+ validation: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 5000
+ })
+ test: Dataset({
+ features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
+ num_rows: 5000
+ })
+})
+```
+
+อย่างที่คุณเห็น สำหรับแต่ละภาษา มีบทวิจารณ์ 200,000 รายการสำหรับการแยก 'train' และ 5,000 บทวิจารณ์สำหรับการแยก `validation` และ `test` แต่ละรายการ ข้อมูลบทวิจารณ์ที่เราสนใจมีอยู่ในคอลัมน์ `review_body` และ `review_title` ลองมาดูตัวอย่างบางส่วนโดยการสร้างฟังก์ชันง่ายๆ ที่จะสุ่มตัวอย่างจากชุดการฝึกด้วยเทคนิคที่เราเรียนรู้ใน [บทที่ 5](/course/th/chapter5):
+
+```python
+def show_samples(dataset, num_samples=3, seed=42):
+ sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
+ for example in sample:
+ print(f"\n'>> Title: {example['review_title']}'")
+ print(f"'>> Review: {example['review_body']}'")
+
+
+show_samples(english_dataset)
+```
+
+```python out
+'>> Title: Worked in front position, not rear'
+'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
+
+'>> Title: meh'
+'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
+
+'>> Title: Can\'t beat these for the money'
+'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
+```
+
+
+
+✏️ **ลองดูสิ!** เปลี่ยนการสุ่ม seed ในคำสั่ง `Dataset.shuffle()` เพื่อสำรวจบทวิจารณ์อื่นๆ ในคลังข้อมูล หากคุณเป็นผู้พูดภาษาสเปน ลองดูบทวิจารณ์บางส่วนใน `spanish_dataset` เพื่อดูว่าชื่อต่างๆ ดูเหมือนเป็นบทสรุปที่สมเหตุสมผลหรือไม่
+
+
+
+ตัวอย่างนี้แสดงความหลากหลายของบทวิจารณ์ที่มักพบทางออนไลน์ ตั้งแต่เชิงบวกไปจนถึงเชิงลบ (และทุกอย่างในระหว่างนั้น!) แม้ว่าตัวอย่างที่มีชื่อ "meh" จะไม่ได้ให้ข้อมูลมากนัก แต่ชื่ออื่นๆ ก็ดูเหมือนเป็นการสรุปบทวิจารณ์ที่ดีพอสมควร การฝึกอบรมโมเดลการสรุปสำหรับการตรวจสอบทั้งหมด 400,000 รายการอาจใช้เวลานานเกินไปบน GPU ตัวเดียว ดังนั้น เราจะมุ่งเน้นไปที่การสร้างข้อมูลสรุปสำหรับโดเมนเดียวของผลิตภัณฑ์แทน เพื่อให้เข้าใจว่าเราสามารถเลือกโดเมนใดได้ ให้แปลง `english_dataset` เป็น `pandas.DataFrame` และคำนวณจำนวนบทวิจารณ์ต่อหมวดหมู่ผลิตภัณฑ์:
+
+```python
+english_dataset.set_format("pandas")
+english_df = english_dataset["train"][:]
+# Show counts for top 20 products
+english_df["product_category"].value_counts()[:20]
+```
+
+```python out
+home 17679
+apparel 15951
+wireless 15717
+other 13418
+beauty 12091
+drugstore 11730
+kitchen 10382
+toy 8745
+sports 8277
+automotive 7506
+lawn_and_garden 7327
+home_improvement 7136
+pet_products 7082
+digital_ebook_purchase 6749
+pc 6401
+electronics 6186
+office_product 5521
+shoes 5197
+grocery 4730
+book 3756
+Name: product_category, dtype: int64
+```
+
+สินค้ายอดนิยมในชุดข้อมูลภาษาอังกฤษคือสินค้าในครัวเรือน เสื้อผ้า และอุปกรณ์อิเล็กทรอนิกส์ไร้สาย อย่างไรก็ตาม เพื่อให้ยึดถือธีมของ Amazon ต่อไป เราจะมุ่งเน้นไปที่การสรุปบทวิจารณ์หนังสือ เพราะนี่คือสิ่งที่บริษัทก่อตั้งขึ้น! เราเห็นหมวดหมู่ผลิตภัณฑ์สองหมวดหมู่ที่เหมาะกับใบเรียกเก็บเงิน (`หนังสือ` และ `digital_ebook_purchase`) ดังนั้น เรามากรองชุดข้อมูลทั้งสองภาษาสำหรับผลิตภัณฑ์เหล่านี้เท่านั้น ดังที่เราเห็นใน [บทที่ 5](/course/th/chapter5) ฟังก์ชัน `Dataset.filter()` ช่วยให้เราสามารถแบ่งชุดข้อมูลได้อย่างมีประสิทธิภาพมาก ดังนั้นเราจึงกำหนดฟังก์ชันง่ายๆ เพื่อทำสิ่งนี้ได้:
+
+```python
+def filter_books(example):
+ return (
+ example["product_category"] == "book"
+ or example["product_category"] == "digital_ebook_purchase"
+ )
+```
+
+ตอนนี้เมื่อเราใช้ฟังก์ชันนี้กับ `english_dataset` และ `spanish_dataset` ผลลัพธ์จะมีเฉพาะแถวที่เกี่ยวข้องกับหมวดหมู่หนังสือ ก่อนที่จะใช้ตัวกรอง มาเปลี่ยนรูปแบบของ `english_dataset` จาก `"pandas"` กลับไปเป็น `"arrow"`:
+
+```python
+english_dataset.reset_format()
+```
+
+จากนั้น เราสามารถใช้ฟังก์ชันตัวกรอง และเพื่อเป็นการตรวจสอบความเหมาะสม เราจะตรวจสอบตัวอย่างบทวิจารณ์เพื่อดูว่าเกี่ยวข้องกับหนังสือจริงหรือไม่:
+
+```python
+spanish_books = spanish_dataset.filter(filter_books)
+english_books = english_dataset.filter(filter_books)
+show_samples(english_books)
+```
+
+```python out
+'>> Title: I\'m dissapointed.'
+'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
+
+'>> Title: Good art, good price, poor design'
+'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
+
+'>> Title: Helpful'
+'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
+```
+
+โอเค เราจะเห็นว่าบทวิจารณ์ไม่ได้เกี่ยวกับหนังสืออย่างเคร่งครัด และอาจอ้างถึงสิ่งต่างๆ เช่น ปฏิทินและแอปพลิเคชันอิเล็กทรอนิกส์ เช่น OneNote อย่างไรก็ตาม ดูเหมือนว่าโดเมนจะมีสิทธิ์ในการฝึกอบรมโมเดลการสรุป ก่อนที่เราจะดูโมเดลต่างๆ ที่เหมาะกับงานนี้ เรามีการเตรียมข้อมูลขั้นตอนสุดท้ายที่ต้องทำ: รวมบทวิจารณ์ภาษาอังกฤษและสเปนเป็นออบเจ็กต์ `DatasetDict` เดียว 🤗 Dataset มีฟังก์ชัน `concatenate_datasets()` ที่มีประโยชน์ ซึ่ง (ตามชื่อที่แนะนำ) จะซ้อนวัตถุ `Dataset` สองชิ้นไว้ซ้อนกัน ดังนั้น ในการสร้างชุดข้อมูลสองภาษา เราจะวนซ้ำแต่ละการแยก เชื่อมต่อชุดข้อมูลสำหรับการแยกนั้น และสับเปลี่ยนผลลัพธ์เพื่อให้แน่ใจว่าแบบจำลองของเราจะไม่พอดีกับภาษาเดียว:
+
+```python
+from datasets import concatenate_datasets, DatasetDict
+
+books_dataset = DatasetDict()
+
+for split in english_books.keys():
+ books_dataset[split] = concatenate_datasets(
+ [english_books[split], spanish_books[split]]
+ )
+ books_dataset[split] = books_dataset[split].shuffle(seed=42)
+
+# Peek at a few examples
+show_samples(books_dataset)
+```
+
+```python out
+'>> Title: Easy to follow!!!!'
+'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
+
+'>> Title: PARCIALMENTE DAÑADO'
+'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
+
+'>> Title: no lo he podido descargar'
+'>> Review: igual que el anterior'
+```
+
+ดูเหมือนว่ารีวิวนี้เป็นการผสมผสานระหว่างรีวิวภาษาอังกฤษและสเปนอย่างแน่นอน! ตอนนี้เรามีคลังข้อมูลการฝึกอบรมแล้ว สิ่งสุดท้ายที่ต้องตรวจสอบคือการแจกแจงคำในบทวิจารณ์และชื่อเรื่อง นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับงานการสรุป โดยที่การสรุปอ้างอิงสั้นๆ ในข้อมูลสามารถโน้มน้าวโมเดลให้ส่งออกเพียงหนึ่งหรือสองคำในสรุปที่สร้างขึ้นได้ โครงเรื่องด้านล่างแสดงการแจกแจงคำ และเราจะเห็นว่าชื่อเรื่องมีการบิดเบือนอย่างมากไปเพียง 1-2 คำ:
+
+
+

+

+
+

+

+
+

+

+
+

+

+
-100 เป็นป้ายกำกับสำหรับโทเค็นที่เราต้องการเพิกเฉยใน loss"
+ },
+ {
+ text: "เราจำเป็นต้องตรวจสอบให้แน่ใจว่าได้ตัดหรือแพดฉลากให้มีขนาดเดียวกันกับอินพุต เมื่อใช้การตัดทอน/แพดดิ้ง",
+ explain: "อย่างแท้จริง! นั่นไม่ใช่ความแตกต่างเพียงอย่างเดียว",
+ correct: true
+ }
+ ]}
+/>
+
+### 3. ปัญหาอะไรเกิดขึ้นเมื่อเราโทเค็นคำในปัญหาการจำแนกโทเค็นและต้องการติดป้ายกำกับโทเค็น?
+
+-100 เหล่านี้เพื่อที่พวกมันจะถูกละเว้นใน loss"
+ },
+ {
+ text: "แต่ละคำสามารถสร้างโทเค็นได้หลายรายการ ดังนั้นเราจึงมีโทเค็นมากกว่าที่เรามีป้ายกำกับ",
+ explain: "นั่นคือปัญหาหลัก และเราจำเป็นต้องปรับป้ายกำกับเดิมให้ตรงกับโทเค็น",
+ correct: true
+ },
+ {
+ text: "โทเค็นที่เพิ่มไม่มีป้ายกำกับ ดังนั้นจึงไม่มีปัญหา",
+ explain: "นั่นไม่ถูกต้อง เราต้องการป้ายกำกับให้มากที่สุดเท่าที่เรามีโทเค็น ไม่เช่นนั้นแบบจำลองของเราจะเกิดข้อผิดพลาด"
+ }
+ ]}
+/>
+
+### 4. "การปรับโดเมน (domain adaptation)" หมายถึงอะไร?
+
+
+
+### 5. อะไรคือป้ายกำกับ (label) ในปัญหาการสร้างแบบจำลองภาษาที่ปกปิด (masked language modeling)?
+
+
+
+### 6. งานใดต่อไปนี้ที่สามารถมองได้ว่าเป็นปัญหาแบบลำดับต่อลำดับ (sequence-to-sequence)?
+
+
+
+### 7. วิธีที่เหมาะสมในการประมวลผลข้อมูลล่วงหน้าสำหรับปัญหาตามลำดับ (sequence-to-sequence) คืออะไร?
+
+inputs=... และ targets=...",
+ explain: "นี่อาจเป็น API ที่เราเพิ่มในอนาคต แต่ตอนนี้ไม่สามารถทำได้"
+ },
+ {
+ text: "อินพุตและเป้าหมายทั้งสองจะต้องได้รับการประมวลผลล่วงหน้า โดยเรียกโทเค็นไนเซอร์แยกกันสองครั้ง",
+ explain: "นั่นเป็นเรื่องจริงแต่ไม่สมบูรณ์ มีสิ่งที่คุณต้องทำเพื่อให้แน่ใจว่า tokenizer ประมวลผลทั้งสองอย่างถูกต้อง"
+ },
+ {
+ text: "ตามปกติเราเพียงแค่ต้องโทเค็นอินพุต",
+ explain: "ไม่อยู่ในปัญหาการจำแนกลำดับ เป้าหมายก็คือข้อความที่เราต้องแปลงเป็นตัวเลขด้วย!"
+ },
+ {
+ text: "อินพุตจะต้องถูกส่งไปยัง tokenizer และเป้าหมายด้วย แต่อยู่ภายใต้ตัวจัดการบริบทพิเศษ",
+ explain: "ถูกต้อง โทเค็นไนเซอร์จะต้องถูกใส่เข้าสู่โหมดเป้าหมายโดยตัวจัดการบริบทนั้น",
+ correct: true
+ }
+ ]}
+/>
+
+{#if fw === 'pt'}
+
+### 8. เหตุใดจึงมีคลาสย่อยเฉพาะของ 'Trainer' สำหรับปัญหาตามลำดับ (sequence-to-sequence)?
+
+-100",
+ explain: "นั่นไม่ใช่การสูญเสียที่กำหนดเอง แต่เป็นวิธีการคำนวณการสูญเสีย (loss) เสมอ"
+ },
+ {
+ text: "เนื่องจากปัญหาแบบลำดับต่อลำดับจำเป็นต้องมีการวนรอบการประเมินพิเศษ",
+ explain: "ถูกต้อง. การคาดการณ์ของโมเดลแบบเรียงลำดับตามลำดับมักจะทำงานโดยใช้เมธอด generate()",
+ correct: true
+ },
+ {
+ text: "เพราะเป้าหมายคือข้อความในโจทย์ปัญหาตามลำดับ",
+ explain: "Trainer ไม่สนใจเรื่องนี้มากนัก เนื่องจากเคยได้รับการประมวลผลมาก่อนแล้ว"
+ },
+ {
+ text: "เนื่องจากเราใช้สองแบบจำลองในการแก้ปัญหาตามลำดับ",
+ explain: "เราใช้โมเดลสองแบบในวิธีหนึ่ง นั่นคือตัวเข้ารหัสและตัวถอดรหัส แต่จะรวมกลุ่มเข้าด้วยกันเป็นโมเดลเดียว"
+ }
+ ]}
+/>
+
+{:else}
+
+### 9. เหตุใดจึงมักไม่จำเป็นต้องระบุการสูญเสีย (loss) เมื่อเรียก `compile()` ในโมเดล Transformer?
+
+
+
+{/if}
+
+### 10. เมื่อใดที่คุณควรฝึกโมเดลใหม่ล่วงหน้า?
+
+
+
+### 11. เหตุใดจึงเป็นเรื่องง่ายที่จะฝึกโมเดลภาษาล่วงหน้ากับข้อความจำนวนมาก?
+
+
+
+### 12. อะไรคือความท้าทายหลักเมื่อประมวลผลข้อมูลล่วงหน้าสำหรับงานตอบคำถาม (question-answering task)?
+
+
+
+### 13. โดยทั่วไปแล้วการประมวลผลภายหลังจะตอบคำถามอย่างไร?
+
+