Releases: huggingface/trl
v0.6.0
DDPO for diffusion models
We are excited to welcome the first RLHF + diffusion models algorithm to refine the generations from diffusion models.
Read more about it directly in the docs.
| Before | After DDPO finetuning |
|---|---|
 |
 |
 |
 |
- Denoising Diffusion Policy Optimization by @metric-space in #508
Bug fixes and other enhancements
The release also comes with multiple bug fixes reported and/or led by the community, check out the commit history below
What's Changed
- Release: v0.5.0 by @younesbelkada in #607
- Set dev version by @younesbelkada in #608
- [
Modeling] Add token support forhf_hub_downloadby @younesbelkada in #604 - Add docs explaining logged metrics by @vwxyzjn in #616
- [DPO] stack-llama-2 training scripts by @kashif in #611
- Use log_with argument in SFT example by @hitorilabs in #620
- Allow already tokenized sequences for
response_templateinDataCollatorForCompletionOnlyLMby @ivsanro1 in #622 - Improve docs by @lvwerra in #612
- Move repo by @lvwerra in #628
- Add score scaling/normalization/clipping by @zfang in #560
- Disable dropout in DPO Training by @NouamaneTazi in #639
- Add checks on backward batch size by @vwxyzjn in #651
- Resolve various typos throughout the docs by @tomaarsen in #654
- Update README.md by @Santosh-Gupta in #657
- Allow for ref_model=None in DPOTrainer by @vincentmin in #640
- Add more args to SFT example by @photomz in #642
- Handle potentially long sequences with DataCollatorForCompletionOnlyLM by @tannonk in #644
- [
sft_llama2] Add check of arguments by @younesbelkada in #660 - Fix DPO blogpost thumbnail by @lvwerra in #673
- propagating eval_batch_size to TrainingArguments by @rahuljha in #675
- [
CI] Fix unmutableTrainingArgumentsissue by @younesbelkada in #676 - Update sft_llama2.py by @msaad02 in #678
- fix PeftConfig loading from a remote repo. by @w32zhong in #649
- Simplify immutable TrainingArgs fix using
dataclasses.replaceby @tomaarsen in #682
New Contributors
- @hitorilabs made their first contribution in #620
- @ivsanro1 made their first contribution in #622
- @zfang made their first contribution in #560
- @NouamaneTazi made their first contribution in #639
- @Santosh-Gupta made their first contribution in #657
- @vincentmin made their first contribution in #640
- @photomz made their first contribution in #642
- @tannonk made their first contribution in #644
- @rahuljha made their first contribution in #675
- @msaad02 made their first contribution in #678
- @w32zhong made their first contribution in #649
Full Changelog: v0.5.0...v0.6.0
Contributors
Assets 2
v0.5.0
v0.5.0 DPOTrainer and multiple bug fixes on PPOTrainer and SFTTrainer
This release includes multiple important bugfixes (SFTTrainer, PPOTrainer), the release also extends the current DataCollatorForCompletionOnlyLM to support chat-like training.
DPO Trainer
The DPO algorithm (Direct Policy Optimization) has been introduced by Rafailov et al. in this paper and introduces a way of performing RL training without having to rely on a reward model. The DPOTrainer is now part of TRL library for anyone that wants to use it thanks to the amazing contributors!
- DPO Trainer by @kashif in #416
- [DPO] make sure all the concated batches are on same device by @kashif in #528
- [DPO] remove response/pairs from the DPO side by @kashif in #540
- [DPO] remove unnecessary batch size arg to Collator by @kashif in #554
- [
DPO] Resolve logging for DPOTrainer by @tomaarsen in #570
What's Changed
- Reward trainer multi-gpu eval bug by @rlindskog in #513
- Use local process index for
_get_current_device()by @lewtun in #515
Extending the DataCollatorForCompletionOnlyLM
You can now mask out the users prompts in the DataCollatorForCompletionOnlyLM data collator and train only on chat completions. Check out the PR below or the appropriate section on the documentation to learn more about it!
- Introducing DataCollatorForChatCompletionOnlyLM by @gaetanlop in #456
Important bug fixes
Multiple bugs on the supported trainers have been raised by the community and fixed in the below PRs
- [
core] Fix offline case by @younesbelkada in #538 - Relax reward trainer constraint by @younesbelkada in #539
- ADD: num_proc to SFTTrainer by @BramVanroy in #547
- [
SFTTrainer] Add warning for wrong padding_side by @younesbelkada in #550 - Minor typo and whitespace fixes by @tmm1 in #559
- [
SFTTrainer] Add epochs and num steps on CLI by @younesbelkada in #562 - Add
DataCollatorForCompletionOnlyLMin the docs by @younesbelkada in #565 - Add comment to explain how the sentiment pipeline is used to run the … by @jvhoffbauer in #555
- Fix model output dim in reward trainer example by @liutianlin0121 in #566
- Computes the KL penalty using the entire distribution by @edbeeching in #541
- Add missing max_seq_length arg to example sft_trainer.py by @SharkWipf in #585
- [
PPO] fix corner cases with PPO batch size and forward_batch_size by @younesbelkada in #563 - Update the example sft_trainer.py by @ZeusFSX in #587
- docs: Replace SFTTrainer with RewardTrainer in comment by @tomaarsen in #589
- Fix comparison in DataCollatorForCompletionOnlyLM (#588) by @RyujiTamaki in #594
- refactor grad accum by @vwxyzjn in #546
Big refactor of examples and documentation
The examples and documentation has been refactored, check the PRs below for more details
- [
examples] Big refactor of examples and documentation by @younesbelkada in #509 - [
examples] Fix sentiment nit by @younesbelkada in #517 - [
examples] make the sft script more modulable by @younesbelkada in #543 - Add
use_auth_tokenarg to sft_trainer example by @corey-lambda in #544
New Contributors
- @rlindskog made their first contribution in #513
- @corey-lambda made their first contribution in #544
- @tmm1 made their first contribution in #559
- @jvhoffbauer made their first contribution in #555
- @liutianlin0121 made their first contribution in #566
- @SharkWipf made their first contribution in #585
- @ZeusFSX made their first contribution in #587
- @gaetanlop made their first contribution in #456
- @RyujiTamaki made their first contribution in #594
Full Changelog: v0.4.7...v0.5.0
Contributors
Assets 2
v0.4.7
Patch release: SFTTrainer and PPOTrainer bug fixes
What's Changed
- Make shuffle optional by @lopez-hector in #457
- Pre-commit by @vwxyzjn in #448
- Debug the tortuous logic in
_prepare_datasetfunction by @BeibinLi in #464 - [
CI] Fix CI RM by @younesbelkada in #468 - Update sft_trainer.py by @JulesGM in #474
- Refactor README by @younesbelkada in #460
- add ratio threshold to avoid spikes by @lvwerra in #488
- fix typo in reward_modeling.py by @csyourui in #494
- FIX: contributing guidelines command by @BramVanroy in #493
- Remove padding in batched generation. by @lvwerra in #487
- Adds some options to stabilize the KL penalty by @edbeeching in #486
- correctly implement gradient checkpointing to multi-adapter example by @mnoukhov in #479
- Disable mlm by default in DataCollatorForCompletionOnlyLM, add ignore_index and docstring by @BramVanroy in #476
- Use
floatinstead ofdoubleto avoid issues with MPS device by @younesbelkada in #499 - [
PPOTrainer] Add prefix tuning support by @younesbelkada in #501 - [
PPOTrainer] Add prompt tuning support on TRL by @younesbelkada in #500 - [
SFTTrainer] Fix the sequence length check ofSFTTrainerby @younesbelkada in #512
New Contributors
- @lopez-hector made their first contribution in #457
- @BeibinLi made their first contribution in #464
- @csyourui made their first contribution in #494
- @BramVanroy made their first contribution in #493
Full Changelog: v0.4.6...v0.4.7
Contributors
Assets 2
v0.4.6
Patch release
Patch release to fix a bug on google colab with PPOTrainer & PPOConfig + wandb
What's Changed
- Fix google colab issue by @younesbelkada in #459
Full Changelog: v0.4.5...v0.4.6
Contributors
Assets 2
v0.4.5
Patch release 1 - SFTTrainer enhancements and fixes
This patch release adds multiple fixes for the SFTTrainer and enhancements. Another patch release is coming for fixing an issue with PPOTrainer and Google Colab combined with wandb logging
What's Changed
- Add slurm utility by @vwxyzjn in #412
- Enable autotag feature w/ wandb by @vwxyzjn in #411
- [doc build] Use secrets by @mishig25 in #420
- Update test_reward_trainer.py by @younesbelkada in #421
- best-of-n sampler class by @metric-space in #375
- handle the offline case by @younesbelkada in #431
- Fix correct gradient accumulation by @younesbelkada in #407
- Drop support for Python 3.7 by @younesbelkada in #441
- [
SFTTrainer] Relax dataset constraints by @younesbelkada in #442 - [
SFTTrainer] Fix non packed dataset by @younesbelkada in #444 - [
core] Add stale bot by @younesbelkada in #447 - [
SFTTrainer] IntroducingDataCollatorForCompletionOnlyLMby @younesbelkada in #445 - [
ConstantLengthDataset] Fix packed dataset issue by @younesbelkada in #452 - Update accelerate arg passthrourgh for tensorboard logging to reflect logging_dir deprecation. by @jganitkevitch in #437
- Multi adapter RL (MARL) - a single model for RM & Value Head by @younesbelkada in #373
New Contributors
- @jganitkevitch made their first contribution in #437
Full Changelog: v0.4.4...v0.4.5
Contributors
Assets 2
v0.4.4
Contributors
Assets 2
v0.4.3
0.4.3 Patch release
Patch release - pin accelerate version
- Skip flaky test until next transformers release by @younesbelkada in #410
- Pin accelerate version by @younesbelkada in #414
Full Changelog: v0.4.2...v0.4.3
Contributors
Assets 2
v0.4.2
QLoRA RLHF, SFT Trainer and RewardTrainer
A new version of TRL that includes training larger models using QLoRA (4 bit quantization through bitsandbytes), brand new classes RewardTrainer and SFTTrainer to easily conduct your RLHF projects end-to-end!
Introducing SFTTrainer and RewardTrainer
Use the brand new trainer to easily train your reward model and supervised fine-tuned (SFT) model with few lines of code!
- [
core] officially support SFT (Supervised Finetuning) by @younesbelkada in #323 - [
SFT] Fix sft issues by @younesbelkada in #336 - [
docs] fix SFT doc by @younesbelkada in #367 - [
core] Officially Support Reward Modeling by @younesbelkada in #303 - Resolve broken evaluation/prediction for RewardTrainer by @tomaarsen in #404
QLoRA integration
Pass 4bit models directly into PPOTrainer for more memory efficient training
- [
core] Add 4bit QLora by @younesbelkada in #383 - [
bnb] fix 4 bit SFT by @younesbelkada in #396
Updated StackLlama example
Great work by @mnoukhov that managed to fix the issues related with StackLlama and the new versions of accelerate, peft and transformers. The completely reproducible examples below:
- StackLLaMA: correctly merge peft model by @mnoukhov in #398
- StackLlama: fixed RL training and added args by @mnoukhov in #400
- Fixed some type annotations of trl.trainer.PPoTrainer by @JulesGM in #392
- StackLLaMA: fix supervised finetuning and reward model training by @mnoukhov in #399
Bug fixes and improvements
- [
core] refactor peft API by @younesbelkada in #231 - Batched generation by @lvwerra in #228
- Reduce memory consumption in batched_forward_pass by @ohashi56225 in #234
- [
core] Add warning when negative KL by @younesbelkada in #239 - adds early stopping by @edbeeching in #238
- PPO config init is bloated by @GauravVirmani in #241
- feat(ci): enable
pipcache by @SauravMaheshkar in #198 - Improve logging for PPO + Docs page by @natolambert in #243
- Fix typo by @heya5 in #253
- Using batched generate in sentiment scripts by @GauravVirmani in #249
- [
core] Fix DeepSpeed zero-3 issue by @younesbelkada in #182 - [
distributed] Fix early stopping and DP by @younesbelkada in #254 - [
core] Fix ds issue by @younesbelkada in #260 - Add LlaMa in tests +
create_reference_modelby @younesbelkada in #261 - Use active model to generate response in example on README (#269) by @rmill040 in #271
- stack-llama by @edbeeching in #273
- Adding pointer back to Meta's LLaMA. by @meg-huggingface in #277
- fix doc string problem in ppo trainer loss function by @thuwyh in #279
- Add LLaMA tutorial to docs by @natolambert in #278
- Fix swapped helper texts by @philipp-classen in #284
- fix typo in gpt2-sentiment.ipynb by @eltociear in #293
- add functionality to push best models to the hub during training by @Bearnardd in #275
- Small improvements / fixes to toxicity example by @natolambert in #266
- Fix arguments description by @lvzii in #298
- [
t5] Fix negative kl issue by @younesbelkada in #262 - Log Token distribution of Query / Response by @natolambert in #295
- clean examples folder by @natolambert in #294
- fixed typo in error message by @soerenarlt in #312
- fix DS for peft ref_model in ppo trainer by @halfrot in #309
- [
CI] Fix broken tests by @younesbelkada in #318 - [
Docs] Add details on multi-GPU / multi-node by @younesbelkada in #320 - Give a key to the wandb PPOConfig config entry by @JulesGM in #315
- added doc for using torch.distributed.launch/run by @oroojlooy in #324
- Fix argument's description by @vinhkhuc in #339
- stack_llama: update instructions in README, fix broken _get_submodules and save tokenizer by @teticio in #358
- stack_llama: add parameter to control max_length (to mitigate OOM errors) by @teticio in #359
- [
PPO] Relax negative KL constraint by @younesbelkada in #352 - [
PPOTrainer] Fix tensorboard issue by @younesbelkada in #330 - 140/best n sampling by @metric-space in #326
- Fix bug when loading local peft model by @Opdoop in #342
- add is_trainable in kwargs by @Opdoop in #363
- Remove obsolete layer_norm_names parameter and add peft>=0.3.0 to requirements by @teticio in #366
- Delete test_training.py by @younesbelkada in #371
- [
core] Fix warning issue by @younesbelkada in #377 - Update customization.mdx by @binganao in #390
- fix dataloader typo in ppo_trainer.py by @LZY-the-boys in #389
- from_pretrain with peft adapter on the hub (# 379) by @glerzing in #380
- keep state_dict kwargs instead of popping it in save_pretrained by @rizar in #393
- Remove unused imports in docs. by @vwxyzjn in #406
New Contributors
- @ohashi56225 made their first contribution in #234
- @GauravVirmani made their first contribution in #241
- @SauravMaheshkar made their first contribution in #198
- @heya5 made their first contribution in #253
- @rmill040 made their first contribution in #271
- @thuwyh made their first contribution in #279
- @philipp-classen made their first contribution in #284
- @Bearnardd made their first contribution in #275
- @lvzii made their first contribution in #298
- @soerenarlt made their first contribution in #312
- @halfrot made their first contribution in #309
- @oroojlooy made their first contribution in #324
- @vinhkhuc made their first contribution in #339
- @teticio made their first contribution in #358
- @metric-space made their first contribution in #326
- @Opdoop made their first contribution in #342
- @binganao made their first contribution in #390
- @LZY-the-boys made their first contribution in #389
- @glerzing made their first contribution in #380
- @rizar made their first contribution in #393
- @mnoukhov made their first contribution in #398
- @tomaarsen made their first contribution in #404
- @vwxyzjn made their first contribution in #406
Full Changelog: v0.4.1...v0.4.2
Contributors
Assets 2
v0.4.1
Large models training, Naive Pipeline Parallelism, peft Data Parallelism support and distributed training bug fixes
This release includes a set of features and bug fixes to scale up your RLHF experiments for much larger models leveraging peft and bitsandbytes.
Naive Pipeline Parallelism support
- Let's support naive Pipeline Parallelism by @younesbelkada in #210
We introduce a new paradigm in trl , termed as Naive Pipeline Parallelism, to fit large scale models on your training setup and apply RLHF on them. This feature uses peft to train adapters and bitsandbytes to reduce the memory foot print of your active model
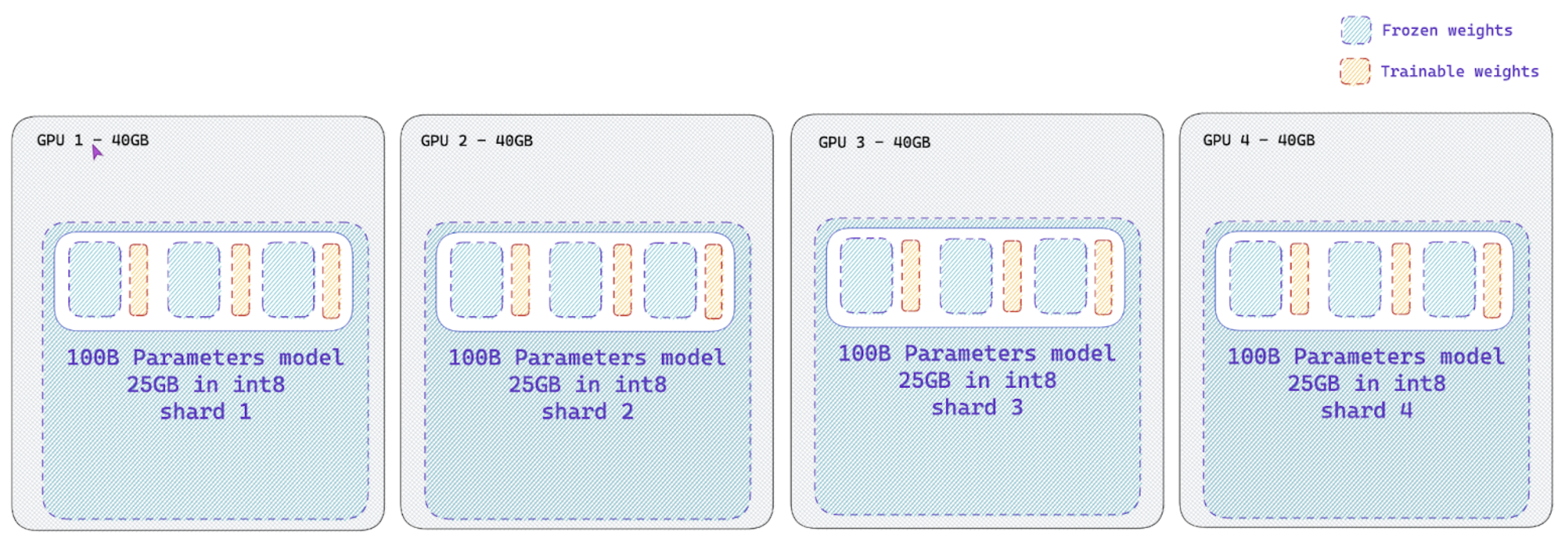
peft Data Parallelism support
- [
peft] Fix DP issues by @younesbelkada in #221 - [
core] fix DP issue by @younesbelkada in #222
There were some bugs with respect to peft integration and DP. This release includes the bug fixes to enable multi-GPU training using accelerate + DDP (DIstributed Data Parallel)
Memory optimization
Your training runs can be now much more memory efficient thanks to few tricks / bug fixes:
Now PPOConfig also supports the flag optimize_cuda_cache (set to False by default) to avoid increasing CUDA memory issues
- Grad accumulation and memory bugfix by @edbeeching in #220
- adds a missing detach to the ratio by @edbeeching in #224
Pytorch 2.0 fixes
This release also includes minor fixes related to PyTorch 2.0 release
- [
test] attempt to fix CI test for PT 2.0 by @younesbelkada in #225
What's Changed
- adds sentiment example for a 20b model by @edbeeching in #208
- Update README.md blog post link by @TeamDman in #212
- spell mistakes by @k-for-code in #213
- spell corrections by @k-for-code in #214
- Small changes when integrating into H4 by @natolambert in #216
New Contributors
Full Changelog: v0.4.0...v0.4.1
Contributors
Assets 2
v0.4.0
v0.4.0: peft integration
Apply RLHF and fine-tune your favorite large model on consumer GPU using peft and trl ! Share also easily your trained RLHF adapters on the Hub with few lines of code
With this integration you can train gpt-neo-x (20B parameter model - 40GB in bfloat16) on a 24GB consumer GPU!
What's Changed
- Allow running evaluate-toxicity with cpu by @jordimas in #195
- [
core] Fix quality issue by @younesbelkada in #197 - Add 1.12.1 torch compatibility in sum method by @PanchenkoYehor in #190
peftintegration by @edbeeching in #163- [
core] Update dependency by @younesbelkada in #206
New Contributors
- @PanchenkoYehor made their first contribution in #190
Full Changelog: v0.3.1...v0.4.0