par Marie Lenogue, Anthony Pena et Clément Tek
Supervisé par Florian Boudin et Hugo Mougard
- Introduction
- Qu'est-ce que le résumé automatique par extraction ?
- Qu'est-ce qu'un concept ?
- ROUGE
- L'État de l'art
- Concepts
- Extraction par optimisation linéaire
- Modèle de régression
- Essais et résultats
- Groupes
- Poids
- Problèmes
- Conclusion
Notre objectif était de tenter de trouver une nouvelle manière d'effectuer un découpage en concepts ou une nouvelle manière de pondérer ceux-ci pour améliorer l'état de l'art et ainsi créer de meilleurs résumés par extraction.
Dans les exigences de départ, nous sommes partis dans l'idée de n'utiliser aucune supervision (donc aucun travail préparatoire humain à la génération du résumé) et aucun apprentissage. La raison est que nous voulons obtenir un système capable de générer un résumer automatiquement peu importe le contexte, le thème des textes et la quantité de texte.
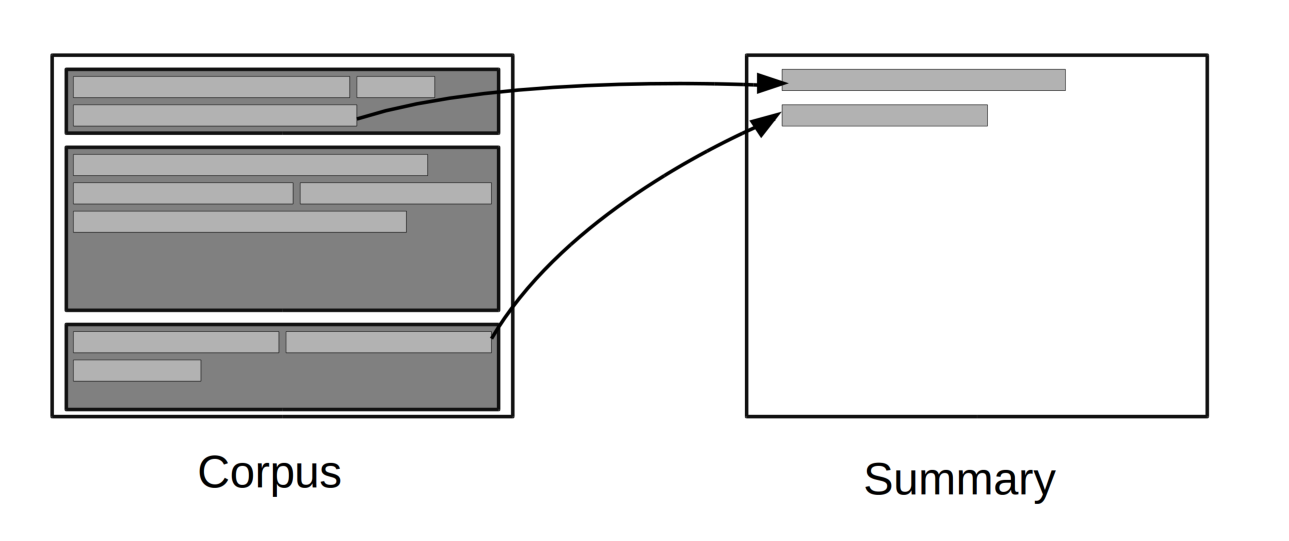
Le principe du résumé automatique par extraction est de partir d'un ensemble de texte (appelé corpus), d'en extraire un certain nombre de phrases, de les trier puis d'en choisir certaines pour constituer un résumé.
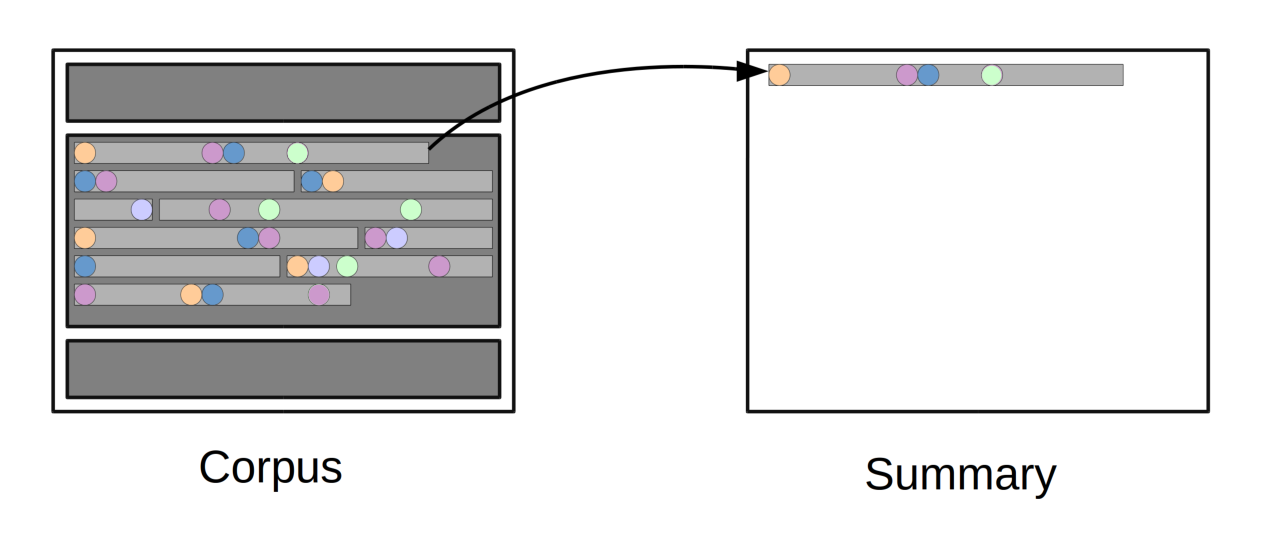
Un concept est une entité, souvent pondérée en concordance avec son importance dans l'étude. Par exemple, la phrase "Le nouveau président va entrer à la maison blanche.", si on choisit de définir que nos concepts sont tous des bigrammes (ou groupe de 2 mots adjacents), alors nous obtenons "Le nouveau", "nouveau président", "président va", ... comme liste de bigrammes. Mais si nous décidons qu'un groupe nominal est un concept alors nous obtenons "Le nouveau président", "va entrer" et "à la maison blanche" comme liste de concepts. Il est aussi possible d'utiliser beaucoup d'autres critères, comme les arbres de dépendances, ou même des mélanger ces méthodes de découpage.
En général, les concepts composés de mot-vide sont éliminés. Les mot-vides sont des mots qui n'apportent aucun sens à la phrase comme "le", "la", "à", etc. Donc notre exemple le bigramme "à la" sera supprimé par exemple.
ROUGE (pour Recall-Oriented Understudy for Gisting Evaluation), est un système de mesure pour les résumés automatiques. Pour attribuer un score à un résumé, il le compare avec plusieurs résumés écrits à la main par des humains et fait la moyennes des scores de correspondance avec chacun d'eux.
Ce système est couramment utilisé dans des compétitions comme le TAC (Text Analysis Conference) et DUC (Document Understanding Conference).
Dans la littérature, seuls les bigrammes de mots sont vraiment considérés. Ils ont l'avantage d'être rapide à produire et de produire de bon résultat. Il est a noter qu'il n'existe pas de travaux sur l'importance du choix de l'unité textuelle utilisée pour les concepts, donc comment pouvons-nous évaluer le choix du type de concept ?
À l'heure actuelle, l'état de l'art a été réalisé par D. Gillick et B. Favre dans leur article A scalable global model for summarization (Juin 2009). Leur idée a été de choisir comme concepts exclusivement des bigrammes de mots (bigrammes de mot-vide exclu), leur attribuer des poids en fonction de la fréquence d'apparition de ceux-ci dans le corpus, puis d'essayer dans une limite de 100 mots de choisir les phrases qui étaient de plus grand poids en maximisant le poids des concepts dans le résumé.
Il est à noter que si nous sélectionnons une phrase Si et que nous l'ajoutons dans le résumé alors tous les concepts qu'elle contient étant déjà présent dans le résumé, leurs poids ne sont plus comptés dans les autres phrases.
Les explications précédentes sont résumées par la formule :

- c : présence du concept dans le résumé (binaire)
- w : le poids attribué au concept
Après une étude de l'état de l'art, nous nous sommes intéressé à d'autres travaux comme ceux de C. Li, X. Qian et Y. Liu (Using Supervised Bigram-based ILP for Extractive Summarization, Août 2013).
Ces travaux montrent l'utilisation d'un certain nombre de traits ajoutés, sur les mots ou les phrases, à l'état de l'art. Les principaux sont :
- La fréquence d'apparition d'un bigramme dans le sujet donné
- la similarité d'une phrase avec le titre
- la similarité d'une phrase avec la concaténation du titre et de la description
- la position de la phrase dans le texte
- la présence du mot ou de la phrase dans le premier paragraphe
Les résultats démontrent que l'amélioration de la qualité des résumés n'est pas significative mais que la génération est plus longue et plus complexe.
Parmi nos tentatives nous avons essayé de considérer la présence de locution nominale qui ne serait pas détectable dans un bigramme, c'est le cas des locutions "point de vue", "suprême de volaille", etc. (en anglais "point of view", "on my way", etc.). En effet si nous prenons "point de vue", on remarque que cette locution possède un sens particulier mais qu'un découpage en bigramme va créer "point de" et "de vue", et donc les sens de "point" et de "vue" seront pris en compte et non celui de la locution.
Le problème de cette approche est qu'il n'y a que deux façons de détecter ces locutions, la première étant l'apprentissage et la seconde l'utilisation d'un dictionnaire. L'utilisation d'apprentissage oblige à avoir un grand volume de texte pour arriver à repérer les locutions potentielles, mais c'est un choix qui ne correspond pas à notre sujet initial. L'utilisation d'un dictionnaire de locutions implique une supervision, donc nous l'avons exclue aussi.
Nous avons envisagé l'utilisation de groupes grammaticaux pour un découpage plus haut niveau des concepts. Par exemple considérer un groupe sujet, un groupe verbal, un complément, etc. ou même la concaténation sujet et verbe. Mais nous nous sommes rendu compte que la redondance de tels concepts était très faible et donc n'apportait pas d'amélioration intéressante. De plus la détection de ces différents éléments n'est pas très précise et est plutôt longue, ce qui ralentirait beaucoup le temps de génération des résumés.
Nous nous sommes aussi intéressés aux poids attribués aux concepts. En effet, l'état de l'art n'utilise que la fréquence d'apparition d'un concept dans le corpus pour déterminer son poids, et ainsi extraire les phrases de plus grand poids. Le problème est que cette démarche dépend beaucoup du corpus : par exemple, une idée peut ne pas être souvent répétée et pourtant être importante.
En étudiant les corpus à notre disposition (TAC 2008), nous avons envisagé d'augmenter le poids des concepts de la première phrase et de la dernière phrase des documents, ce qui marchait très bien. Mais le problème est que notre corpus est composé d'article journalistique en anglais et donc nous retrouvons systématiquement une introduction et une conclusion qui résument les textes. Or, si nous prenons un autre texte (un extrait de roman par exemple), ce constat ne fonctionnera plus.
Nous avons aussi remarqué que les citations sont généralement des phrases ou fragments de phrase qui sont porteurs d'un sens important. Notre idée a alors été de pondérer plus les concepts présents dans des citations pour mettre en valeur les concepts des citations sans casser le reste du système.
Dans la pratique les résultats ne sont pas significatifs, mais les résumés sont un peu plus longs à générer donc nous n'avons pas retenu cette idée.
Le volume de données à manipuler est un vrai frein à l'avancement, le temps de génération des résumés étant assez long, de même pour leur évaluation. Nous avons travaillé sur les corpus du TAC 2008, soit 48 corpus de 10 textes, avec pour chaque corpus entre 150 et 250 phrases. Un résumé étant généré en entre une et deux minutes via l'implémentation en Python de l'état de l'art sans modification, il faut déjà plus d'une heure pour générer et tester les résumés à chaque tentative.
Dans l'optique d'évaluer la marge de progression et d'essayer de déterminer les caractéristiques du meilleur résumé possible par extraction (appelé "gold"), nous nous sommes intéressés à la génération d'un oracle du meilleur résumé possible. La génération de l'ensemble des résumés n'étant pas concevable, un résumé étant composé de 3 à 6 phrases parmi entre 150 et 250 phrases, on obtient entre 551 300 et 319 195 444 750 combinaison ce qui prendrait plusieurs mois de génération. Nous avons donc opté pour une approximation de ce meilleur résumé en sélectionnant les 10 meilleures phrases d'un corpus avant de générer toutes combinaisons possible.
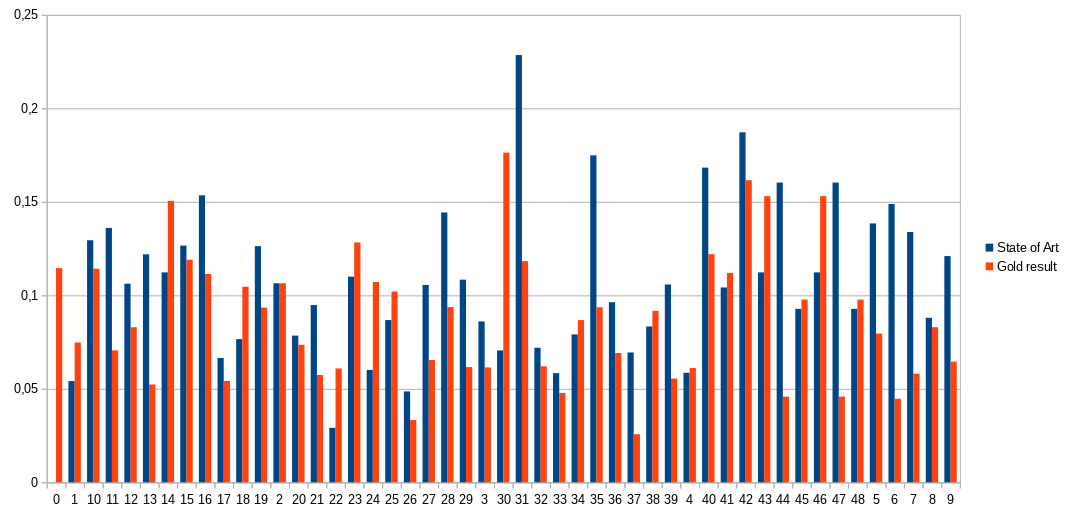
Les résultats de cette approximation montrent que notre démarche n'a pas été concluante car les gold générés ont un score inférieur à celui de l'état de l'art, ce qui n'est pas possible. Nous avons supposé que cela provenait du fait que notre sélection était trop réduite, nous avons donc essayé d'augmenter la sélection d'origine à 15 (passant le total de résumé pour les 48 corpus d'environ 12 000 à 80 000), mais des résultats similaires nous ont poussés vers l'idée que l'approche que nous avions n'était pas correcte.
La génération de résumés automatique est un domaine de recherche de grande complexité, et l'amélioration de l'état de l'art est un objectif difficile à atteindre. L'exploration des différentes pistes que nous avons trouvées nous a permis d'éliminer des possibilités, et surtout d'aborder la recherche sur un véritable problème de recherche.
En complément des acquisitions techniques telles que l'utilisation d'un solveur d'optimisation et la programmation linéaire, nous nous sommes intéressés à l'étude d'articles scientifiques, ainsi qu'à la notion de choix et de compromis quant aux résultats.
Il aurait toutefois été intéressant d'être accompagnés d'un étudiant du master ORO pour accélérer l'avancée sur l'optimisation et la programmation linéaire, ces sujets n'étant pas abordés dans nos formations respectives (ALMA et ATAL).