Slow train loop compared to python #694
Comments
|
After dropping the use of and getting half time 😮
|

|
Yes, this is still kind of expected. We still need to make performance improvements in the R side. Specially related to dataloading and in the optimizers code. However, small examples are likely to show higher differences because code is probably spending more time in R/Python code than in the efficient C++ libtorch code that both the Python and the R packages share. |
|
that is true the optimizer step function takes a lot of time while the training loop 👇
|

|
I'm new to Torch for R, haven't found a reference to a mailing list where it would be maybe more appropriate to discuss this, so I'll leave my comment here. Am also rather surprised on how slow the training is in Torch for R when compared to Python. So I have following hello-world-MNIST code on Python: and then what I think is an equivalent in R: I did runs in both cases with training/test data already downloaded. My GPU is rather old Quadro P3000, still adequate enough for this small problem. Python code takes about 33s to train, while R code takes about 2020s, so about 60x slower. Note that For the record, C++ libtorch code, completely equivalent to above Python code, takes 5s to train. Considering that most of performance-critical code in PyTorch is actually shared with libtorch, the PyTorch performance is rather disappointing too. On the other side, admittedly, C++ code takes twice as long to compile than to run on my laptop: the code itself has about 120 lines, but as libtorch is heavily templated, the preprocessed file actually sent to compiler is about 320k lines long. (As an additional note, equivalent Keras R code takes about 15s to train.) |
|
I want to +1 on this comment. I am very interested moving to this package, but the training times I'm experiencing are orders of magnitude larger than with Keras/Tensorflow. This moves the torch package from the go-to package to something I may dust off every once in a while for a edge case. Hope this can be optimized soon. |
|
We were trying to profile R torch to see where the performance difference to pytorch comes from. For this, we used the code below, which takes around 20 seconds. library(torch)
p = 100
steps = 10000
n = 1000
X = torch_randn(n, p, device = "cuda")
beta = torch_randn(p, 1, device = "cuda")
Y = X$matmul(beta)
latent = 5000
net = nn_sequential(
nn_linear(p, latent),
nn_relu(),
nn_linear(latent, 1)
)
net$cuda()
t1 = Sys.time()
p = profvis::profvis({
for (i in 1:steps) {
Y_hat = net(X)
loss = nnf_mse_loss(Y, Y_hat)
}
}, simplify = FALSE)
t2 = Sys.time()
htmlwidgets::saveWidget(p, "~/torch.html", selfcontained = TRUE)
print(paste0("Total time: ", t2 - t1))Below is a screenshot of the Flame graph, where the grey areas are the time spent for garbage collection. If this data is correct (and no funny business happens with profvis) this means around 3/4 of the time in this loop is spent for garbage collection. This means that without garbage collection, torch would take around 4 - 5 seconds compared to pytorchs 3 seconds. |

|
I recommend taking a look at this section in the documentation: https://torch.mlverse.org/docs/articles/memory-management#cuda Basically, when you are in a situation of high memory pressure within the GPU, we'll need to force GC at every iteration because otherwise libtorch can't allocate gpu memory. Unfortunatelly, there's no way for us to tell R to trigger a simpler GC. You might have some success tuning this parameters, and maybe we should consider a diffferent set of pars. The problem is that R is not aware of how much memory each tensor uses, so it will not trigger GC when it should. We could fix this, but it would a non-trivial amount of work, by tracking all tensors that are sent to R at some point and and making sure we can delete them imediately when they go out of scope, even if R still didn't garbage collect the the R object itself, we might be able to free up the gpu memory. |
Thanks, I will look into this! |
|
this is maybe a naive idea, but could torch not do its own bookkeeping for the tensors and only garbage collect this list of tensors instead of all R objects? maybe one could use the refcounts for that https://developer.r-project.org/Refcnt.html |
|
I'm not sure I completely follow the suggestion. Would we instead of call GC, walk trough the objects list looking for tensors and remove those that have a 0 refcount? I'm not sure how to this, but we probably can somehow? Another idea that might work is to somehow show the R allocator how much memory tensors are using, so R would call GC at the expected locations more often, and we wouldn't need to force that. I think this is possible with ALTREP objects. |
Yeah that would be my idea. It is also possible to access the refcount -- even from within R -- but I am now sure whether I understand its behavior. E.g. below, shouldn't the refcount be 1? x = torch::torch_randn(1)
.Internal(refcnt(x))
#> [1] 4Created on 2024-08-28 with reprex v2.1.1 This excerpt from the link I sent also suggest that refcounts are not always properly decremented.
Coming back to your comment:
This would still require calls to GC in situations we only want to free torch tensors and not other R objects, right? |
|
Coming back to this: I think the already available Let's say I write a simple training loop library(torch)
net = nn_sequential(
nn_linear(20, 100),
nn_relu(),
nn_linear(100, 1)
)
x = torch_randn(100, 20)
beta = torch_randn(20, 1)
y = torch_matmul(x, beta)
opt = optim_adam(net$parameters)
net_jit = jit_trace(net, x)
for (i in 1:100) {
opt$zero_grad()
y_hat = net_jit(x)
loss = nnf_mse_loss(y, y_hat)
loss$backward()
opt$step()
}In each iteration of the loop, some temporary tensors are allocated. These allocations will be freed via the finalizer of the external pointer which will only be called after garbage collection, which is slow and we would like to avoid it. In the for-loop, we have the following temporary tensors allocations in each iteration:
In order to avoid having to call into the R gc, we would therefore have to:
What do you think about these suggestions? |
|
When I compare the jitted r torch code (https://github.com/sebffischer/torch-profiling/blob/master/2024-09-06/rtorch.R) with the equivalent pytorch code, the R torch code runs around a factor of 3x slower than the python version. Still, 2.6 out of the roughly 5.6 seconds that the R code runs are still due to the GC. Below I attached an image of the profile, but the whole file can also be found here in case you are interested. Interestingly, the gc seems to be called during the (jitted) forward call of the network. 
|
|
I like your suggestions, let's see how much we can improve with |
|
Hey @dfalbel, I haven't yet tried out those functions, mostly because I am unable to install the dev version of the package (once a new release is made I can explore it it). I have another idea that I would like to explore: While torch shines partly because it is so flexible, I think a lot of use-cases are also covered by a standard training loop and a standard optimizer. Would it be possible to implement such a standard training loop in C++?
If you would be interested in pursuing this I would love to contribute. I have already found https://github.com/mlverse/lltm for a start, but I can't quite get it running. Further, I don't have a lot of experience in C++ and the whole build is non trivial as you mention yourself. Let me know whether you think this might be a promising path to explore. |
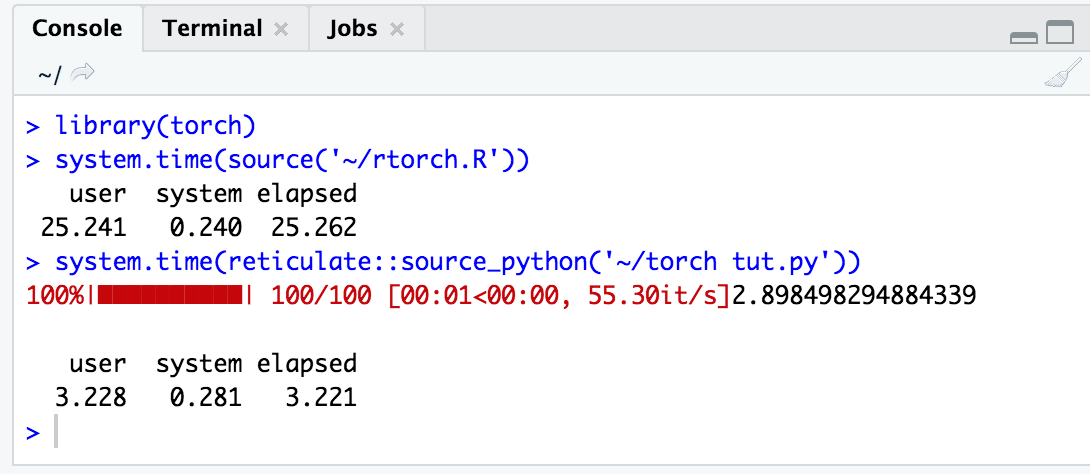
With trivial example of approximating trigonometric function (sin) in python :
and the same implementation in R :
the deference in time is observable , don't know why !!!
The text was updated successfully, but these errors were encountered: