
PaddleOCR performs the Optical Character Recognition (OCR) function from a video, an image, or a scanned document. It is mainly composed of three parts: DB text detection, detection frame correction and CRNN text recognition. For more details, refer to the PaddleOCR technical article.
This notebook demonstrates live paddleOCR inference with OpenVINO, using the "Chinese and English ultra-lightweight PP-OCRv3 model(16.2M)" from PaddleOCR Github or PaddleOCR Gitee, which includes upgraded text detector and recognizer to improve accuracy compared to its previous version, PP-OCRv2. Both text detection and recognition results are visualized in a window, and text recognition results include both recognized text and its corresponding confidence level. The notebook shows how to create the following pipeline:
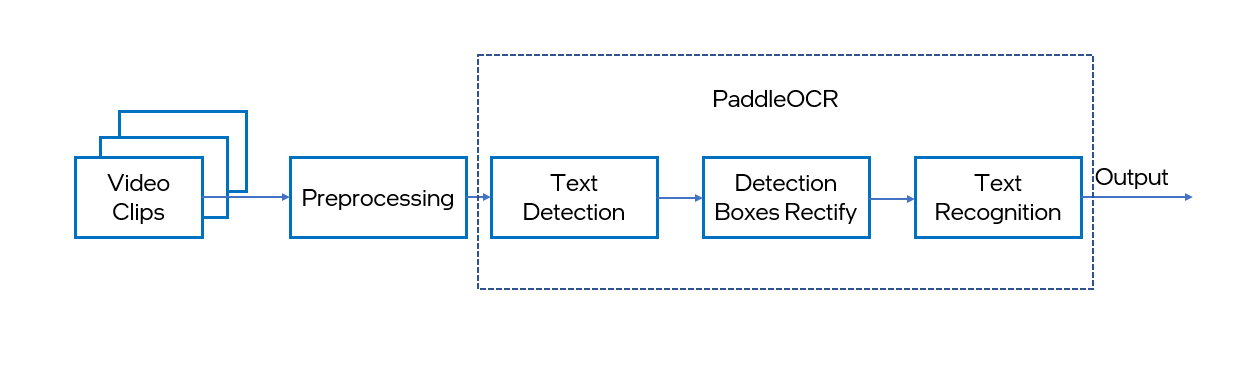
Final part of this notebook shows live inference results from a webcam. Additionally, you can also upload a video file.
NOTE: To use the webcam, you must run this Jupyter notebook on a computer with a webcam. If you run on a server, the webcam will not work. However, you can still do inference on a video in the final step.
NOTE: If you would like to use iGPU as your device to run the inference for PaddleOCR, note that the text recognition model within PaddleOCR is a deep learning model with dynamic input shape. Since our current release of OpenVINO 2022.2 does not support dynamic shape on iGPU, you cannot switch inference device to "GPU" for this demo. If you still want to try running inference on iGPU for PaddleOCR, it is recommended to resize the input images, for example, the bounding box images from text detection, into a fixed size to remove the dynamic input shape effect, for which some performance loss may be expected.*
For more information about the other PaddleOCR pre-trained models, refer to the PaddleOCR Github or PaddleOCR Gitee.
If you have not installed all required dependencies, follow the Installation Guide.