generated from fastai/fast_template
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Create 2022-10-09-how-to-make-program-faster-en.md
- Loading branch information
1 parent
d811612
commit 6f700a3
Showing
1 changed file
with
310 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,310 @@ | ||
| # How to improve program performance | ||
|
|
||
| This article mainly discusses ways, methods and best practices to improve program performance. | ||
|
|
||
|
|
||
|
|
||
| ## There are three main directions | ||
|
|
||
| - Use caching where possible | ||
|
|
||
| - Use multiple cores where possible | ||
|
|
||
| - There is also a minor direction of ***minimizing memory copies***, which gives rise to the concepts of rvalue references, move constructors, and move assignments. | ||
|
|
||
| > It may seem that the above two points are “two simple sentences with no substance”, but they are indeed the main directions, and following these two main directions will lead to many optimization methods. | ||
| Along these two directions, our basic methods are layering, trade-offs, and swapping. | ||
|
|
||
| > Layering and swapping | ||
| > | ||
| > The computer field, and even a wider scope, has a principle of “you can't have your cake and eat it too”. For example, space (storage capacity, space complexity, etc.) and time (access speed, time complexity, etc.) are usually incompatible. Therefore, the methodologies of trade-offs, layering, and “swapping X for Y” are generated. | ||
|
|
||
|
|
||
| Regarding multi-core parallel computing, there is Amdahl's law (Amdahl's argument) | ||
|
|
||
|  | ||
|
|
||
|
|
||
| ## Use the cache as much as possible | ||
|
|
||
| The cache is used to compensate for the speed differences between the various levels of the storage system. | ||
|
|
||
| ### The speed difference between the CPU and the memory is huge | ||
|
|
||
| With the help of the CPU pipeline and the reduced instruction set, an instruction usually only requires one clock cycle. Memory access (if not cached) usually takes hundreds of clock cycles. The difference is hundreds of times. Intuitively, it is also easy to understand. The memory sticks are far away from the CPU on the motherboard, and their data buses are visible to the naked eye. The CPU chip, on the other hand, is a very small piece, and its internal transistors are at the nanometer level. | ||
|
|
||
| #### Throughput and latency | ||
| > | ||
| > The speed mentioned here refers to latency rather than throughput. If you only look at throughput, memory access is not slow because it is a batch read. If you look at latency, memory access is very slow because you have to wait hundreds of clock cycles. A metaphor for the difference between throughput and latency is that it is like pulling a truckload of ice cream from a refrigerated warehouse several kilometers away to your home. You have to wait a long time, but the amount is large. | ||
| ### Cache within the chip | ||
|
|
||
| The cache is built into the chip and is divided into levels L1, L2, and L3. L_(N) indicates the cache at each level, with N being the smaller the capacity and the faster the access speed, and N being the larger the capacity and the slower the access speed. The L1 cache can achieve register-level access speeds (i.e., read and write only require one clock cycle). | ||
|
|
||
|
|
||
|
|
||
| ### The computer storage system in the form of a pyramid | ||
|
|
||
| The computer storage system adopts a hierarchical and compromise approach, and the following diagram shows the computer storage system in the form of a pyramid. The higher up you go, the less capacity and the faster the access speed; the lower you go, the more capacity and the slower the access speed. The difference in capacity and speed between different layers is x10 or x100. Data is transferred from external storage to memory, from memory to cache, from cache to registers, and then processed by the processor. | ||
|
|
||
| In a multi-core CPU, each core has its own L1 and L2 caches, while the L3 cache and below are shared by the cores. | ||
|
|
||
| 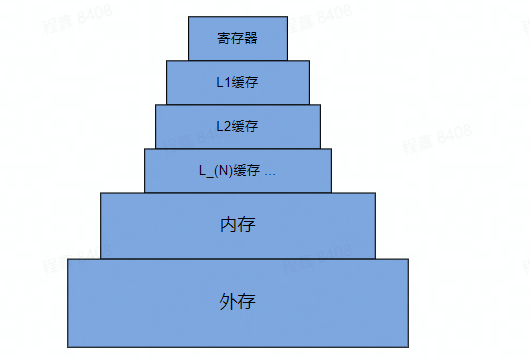 | ||
|
|
||
| Thanks to the cache, accesses by the CPU to memory change from direct to indirect. | ||
|
|
||
| ```Shell | ||
| CPU <-> memory | ||
| becomes | ||
| CPU <-> cache <-> memory | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| ### How cache works | ||
|
|
||
| #### Locality principle | ||
|
|
||
| How cache works | ||
|
|
||
| #### Cache Line | ||
|
|
||
| A `cache line` usually has 32/64/128 bytes, corresponding to a region in memory (there are various mapping methods, such as direct mapping). | ||
|
|
||
| When reading from memory, the first thing to check is whether the memory to be read is in a cache line in the cache. If so, the cache is accessed; otherwise, the data is loaded from memory and placed in a cache line in the cache. When writing to memory, the first thing to check is whether the memory to be written is in a cache line in the cache. If so, the cache is written to; otherwise, the data is loaded from memory and placed in a cache line in the cache. | ||
|
|
||
| Writing to this memory area, even just one byte, will invalidate the entire cache line. | ||
|
|
||
| #### Hit ratio | ||
|
|
||
| If the data in the memory to be accessed is already in the cache, it is a “hit”; otherwise it is a cache miss. | ||
|
|
||
| ``` | ||
| Hit ratio = number of hits / total number of accesses | ||
| ``` | ||
|
|
||
| A high hit ratio has a significant impact on performance. For example, a hit ratio of 95% (5% misses) is likely to be twice as fast as a hit ratio of 90% (10% misses). This is because the time spent on misses is the main component, and the difference between a 5% miss rate and a 10% miss rate is doubled. | ||
|
|
||
| ### Improving the hit ratio | ||
|
|
||
| Using the cache as much as possible is to maximise the cache hit ratio. The following methods can all improve the hit ratio (but note that some methods can actually harm performance in a multi-core environment): | ||
|
|
||
| 1. Improve spatial locality | ||
| 1. Preferentially use sequential storage data structures, such as PODArray and hash maps with sequential tables as the underlying layer; | ||
| 2. Replace random access with sequential scanning. | ||
| 2. Improve temporal locality | ||
| 1. Keep the declaration and use of variables as close as possible. | ||
| 3. Avoid cache line invalidation. | ||
|
|
||
|
|
||
|
|
||
| ## Use multiple cores whenever possible | ||
|
|
||
| The transistor count of current CPU chips still follows Moore's Law, while the single-core clock speed and computing power of CPUs have not developed much (due to physical limitations), and the number of CPU cores is growing. Therefore, it is important to take advantage of multiple cores. | ||
|
|
||
| 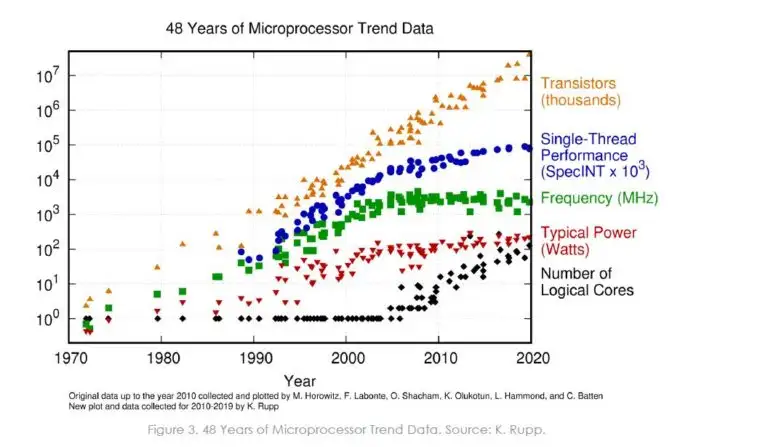 | ||
|
|
||
| ### Reduce the impact between multiple threads | ||
|
|
||
| The key to using multiple cores is to minimize the interference between multiple threads, including but not limited to locks and caches. | ||
|
|
||
| Take a distributed counter as an example. | ||
|
|
||
|
|
||
|
|
||
| #### Read and write locks | ||
|
|
||
| Use `std::shared_mutex` to implement read and write locks. The code is as follows: | ||
|
|
||
| ```cpp | ||
| class DistributedCounter { | ||
| public: | ||
| typedef long long value_type; | ||
| static std::string name() { return "lockedcounter"; }; | ||
|
|
||
| private: | ||
| value_type count; | ||
| std::shared_mutex mutable mtx; | ||
| public: | ||
| DistributedCounter() : count(0) {} | ||
|
|
||
| void operator++() { std::unique_lock<std::shared_mutex> lock(mtx); ++count; } | ||
| value_type get() const { std::shared_lock<std::shared_mutex> lock(mtx); return count; } | ||
| ``` | ||
| Multiple threads have only one lock, so there is a lot of interference between threads and a significant loss of efficiency. | ||
| #### Bucket-read-write lock | ||
| First, multiple buckets are set up, each with a counter and a read-write lock. The hash function is used to distribute the data to a bucket, and then the lock is used on that bucket. | ||
| ```cpp | ||
| class DistributedCounter | ||
| { | ||
| typedef size_t value_type; | ||
| struct bucket | ||
| { | ||
| std::shared_mutex sm; | ||
| value_type count; | ||
| }; | ||
| static size_t const buckets{ 128 }; | ||
| std::vector<bucket>counts{ buckets }; | ||
| public: | ||
| static std::string name() { return"lockedarray"; } | ||
| void operator++() { | ||
| size_t index = std::hash<std::thread::id>()(std::this_thread::get_id()) % buckets; | ||
| std::unique_lock<std::shared_mutex> ul(counts[index].sm); counts[index].count++; | ||
| } | ||
| value_type get() { return std::accumulate(counts.begin(), counts.end(), (value_type)0, [](auto acc, auto& x) { std::shared_lock<std::shared_mutex> sl(x.sm); return acc + x.count; }); } | ||
| }; | ||
| ``` | ||
|
|
||
| Due to the hash function, memory accesses by multiple threads are scattered across different buckets, so interference between threads is much smaller. However, interference between threads regarding caches is relatively large. | ||
|
|
||
|
|
||
|
|
||
| #### Bucket-exclusive cacheline-read-write lock | ||
|
|
||
| Since a cache line has 32/64/128 bytes, the previous method will cause multiple buckets to be loaded into a cache line, and even a modification of one byte in the cache line will cause the cache line to be in a “modified” state, causing the cache line for the same memory location on other CPU cores to become invalid. | ||
|
|
||
| Suppose that b1, b2, b3, and b4 can be loaded into a cache line, and there are four threads t1, t2, t3, and t4 in the four CPU cores c1, c2, c3, and c4. T1, t2, t3, and t4 access b1, b2, b3, and b4. Then there will be a cache line in the L1 cache of each of the four CPU cores that caches b1, b2, b3, and b4. When thread t1 modifies b1, although it does not modify b2, b3, or b4, it causes the cache lines of the other three cores to become invalid. If t2 tries to access b2 at this time, it can obviously get the value from its own cache, but it has to reload the data from memory with the logic of cache missing. | ||
|
|
||
| In order to let each bucket occupy an exclusive cache line, padding is added to “spread out” the memory occupied by the bucket. The code is as follows: | ||
|
|
||
| ```cpp | ||
| class DistributedCounter | ||
| { | ||
| typedef size_t value_type; | ||
| struct bucket | ||
| { | ||
| std::shared_mutex sm; | ||
| value_type count; | ||
| char padding[128]; // “撑开”内存,独占一个cache line。 | ||
| }; | ||
|
|
||
| static size_t const buckets{ 128 }; | ||
| std::vector<bucket>counts{ buckets }; | ||
| public: | ||
| static std::string name() { return"lockedarray"; } | ||
|
|
||
| void operator++() { | ||
| size_t index = std::hash<std::thread::id>()(std::this_thread::get_id()) % buckets; | ||
| std::unique_lock<std::shared_mutex> ul(counts[index].sm); counts[index].count++; | ||
| } | ||
| value_type get() { return std::accumulate(counts.begin(), counts.end(), (value_type)0, [](auto acc, auto& x) { std::shared_lock<std::shared_mutex> sl(x.sm); return acc + x.count; }); } | ||
| }; | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| #### Bucket-exclusive cacheline-atomic variable | ||
|
|
||
| Atomic variables are generally lighter than locks because they can be compiled into special CPU machine instructions, such as `LOCK ADD X, Y`, `XCHG`, etc. The code is as follows: | ||
|
|
||
| ```cpp | ||
| class DistributedCounter | ||
| { | ||
| typedef size_t value_type; | ||
| struct bucket | ||
| { | ||
| std::shared_mutex sm; | ||
| std::atomic<value_type> count; | ||
| char padding[128]; // “撑开”内存,独占一个cache line。 | ||
| }; | ||
|
|
||
| static size_t const buckets{ 128 }; | ||
| std::vector<bucket>counts{ buckets }; | ||
| public: | ||
| static std::string name() { return"lockedarray"; } | ||
|
|
||
| void operator++() { | ||
| size_t index = std::hash<std::thread::id>()(std::this_thread::get_id()) % buckets; | ||
| counts[index].count++; | ||
| } | ||
| value_type get() { return std::accumulate(counts.begin(), counts.end(), (value_type)0, [](auto acc, auto& x) { return acc + x.count.load(); }); } | ||
| }; | ||
| ``` | ||
|
|
||
| The memory order can be specified when accessing atomic variables. The default is the *sequential consistency* memory order, which is theoretically the slowest but ensures that the result is always correct. In this example, the fastest but least strict *relaxed* memory order can be used. I won't go into detail here. | ||
|
|
||
| The following are the test results of the above four methods on a 128-core server: | ||
|
|
||
| 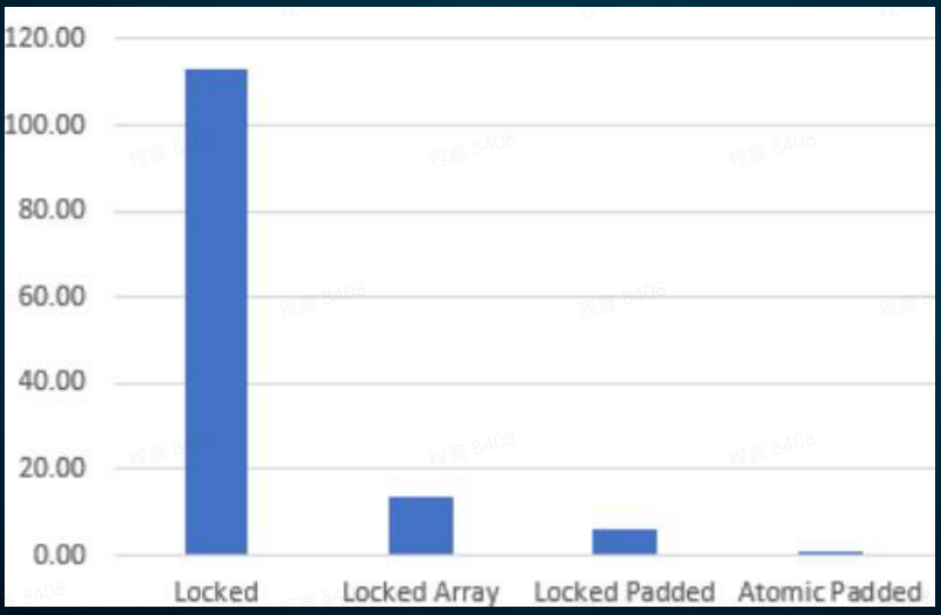 | ||
|
|
||
| It can be seen that the performance difference is very large. | ||
|
|
||
| #### Other methods | ||
|
|
||
| Other methods include lock-free programming, spin locks, pthread read and write locks, and futex in the Linux system. | ||
|
|
||
| Lock-free programming is theoretically the best, as there is almost no interference between threads. | ||
|
|
||
|
|
||
|
|
||
| ### The performance of multi-core must be tested on multi-core machines | ||
|
|
||
| Multi-core related optimizations may not be able to highlight the benefits in terms of performance on machines with a small number of cores, and the performance improvement can only be highlighted on machines with a large number of cores. | ||
|
|
||
| Similarly, performance optimizations for multi-core and caches should be based on the characteristics of the actual machine running. | ||
|
|
||
|
|
||
|
|
||
| ### Single-core pipeline | ||
|
|
||
| Ensure that the execution pipeline of each CPU core is fully utilized. In addition to the above cache optimization (cache misses will disrupt the pipeline), the following list some methods that will also help improve the utilization of the execution pipeline. | ||
|
|
||
| 1. Use `[likely]` and `[unlikely]` to help branch decisions; | ||
| 2. Use const T & as much as possible to help the compiler optimize; | ||
| 3. Add the __restrict keyword to help the compiler optimize; | ||
| 4. Use rvalues in rvalue situations to reduce memory copying; | ||
| 5. Select an appropriate memory order to ensure that the instruction ordering is as unrestricted as possible under the premise of correctness. Instruction ordering can improve pipeline utilization. | ||
|
|
||
|
|
||
|
|
||
| ## Summary of best practices | ||
|
|
||
| 1. Try to avoid placing objects or variables that each thread accesses independently on the same cache line; | ||
| 2. Try not to place read-only memory and frequently written memory together to avoid being placed on the same cache line; | ||
| 3. Divide the parts shared by multiple threads into threads-only segments (buckets) as much as possible; | ||
| 4. Try to avoid frequent write memory areas from affecting other memory reads and writes, i.e., let the area exclusively occupy the cache line; | ||
| 5. Place together as many variables or collections of objects that are accessed at the same time as possible; | ||
| 6. Use tools such as VTune to find bottlenecks in the cache. | ||
|
|
||
| New features of cpp17: | ||
|
|
||
| - std::hardware_destructive_interference_size | ||
| If the memory address distance between two objects is ***greater than*** std::hardware_destructive_interference_size, they will not be in the same cache line. | ||
|
|
||
| - std::hardware_constructive_interference_size | ||
| If the memory address of two objects is ***less than*** std::hardware_destructive_interference_size, they will be in the same cache line. | ||
|
|
||
|
|
||
|
|
||
| ## Constantly solving problems and creating new ones | ||
|
|
||
| It is a law of nature that as old problems are solved, new ones emerged. | ||
|
|
||
| Since the frequency of CPUs cannot be increased effectively due to physical laws, multi-core CPUs have been developed, i.e. a CPU chip contains multiple “small CPUs”, which we call CPU cores. | ||
|
|
||
| > It was subsequently discovered that memory access was the bottleneck, because not only was memory access slow, but it could not be accessed by multiple cores simultaneously. To solve this problem, in-core caches were introduced, allowing each CPU core to obtain the data required for the operation in parallel. | ||
| > | ||
| > But this in turn created a new problem: how to synchronize the cached data in multiple CPU cores (the data in the same memory may be cached in multiple CPU cores). | ||
| > | ||
| > To solve this problem, the MESI protocol was introduced. In order to minimize the “drag” on the CPU when implementing the MESI protocol (i.e., to allow the CPU core to not wait for synchronization to complete), the concepts of a store buffer and an invalidate queue were introduced. | ||
| > | ||
| > In addition, to ensure the effectiveness of the CPU execution pipeline, the compiler and CPU may rearrange the order of instruction execution. | ||
| > | ||
| > However, these optimizations may cause the program execution result to become incorrect. Therefore, in order to ensure both correctness and parallelism, the concept of memory order was introduced... | ||
| ## References | ||
|
|
||
| 1. https://semiwiki.com/ip/312695-white-paper-scaling-is-falling/ | ||
| 2. https://courses.cs.washington.edu/courses/cse378/09wi/lectures/lec15.pdf | ||
| 3. https://en.cppreference.com/w/cpp/thread/hardware_destructive_interference_size | ||
| 4. https://courses.cs.washington.edu/courses/cse378/09wi/lectures/lec15.pdf |