{kind=link}
![]()
tcapy is a Python library for doing transaction cost analysis (TCA), essentially finding the cost of your trading activity. Across the industry many financial firms and corporates trading within financial markets spend a lot of money on TCA, either by developing in house tools or using external services. It is estimated that the typical buy side equities trading desk spends around 225k USD a year on TCA (see MarketsMedia report). Many sell side firms and larger buy side firms build and maintain their own TCA libraries, which is very expensive. The cost of TCA across the industry is likely to run into many hundreds of millions of dollars or possibly billions of dollars.
Much of the complexity in TCA is due to the need to handle large tick datasets and do calculations on them and is largely a software engineering problem. This work needs to be repeated in every single implementation. By open sourcing the library we hope that the industry will no longer need to keep reinventing the wheel when it comes to TCA. At the same time, because all the code is visible to users, tcapy allows you can add your own customized metrics and benchmarks, which is where you are likely have very particular IP in financial markets. You get the flexibility of a fully internal TCA solution for free.
tcapy is one of the first open source libraries for TCA. You can run the library on your own hardware, so your trade/order data can be kept private. It has been in development since June 2017, originally for a large asset manager and was open sourced in March 2020.
We've made tcapy to be vendor independent, hence for example it supports:
- multiple database types for storing market tick data (including Arctic/MongoDB, KDB and InfluxDB) and for trade/order data (including MySQL, PostgreSQL and Microsoft SQL Server).
- Linux (tested on Ubuntu/Red Hat) - also it also works on Windows (need Windows Subsystem for Linux to make all features accessible)
tcapy has also been written to distribute the computation and make a lot of use of caching. In the future, we are hoping to add features to make it easy to use serverless computing features on the cloud. Since you can see all the code, it also makes the TCA totally transparent. If you are doing TCA for regulatory reasons, it makes sense that the process should be fully open, rather than a black box. Having an open source library, makes it easier to make changes and fitting it to your use case.
We have a video demo on YouTube of how to use tcapy via its web GUI, Excel or calling it programatically from a Jupyter notebook.
At its very simplest TCA can involve working out the spread (slippage) you paid. It is also important to understand metrics such as market impact. Trading firms need to do TCA for a variety of reasons:
- regulations such as MiFID II which stipulate that buy side firms need to show best execution
- to reduce the cost of trading, by analysing your LP (liquidity providers), execution styles etc. and hence increase alpha
tcapy has been in development for several years and currently supports FX spot based trade/order data. In the future, we are also planning adding other asset classes. It has several FX specific features that include:
- conversion of trade/order data booked in wrong convention eg. USDGBP is converted to GBPUSD
- ability to generate synthetic cross rates from benchmark data for exotic crosses if underlying data doesn't exist
We assume that an order has a start and end time, and hence a duration. It will have fields associated with it such as the ticker traded, the execution price, the account, the execution trader, the broker, the algo used etc.
Underneath every order, there might be a number of trades and other events. The difference is that we assume these trade events, are points in time. These trades will tag their respective orders.
tcapy can calculate and fill in fields of an order, such as executed notional, executed price based upon it the underlying trade fills. In the literature, the terminology can sometimes differ for the names of orders and trades. tcapy can also work purely at a trade level, as well on both trades and orders.
tcapy expects your orders in a specific format with specific field names, which can viewed under the test/resources folder:
small_test_order_df.csvfor the format of the orderssmall_test_trade_df.csvfor the format of the trades
tcapy performs TCA. Essentially, it takes as an input your own trade/order data and market tick data. It will merge the market tick data with your trade/order data, to calculate benchmarks (such as the mid or arrival price of a trade/order, or TWAP/VWAP during an order). The market tick data input should be representative of the market. At present we have developed adapters to download data from Dukascopy (free) and New Change FX (paid). We'd also like to add adapters to download different data sources.
Importantly, you can use whatever market tick data source you'd like, if its already stored in your market tick database. Very often you might wish to switch the data source you use for your benchmark.
Based on the benchmark you choose, it computes various metrics on your trade/order data such as:
- slippage - the difference between your benchmark and the executed price
- market impact - the price move following a trade/order
It can then provide statistics based on the metrics such as
- average
- outlier
You can provide your trade/order and market tick data in different ways:
- CSV files for trade/order/market data
- DataFrames for trade/order/market data
- MongoDB/Arctic, KDB or InfluxDB for market data
- MySQL, PostgreSQL or MySQL for trade/order data
Obviously, if you choose to use the database options, you'll have to maintain these databases. If you database of choice is not supported it is possible to write an adapter for it.
There are four ways to use tcapy, which are:
- Via web GUI, built with Dash (including one where you can drop & drop trade CSVs)
- Programmatically
- Via command prompt/IDE etc.
- Via Jupyter notebook to do interactive research studies
- Via Excel spreadsheet via xlwings (see example spreadsheet here)
- Via RESTful API (very basic functionality at present)
Below we have a montage illustrating some of the ways you can interact with tcapy out-of-the-box!

Given we can call tcapy programmatically, if you are doing a more customized sort of TCA research project, it is ideal to use Jupyter notebooks to mix code and results in one place.
Sometimes GitHub might not render the Jupyter notebooks, in which case you can use the nbviewer link. You can also run all the Jupyter notebooks interactively in Binder. Note, for those examples which use databases/multithreading, they will not function fully in Binder. However, all other examples, which don't rely on databases/multithreading do work.
It can also take a long time for Binder to load, as in many instances it will need to build the Docker. Also there will be times when the compute on Binder is limited, in which case, you might need to try again later to use it.
Also see here, which lists all the notebooks
- A 10 minute view of tcapy - quick guide to doing simple TCA calculcations in Python with tcapy (nbviewer or run on Binder)
We also have many more detailed notebooks:
- Introducing tcapy and explaining TCA - how to use tcapy in more detail and gives many examples of how to call it programmatically (nbviewer or run on Binder)
- Compliance and other more involved TCA calculations - how to do TCA calculations for compliance and other more involved use cases (nbviewer or run on Binder)
- Populating databases for tcapy - how to populate your trade/order (MySQL/SQLite/Microsoft SQL Server) and market data databases (Arctic/MongoDB/PyStore) (nbviewer or run on Binder)
- Excel/xlwings with tcapy - how to run tcapy from Excel with xlwings, with a demo spreadsheet (nbviewer or run on Binder)
- Additional benchmark and metrics for tcapy - we go through some of the benchmarks and metrics available in tcapy in more detail (nbviewer or run on Binder)
- Real life tcapy case study on an asset manager's trade data - we do a real life TCA case study on the FX trade data of a Swedish asset manager (nbviewer or run on Binder)
- Market microstructure with tcapy - generating results for spreads and volatility using tick data (nbviewer or run on Binder)
A few things to note:
- Please bear in mind at present tcapy is currently an alpha project
- tcapy is only partially documented, although we are working on adding more documentation, in particular more Jupyter notebooks
- Uses Apache 2.0 licence see here
Detailed installation instructions can be found here
There is now Dockerized version of tcapy, which makes it much easier to install tcapy and all its dependencies.
You can also install it with pip if you want to use different parts of tcapy as dependencies in your own Python project.
tcapy is written in Python and makes extensive use of many Python libraries such as Pandas. It also utilises external dependencies such as Redis for caching, and can use numerous databases as mentioned earlier. To distribute and speed up computation it uses Celery. Hence if we ask for TCA to be performed on multiple tickers, a different Celery worker will pick up the task from the message broker (Redis) and will return the final results to the results backend (Memcached).
There is also extensive caching of trade and market data used internally with Redis, so it doesn't repeatedly hit the database, which can be slow particularly if you are using over a network with a lot of latency.
Contributors are always welcome for tcapy. If you'd like to contribute, have a look at planned features for areas we're looking for help on. If you have any ideas for improvements to the libraries please let us know too.
Project contributors
- Saeed Amen (@saeedamen) - lead developer
- Thomas Schmelzer (@tschm) - thanks to Thomas for reviewing some of the code and in particular his help to begin the process of creating a Docker image
Below we show screenshots of the web GUI for tcapy.
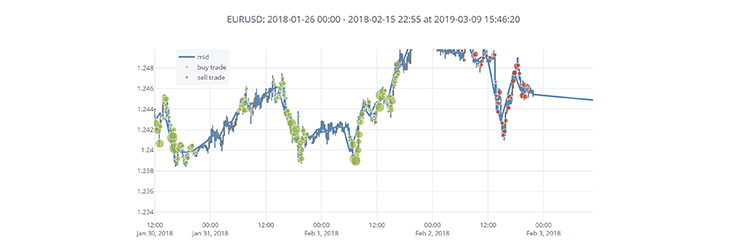
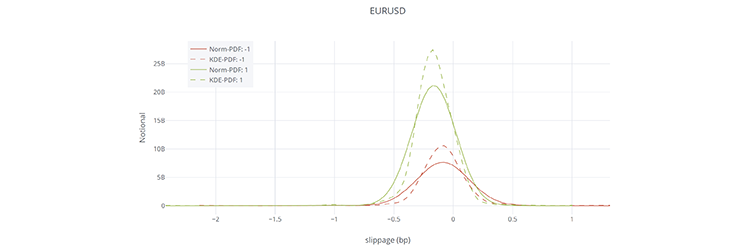

See installation guide for details on requirements.
For detailed installation instructions for tcapy and its associated Python libraries go to the installation guide.
In tcapy/tcapy_examples you will find several example scripts to demonstrate how to run tcapy, as well as in the introductory Jupyter notebook
We'll of course try to answer your queries if you raise an issue on GitHub.
If you are interested in getting commercial support for tcapy or would like to sponsor the addition of new features for tcapy, please contact [email protected] - we've got lots of ideas for ways to improve tcapy, but need support to implement them.
If you're a financial firm, and are keen to make TCA transparent, and would like to sponsor the project, let us know.
A change log is available here