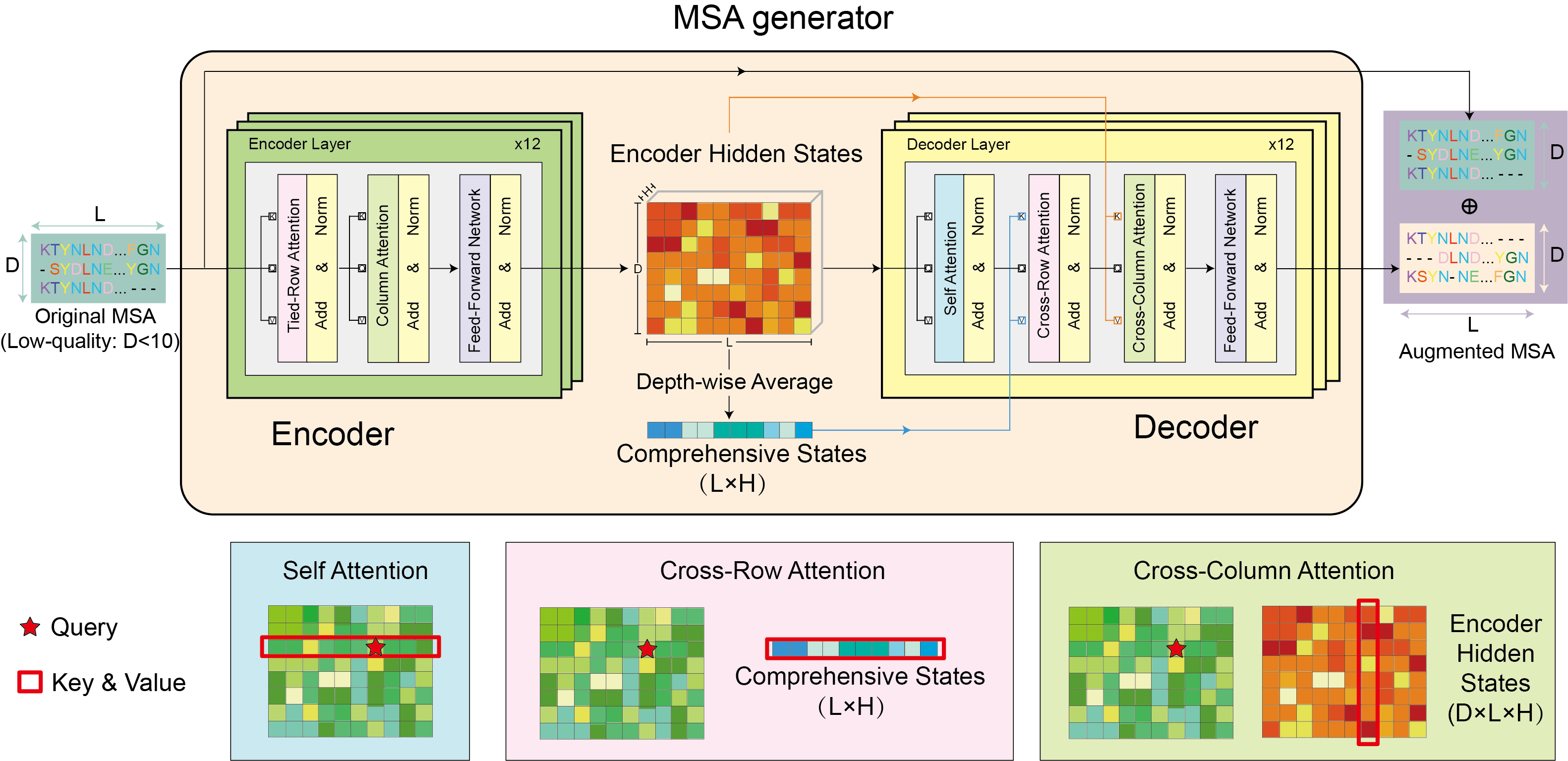
codebase for paper Enhancing the Protein Tertiary Structure Prediction by Multiple Sequence Alignment Generation arxiv
All the commands are designed for slurm cluster, we use huggingface trainer to pretrain the model, more details could be find here
-
Construct local binary dataset ( load training data from cluster is too slow, so it's better to fisrt construct all your dataset to .bin file as shown in datasets )
python utils.py \ --output_dir ./datasets/ \ --random_src --src_seq_per_msa_l 5\ --src_seq_per_msa_u 10 \ --total_seq_per_msa 25 \ --local_file_path path_to_pretrained_dataset -
install dependency libraries
pip install -r requirements.txt -
bash run.sh
- download checkpoints
- run inference by
bash scripts/inference.sh
Note: all inference code is in inference.py
| DATASET | MSA | STRUCTURE |
|---|---|---|
| CASP15 | https://zenodo.org/record/8126538 | google drive |
-
Please refer to Alphafold2 GitHub to learn more about set up af2.
-
We provide scripts to use alphafold2 to launch protein structure prediction by
bash scripts/run_af2, one need to modifymsa directory
- follow this document for lddt evaluation tool download https://www.openstructure.org/
- follow this document for https://www.openstructure.org/docs/2.4/mol/alg/lddt/ usage
Directly run following to get .json file of final results.
python ensemble.py --predicted_pdb_root_dir ./af2/casp15/orphan/A1T3R1.5/
@misc{zhang2023enhancing,
title={Enhancing the Protein Tertiary Structure Prediction by Multiple Sequence Alignment Generation},
author={Le Zhang and Jiayang Chen and Tao Shen and Yu Li and Siqi Sun},
year={2023},
eprint={2306.01824},
archivePrefix={arXiv},
primaryClass={q-bio.QM}
}please let us know if you have further questions or comments, reach out to [[email protected]](