https://leetcode.com/study-plan/sql/
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/big-countries/?envType=study-plan&id=sql-i
- pretty straightforward question
- Need to add required columns and add 2 conditions in the where clause and done!
SELECT name, population, area
FROM World WHERE area >= 3000000 OR population >= 25000000;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/recyclable-and-low-fat-products/?envType=study-plan&id=sql-i
- need to have 2 conditions in where clause:
- 1. low fats -> yes
- 2. recyclable -> yes
- simply need to select that particular option from enum of values
SELECT product_id FROM Products
WHERE (low_fats = 'Y' and recyclable = 'Y')↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/find-customer-referee/?envType=study-plan&id=sql-i
- pretty straightforward question
- need to have 2 conditions in where clause:
- 1. not referred by customer with id 2 ie., id != 2
- 2. null values accepted
SELECT name FROM Customer
WHERE referee_id is NULL or referee_id != 2;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/customers-who-never-order/description/?envType=study-plan&id=sql-i
- there are 2 methods:
- 1. Using Sub Queries
- 2. Using Join:
* refer join visualization in case you don't understand Joins: https://joins.spathon.com/
* We perform join because they have common column which is referring to Customer ID
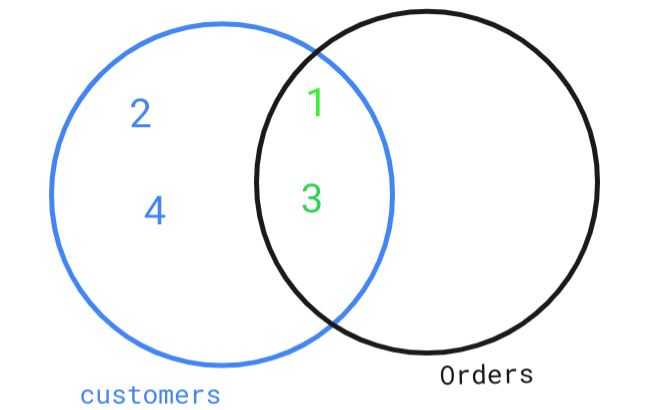
* refer the above given link and then see this diagram for this example:
Customers table:
+----+-------+
| id | name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Orders table:
+----+------------+
| id | customerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
* According to the diagram we want 2, 4 and we can get it by left join
SELECT name as Customers from Customers
WHERE id NOT IN(SELECT customerId from Orders)SELECT name as Customers
FROM Customers C
LEFT JOIN Orders O
ON C.id = O.customerId
WHERE O.id is NULL;- For Lesser values, both Joins and sub queries method might perform the same way
- But for Larger amount of values, Joins are preferrable over Nested/Sub Queries
- https://www.geeksforgeeks.org/sql-join-vs-subquery/, You can refer this for detailed comparison between Joins vs Sub-Queries
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/calculate-special-bonus/?envType=study-plan&id=sql-i
- to check whether the name starts with M is by using wildcard character: 'M%'
- syntax for simple IF statement: if(expression, true, false)
- we are applying condition on salary column
- we want the name of salary column to be changed to bonus
SELECT employee_id,
if(employee_id % 2 != 0 and name NOT LIKE 'M%', salary, 0) as bonus
from Employees order by employee_id;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/swap-salary/?envType=study-plan&id=sql-i
- pretty straightforward question
- use of if statement to swap the values, and updating accordingly
UPDATE Salary
SET sex = IF(sex = 'm', 'f', 'm');↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/delete-duplicate-emails/?envType=study-plan&id=sql-i
- there are 2 methods in cartesian product/cross join and normal join
- in this case both of them would ideally give similar performance
- but in case of dissimilar tables normal join is always preferred over cross join
- as it would create a lot more rows ie., m*n rows are generated
DELETE p1 FROM Person p1, Person p2
WHERE p1.email = p2.email AND
p1.id > p2.idDELETE p1 from Person p1
JOIN Person p2
ON P1.email = p2.email p
WHERE p1.id > p2.id;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/fix-names-in-a-table/discussion/?envType=study-plan&id=sql-i
- concatenate the upper and lower string
- UPPER function which chapitalizes
- we have substring which takes 3 arguments, the first is the string itself, the second is the starting index from which it should start capitalizing and the 3rd argument is the ending index till which it should capitalize.
- similarly the LOWER function
SELECT user_id, concat(
UPPER(SUBSTRING(name, 1, 1)),
LOWER(SUBSTRING(name, 2, LENGTH(name))))
as name from Users order by user_id↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/group-sold-products-by-the-date/description/
-we want 3 columns, sell_date, count of number of products sold on that date and values of products
- SELECT sell_date, COUNT(DISTINCT product) as num_sold : using aggregate function "ount"
- now for representing products and concat them, "group_concat"is used
SELECT sell_date, COUNT(DISTINCT product) as num_sold,
group_concat(DISTINCT product) as products
FROM Activities
GROUP BY(sell_date)
ORDER BY sell_date;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/patients-with-a-condition/?envType=study-plan&id=sql-i
- there are 2 conditions:
1. DIAB1 is present at the very first position, then inserting wild character at the end would work:
- 'DIAB1%'
2. DIAB1 is present at other positions, then inserting a space followed by DIAB1 and any characters would work:
- '% DIAB1%'
SELECT * FROM Patients
WHERE conditions like '% DIAB1%'
or conditions like 'DIAB1%'↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/employees-with-missing-information/?envType=study-plan&id=sql-i
- 2 methods: using sub-queries and using join
- suppose we consider Employee table and Salaries table, then our ans is E - S
- this can be achieved by using union
SELECT employee_id FROM Employees
WHERE employee_id NOT IN(select employee_id from Salaries)
UNION
SELECT employee_id FROM Salaries
WHERE employee_id NOT IN(select employee_id from Employees)
ORDER BY employee_idSelect e.employee_id from Employees e
LEFT JOIN Salaries s
ON e.employee_id = s.employee_id
WHERE s.salary is NULL
UNION
Select s.employee_id from Salaries s
LEFT JOIN Employees e
ON e.employee_id = s.employee_id
WHERE e.name is NULL
ORDER BY employee_id;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/rearrange-products-table/description/?envType=study-plan&id=sql-i
- here, we want all the entries individually as of store1, store2 and store3 so
basically we want union of all 3
- we want the second column to be the string representing store number
- and third column as the price at respective store
select product_id, 'store1' as store, store1 as price
from Products
where store1 is not null
union
select product_id, 'store2' as store, store2 as price
from Products
where store2 is not null
union
select product_id, 'store3' as store, store3 as price
from Products
where store3 is not null
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/tree-node/solutions/?envType=study-plan&id=sql-i&orderBy=most_votes
- for a node to be the root, parent_id is null
- for a node to be the leaf, it wont be a parent
ie., it wont be present in parent_id column
- for a node to be the inner node, it has to be present in the parent_id column
select id, 'Root' as type
from Tree
where p_id is null
union
select id,'Inner' as type
from Tree
where p_id is not null and id in(select p_id from Tree where p_id is not null)
union
select id, 'Leaf' as type
from Tree
where p_id is not null and id not in(select p_id from Tree where p_id is not null)select id,
(
case
when p_id is null then 'Root'
when id in (select p_id from tree) then 'Inner'
else 'Leaf'
end
) as type
from tree;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/second-highest-salary/?envType=study-plan&id=sql-i
- we select the max salary from Employee and then we exclude that record
and find maximum from erst of the records
select MAX(salary) as SecondHighestSalary
from Employee
where salary not in(select MAX(salary) from Employee)↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/combine-two-tables/?envType=study-plan&id=sql-i
- simple left join query
SELECT firstName, lastName, city, state
FROM Person p
LEFT JOIN Address a
ON p.personId = a.personId↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/customer-who-visited-but-did-not-make-any-transactions/description/?envType=study-plan&id=sql-i
- firstly perform LEFT JOIN and see what it returns
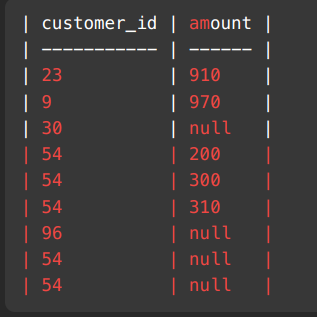
- code v1:
SELECT v.customer_id, amount
FROM Visits v
LEFT JOIN Transactions t
ON v.visit_id = t.visit_id- Result of above query for example given in problem:
- add "count" in the select statement
- count is always accompanied with group by clause!!
- When count is not accompanied by group by, it returns no. of rows in the table
- we want to group by it wrt to the customer_id, right?
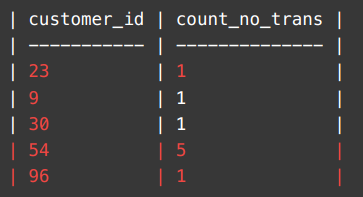
- code v2:
SELECT v.customer_id, count(customer_id) as count_no_trans
FROM Visits v
LEFT JOIN Transactions t
ON v.visit_id = t.visit_id
GROUP BY v.customer_id- result of above query:
- adding the condition "users who visited without making any transactions"
- we were counting all the entries by grouping by wrt to customer_id
- now we are adding the given condition
- see the output of code v1, you will see that we got null is some of the values
- the "null" represents that there were no values in transaction table corresponding to the visit_id in visits table
- and that is what we want!!!
remember while using WHERE, GROUP BY and ORDER BY in the same query, below is the order in which this should be used!! where group by order by
- code:
SELECT v.customer_id, count(v.customer_id) as count_no_trans
FROM Visits v
LEFT JOIN Transactions t
ON v.visit_id = t.visit_id
WHERE t.amount is NULL
GROUP BY v.customer_id SELECT v.customer_id, count(v.customer_id) as count_no_trans
FROM Visits v
LEFT JOIN Transactions t
ON v.visit_id = t.visit_id
WHERE t.amount is NULL
GROUP BY v.customer_id↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/article-views-i/?envType=study-plan&id=sql-i
- straightforward problem
SELECT DISTINCT author_id as id
FROM Views
WHERE author_id = viewer_id
ORDER BY author_id;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/rising-temperature/description/
- To compare one date with the previous date, there is no direct provision
- we can apply inner join on the recordDate such that w1.RecordDate - 1 = w2.RecordDate
- but keep this in mind that we can simply add the dates because adding 1 to 2022-12-31
wont be giving 2023-01-01, so we need to use in-built function **TO_DAYS**
SELECT w1.id as Id
FROM Weather w1
INNER JOIN Weather w2
ON TO_DAYS(w1.recordDate) - 1 = TO_DAYS(w2.recordDate)
WHERE w1.temperature > w2.temperature
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/sales-person/description/?envType=study-plan&id=sql-i
- there are 2 approaches for the same
- one of them is typical solution using multiple sub queries
- the othron using Left join
SELECT name
FROM SalesPerson
WHERE sales_id NOT IN (SELECT sales_id
FROM Orders
WHERE com_id IN(SELECT com_id
FROM Company
WHERE name = 'RED'
)
)
SELECT name
FROM SalesPerson
WHERE sales_id NOT IN (
SELECT sales_id
FROM Orders o
LEFT JOIN Company c
ON o.com_id = c.com_id
WHERE c.name = 'RED'
)
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/user-activity-for-the-past-30-days-i/
- We need to do 3 things:
1. according to activity date we need to count how many times a user appeared
on that date, basically count(user_id), grouped by activity_date
2. check the activity_date constraints where it should lie from '2019-06-28'
to '2019-07-29' ie., span of 30 days
3. update the columns names
SELECT activity_date as day,
COUNT(DISTINCT user_id) as active_users
FROM Activity
WHERE activity_date >= '2019-06-28' AND activity_date <= '2019-07-29'
GROUP BY activity_date↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/daily-leads-and-partners/
- straightforward problem
- we need to group wrt date_id and make_name both
- and need to count distinct partner and lead ids
SELECT date_id, make_name,
COUNT(DISTINCT lead_id) as unique_leads,
COUNT(DISTINCT partner_id) as unique_partners
FROM DailySales
GROUP BY date_id, make_name;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/find-followers-count/
- Easy Peasy Lemon Squeezy Problem🙃
- just group by is to be used
SELECT user_id,
COUNT(follower_id) as followers_count
FROM Followers
GROUP BY user_id
ORDER BY user_id↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/customer-placing-the-largest-number-of-orders/
- look at the image below

SELECT customer_number
FROM Orders
GROUP BY customer_number
ORDER BY COUNT(customer_number)
DESC LIMIT 1↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/game-play-analysis-i/
- straightforward problem
- using min aggregate function
SELECT player_id,
MIN(event_date) as first_login
FROM Activity
GROUP BY player_id↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/the-latest-login-in-2020/
- latest login => timestamp should be maximum
- in the year 2020 => year(timestamp) = 2020
- for each user => group by user_id
SELECT user_id,
MAX(time_stamp) as last_stamp
FROM logins
WHERE year(time_stamp) = 2020
GROUP BY user_id↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/find-total-time-spent-by-each-employee/description/
- using aggregate function SUM(), we can sum up the values
- we have used group by to group it w.r.t emp_id and event_day
SELECT event_day as day, emp_id,
SUM(out_time- in_time) as total_time
FROM Employees
GROUP BY emp_id, event_day↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/capital-gainloss/
- Problem is based on using aggregate function based on condition
- General logic is that if the stock is in 'Buy' state then the money will be deducted
and i fit is 'sell' state money will be added
- This will be grouped by the name of stocks
- so, we have added a IF condition inside SUM such that if it is 'Buy' state,
we will do -= price, else we will += price
SELECT stock_name,
SUM(IF(operation = 'Buy', -price, price)) as capital_gain_loss
FROM Stocks
GROUP BY stock_name↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/top-travellers/description/
SELECT u.name,
IFNULL(SUM(r.distance), 0) as travelled_distance
FROM users u
LEFT JOIN rides r
ON u.id = r.user_id
GROUP BY r.user_id
ORDER BY travelled_distance desc, u.name asc↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/market-analysis-i/description/
Q1: Why did we use Left Join?
- Because we wanted the orders by users ie., we want a buyer_id corresponding to the user_id
Q2: Why didnt we use WHERE for YEAR(order_date) = 2019
- Remember this: "While we want to filter the Join Product, we use the condition inside WHERE
But when the condition is part of JOIN operation, we need to put inside ON"
Q3: what will be the difference if we put "YEAR(order_date) = 2019" condition inside WHERE versus inside ON?
- When we put this condition inside WHERE condition, it will completely remove the entries with order_date in the years other than '2019'.
- But when we use it inside ON, we get NULL corresponding tho the entries where order_date is in the years other than '2019'.
This way, the entries with no values in the year 2019 wont be completely removed and we can count NULL as 0
SELECT user_id as buyer_id,
join_date,
IFNULL(COUNT(order_date), 0) as orders_in_2019
FROM Users u
LEFT JOIN Orders o
ON u.user_id = o.buyer_id
AND YEAR(order_date) = '2019'
GROUP BY u.user_id↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/duplicate-emails/description/
- strighforward problem
- we group by email and consider the email which has count > 1
SELECT Email
FROM Person
GROUP BY Email Having COUNT(email) > 1;↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/actors-and-directors-who-cooperated-at-least-three-times/
- very similar to previous problem
SELECT actor_id, director_id
FROM ActorDirector
GROUP by actor_id, director_id
HAVING COUNT(timestamp) >= 3; ↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/bank-account-summary-ii/
- applying left join on 'account'
- using the aggregate function SUM we add all the amounts from Transaction table grouping by account number
- since WHERE cannot be used with aggregate functions hence we use HAVING for the condition
SELECT name,
SUM(amount) as balance
FROM Users u
LEFT JOIN Transactions t
on u.account = t.account
GROUP BY account HAVING balance > 10000↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔
https://leetcode.com/problems/sales-analysis-iii/
- very similar to previous problem
- the only tricky part was that we need to pick up products for which all the instance of the product was sold in the given range
- so, we GROUP BY it wrt to product_id and then apply the condition using HAVING Clause
SELECT p.product_id, product_name
FROM Product p
LEFT JOIN Sales s
ON p.product_id = s.product_id
GROUP BY p.product_id
HAVING MIN(s.sale_date) >= '2019-01-01' AND MAX(s.sale_date)<='2019-03-31';↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔↔