The Banana project was forked from Kibana, and works with all kinds of time series (and non-time series) data stored in Apache Solr. It uses Kibana's powerful dashboard configuration capabilities, ports key panels to work with Solr, and provides significant additional capabilities, including new panels that leverage D3.js.
The goal is to create a rich and flexible UI, enabling users to rapidly develop end-to-end applications that leverage the power of Apache Solr. Data can be ingested into Solr through a variety of ways, including LogStash, Flume and other connectors.
![Dark Dashboard] (https://raw.githubusercontent.com/LucidWorks/banana/dev-2.0/doc/img/dashboard_dark.png)
{kind=link}
To run Banana follow these steps:
- Install Node.js
sudo apt-get install python-software-properties python g++ make
sudo add-apt-repository ppa:chris-lea/node.js
sudo apt-get update
sudo apt-get install nodejs
- In the terminal run
npm install
-
Download Solr and run it on port 8983
-
In the terminal run
npm start
- go to http://localhost:3000
Pull the repo from the "release" branch; version 1.5.0 will be tagged as v1.5.0
Banana 1.5.0 contains many new features, new panels, enhancements and bug fixes to improve the overall user experience and stability. Thank you to our growing community for your suggestions and contributions! Please continue sending us your feedbacks, so that we can further extend and improve Banana!
This release includes the following key new features and improvements:
- Multi queries support for all panels, except the scatter plot panel.
- A new Multi-series panel based on D3.js provides a way to visualize more complex datasets.
- A new Tag Cloud panel helps you to easily create a tag or word cloud from your data using facet count.
- Various bug fixes and improvements:
You can find all previous Release Notes on our wiki page.
If you created dashboards for Banana 1.0.0, you did not have a global filtering panel. In some cases, these filter values can be implicitly set to defaults that may lead to strange search results. We recommend updating your old dashboards by adding a filtering panel. A good way to do it visually is to put the filtering panel on its own row and hide it when it is not needed.
- A modern web browser. The latest version of Chrome and Firefox have been tested to work. Safari also works, except for the "Export to File" feature for saving dashboards. We recommend that you use Chrome or Firefox while building dashboards.
- A webserver.
- A browser reachable Solr server. The Solr endpoint must be open, or a proxy configured to allow access to it.
Run Solr at least once to create the webapp directories
cd $SOLR_HOME/example
java -jar start.jar
Copy banana folder to $SOLR_HOME/example/solr-webapp/webapp/
Browse to http://<solr_server>:<port_number>/solr/banana/src/index.html#/dashboard
If your Solr server/port is different from localhost:8983, edit banana/src/config.js and banana/src/app/dashboards/default.json to enter the hostname and port that you are using. Remember that banana runs within the client browser, so provide a fully qualified domain name (FQDN), because the hostname and port number you provide should be resolvable from the client machines.
If you have not created the data collections and ingested data into Solr, you will see an error message saying "Collection not found at .." You can use any connector to get data into Solr. If you want to use LogStash, please go to the Solr Output Plug-in for LogStash Page (https://github.com/LucidWorks/solrlogmanager) for code, documentation and examples.
LucidWorks has packaged Solr, LogStash (with a Solr Output Plug-in), and Banana (the Solr port of Kibana), along with example collections and dashboards in order to rapidly enable proof-of-concepts and initial development/testing. See http://www.lucidworks.com/lucidworks-silk/.
Pull the repo from the "release" branch; versions 1.3.0, 1.2.0 and 1.1.0 will be tagged as v1.3.0, v1.2.0 and v1.1.0 respectively. Run "ant" from within the banana directory to build the war file.
cd $BANANA_REPO_HOME
ant
The war file will be called banana-buildnumber.war and will be located in $BANANA_REPO_HOME/build
cp $BANANA_REPO_HOME/build/banana-buildnumber.war $SOLR_HOME/example/webapps/banana.war
cp $BANANA_REPO_HOME/jetty/banana-context.xml $SOLR_HOME/example/contexts/
Run Solr:
cd $SOLR_HOME/example/
java -jar start.jar
Browse to http://localhost:8983/banana (or the FQDN of your solr server).
Banana is an AngularJS app and can be run in any webserver that has access to Solr. You will need to enable CORS on the Solr instances that you query, or configure a proxy that makes requests to banana and Solr as same-origin. We typically recommend the latter approach.
If you want to save and load dashboards from Solr, create a collection using the configuration files provided in either the resources/banana-int-solr-4.4 (for Solr 4.4) directory or the resources/banana-int-solr-4.5 directory (for Solr 4.5 and above). If you are using Solr Cloud, you will need to upload the configuration into ZooKeeper and then create the collection using that configuration.
The Solr server configured in config.js will serve as the default node for each dashboard; you can configure each dashboard to point to a different Solr endpoint as long as your webserver and Solr put out the correct CORS headers. See the README file under the resources/enable-cors directory for a guide.
Q: How do I secure my solr endpoint so that users do not have access to it?
A: The simplest solution is to use a Apache or nginx reverse proxy (See for example https://groups.google.com/forum/#!topic/ajax-solr/pLtYfm83I98).
Q: Can I use banana for non-time series data?
A: Yes, from version 1.3 onwards, non-time series data are also supported.
- LucidWorks SILK: http://www.lucidworks.com/lucidworks-silk/
- Webinar on LucidWorks SILK: http://programs.lucidworks.com/SiLK-introduction_Register.html.
- LogStash: http://logstash.net/
- SILK Use Cases: https://github.com/LucidWorks/silkusecases. Provides example configuration files, schemas and dashboards required to build applications that use Solr and Banana.
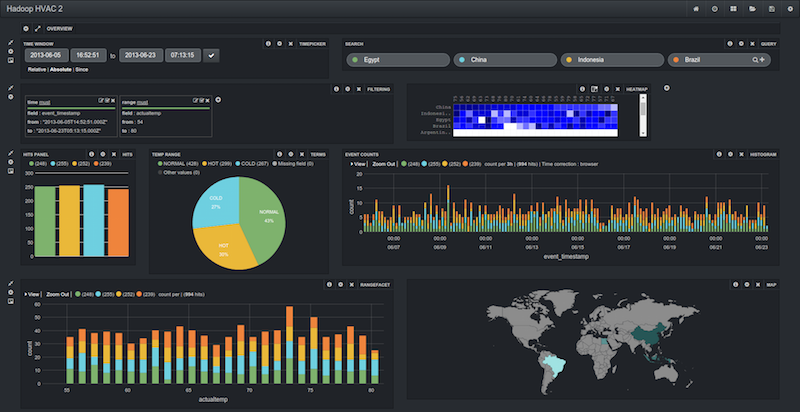
Banana uses the dashboard configuration capabilities of Kibana (from which it is forked) and ports key panels to work with Solr. Moreover, it provides many additional capabilities like heatmaps, range facets, panel specific filters, global parameters, and visualization of "group-by" style queries. We are continuing to add many new panels that go well beyond what is available in Kibana, helping users build complete applications that leverage the data stored in Apache Solr, HDFS and a variety of sources in the enterprise.
If you have any questions, please contact Andrew Thanalertvisuti ([email protected]) or Ravi Krishnamurthy ([email protected]).
Kibana is a trademark of Elasticsearch BV
Logstash is a trademark of Elasticsearch BV