This is a sentence chunker PHP class + visualizer
It includes the Berkeley Parser and an English grammar from https://github.com/slavpetrov/berkeleyparser
You can try it out here - http://lielakeda.lv/other/chunker/
Example input for visualizing with testChunker.php:
( (S (NP (NP (VBG Shifting) (NNS goods)) (CC and) (NP (NP (NNS passengers)) (PP (PP (IN from) (NP (NNS roads))) (PP (TO to) (NP (NP (ADJP (RBR less) (JJ polluting)) (NNS forms)) (PP (IN of) (NP (NN transport)))))))) (VP (MD will) (VP (VB be) (NP (NP (DT a) (JJ key) (NN factor)) (PP (IN in) (NP (DT any) (JJ sustainable) (NN transport) (NN policy.))))))) )
| Option | Description | Required |
|---|---|---|
| -m | minimal desired length of each chunk | no |
| -g | grammar file for Berkeley Parser | yes |
| -s | input sentence | yes |
php ChunkSentence.php -m 10 -g included/eng_sm6.gr -s "Recent works have proved that synthetic parallel data generated by existing translation models can be an effective solution to various neural machine translation (NMT) issues."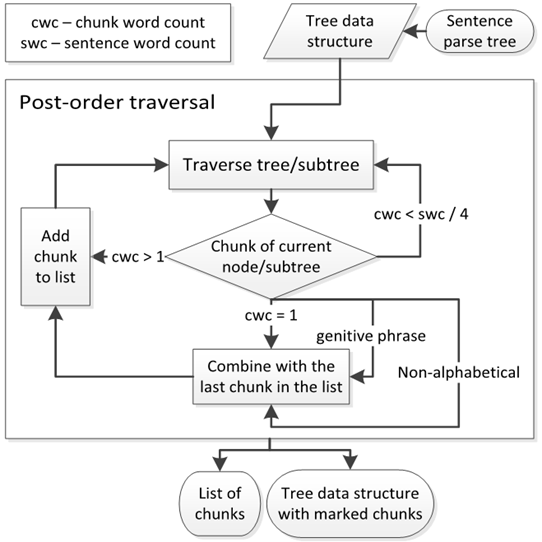
If you use the chunker, please cite the following paper:
Matiss Rikters and Inguna Skadina (2016). "Syntax-based Multi-system Machine Translation." In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016).
@InProceedings{RIKTERS16.156,
author = {Matīss Rikters and Inguna Skadina},
title = {Syntax-based Multi-system Machine Translation},
booktitle = {Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016)},
year = {2016},
month = {may},
date = {23-28},
location = {Portorož, Slovenia},
editor = {Nicoletta Calzolari (Conference Chair) and Khalid Choukri and Thierry Declerck and Sara Goggi and Marko Grobelnik and Bente Maegaard and Joseph Mariani and Helene Mazo and Asuncion Moreno and Jan Odijk and Stelios Piperidis},
publisher = {European Language Resources Association (ELRA)},
address = {Paris, France},
isbn = {978-2-9517408-9-1},
language = {english}
}