This project aims to predict whether an Airbnb is avaliable based on a bunch of features.
The data comes from the Inside Airbnb data platform, specifically the Airbnb listings in the region of Asheville, NC. It is cleaned up for this in-class competition. The attributes and the labels are created by some heuristic.
First, an exploratory analysis is presented, which contains how I preprocess data and search for the correlation between target variable and features. I also present results on the feature importance and feature selection. Second, I introduce the evaluated models and the motivations of selecting them. One novel part I want to highlight is that I employ a powerful hyperparameter auto-tuner and provide a reusable and easy-to-config implementation. Finally, I report the prediction results.
- Classification on Airbnb Availability Data
- Table of contents
- Project Report
- Installation
- Development
To use this project, first clone the repo on your device using the command below:
git init
git clone https://github.com/Mushroom-Wang/kaggle-airbnb.git
I draw the scatter plots of the target variable vs. each exploratory variable.
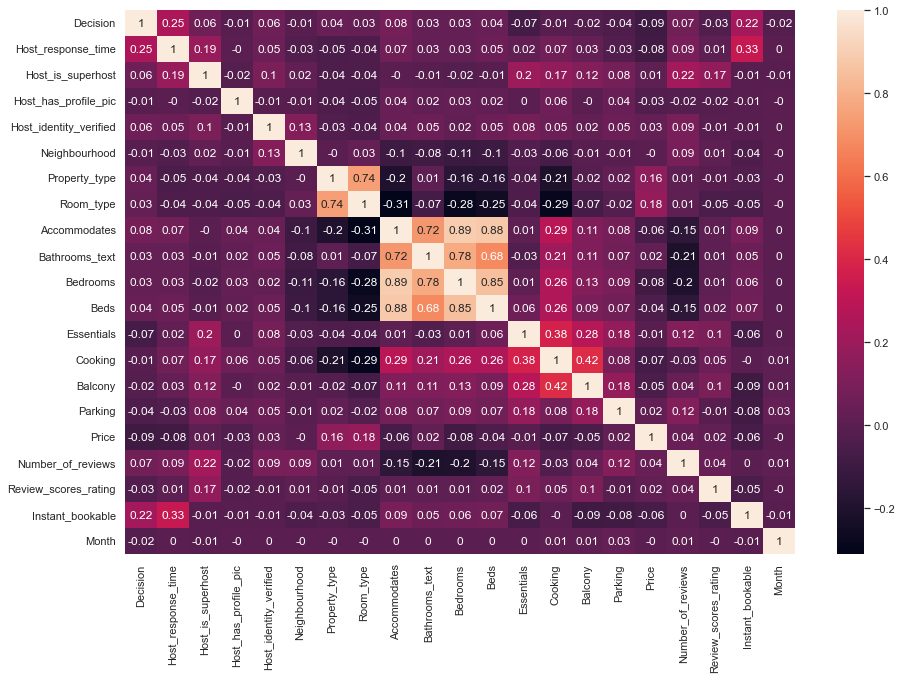
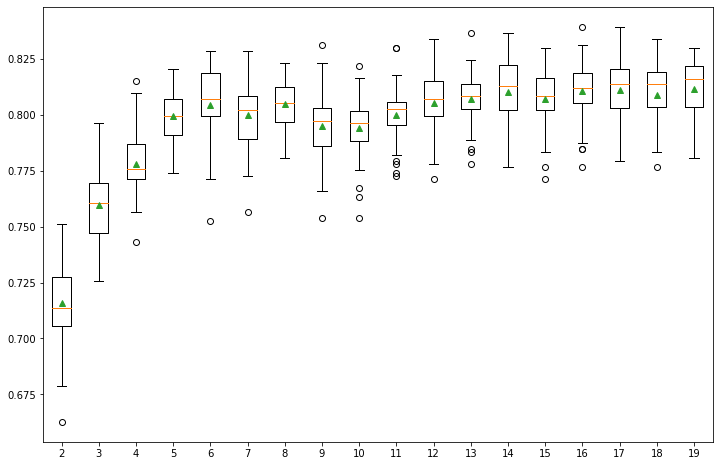
First, I use the Random Forest algorithm to choose the features. Second, I compare the accuracy of the training data when changing the number of features (from 2 to 20) to select. According to Figure 1, choosing more features yields a higher training accuracy. Since selecting 14 to 19 features yields similar classification accuracy, further analysis needed to determine which features are more important.
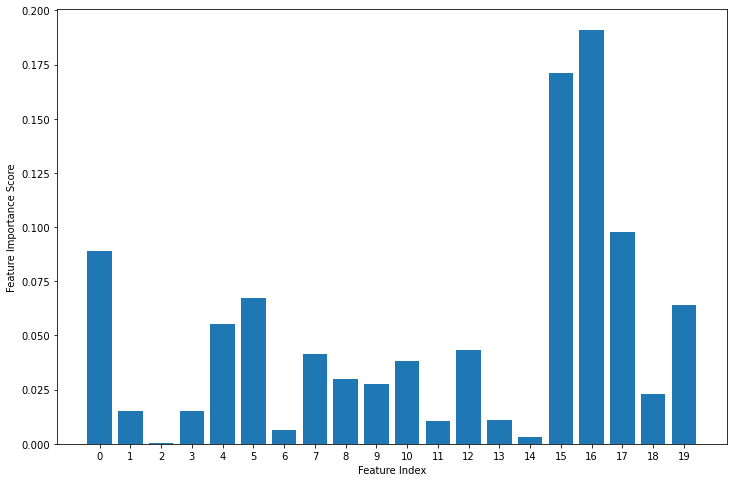
The feature importance provides some guidelines for me to drop several features when run the model later.
Leave a star in GitHub if you found this helpful.