Faster segmented sorting (and segmented problems in general) #224
Comments
|
I've written some extreme-case tests for Logarithmic Radix Binning (LRB) application in segmented sorting. In segmented sort, a thread block is assigned to a single segment. Therefore load balancing could affect work distribution between SMs. To test how workload imbalance affects performance, I've used the following pattern: all segments that satisfy the property
I haven't considered a runtime of LRB itself here. As far as I can see, the speedup from load balancing (for segmented sorting) can occur on a moderate segments number. In the case of a large number of segments, thread-block scheduling should balance between free SMs. The experiment also supports this premise. Further increase of waves counts leads to speedup convergence around 2%. I think that the load balancing property of LRB could be more useful in algorithms with different level of parallelism, for example, thread per segment. In this case, it could reduce thread divergence. Therefore I think it should be helpful to have LRB as a separate algorithm in CUB. Regarding LRB application for segmented sorting, its different property is most helpful here. Clustering segments could facilitate segmented scan specialisation. For kernel specialisation benchmarking, I've generated different input data pattern. This time, all the large segments are at the head of the list. The tail contains small segments. This pattern eliminates the effects of load balancing. After performing the LRB, I've processed all the small segments with a different kernel. It assigns a warp to a segment and executes a bitonic warp sort.
Kernel specialisation for small segments demonstrates significant speedup. I've also tried to specialise kernel for large segments. After LRB, I process large segments by the whole device. It's done by a call to cub::DeviceRadixSort::SortKeys. Unlike small kernel specialisation, the speedup here depends on the number of large segments. It might be worth developing a different kernel for this purpose.
|


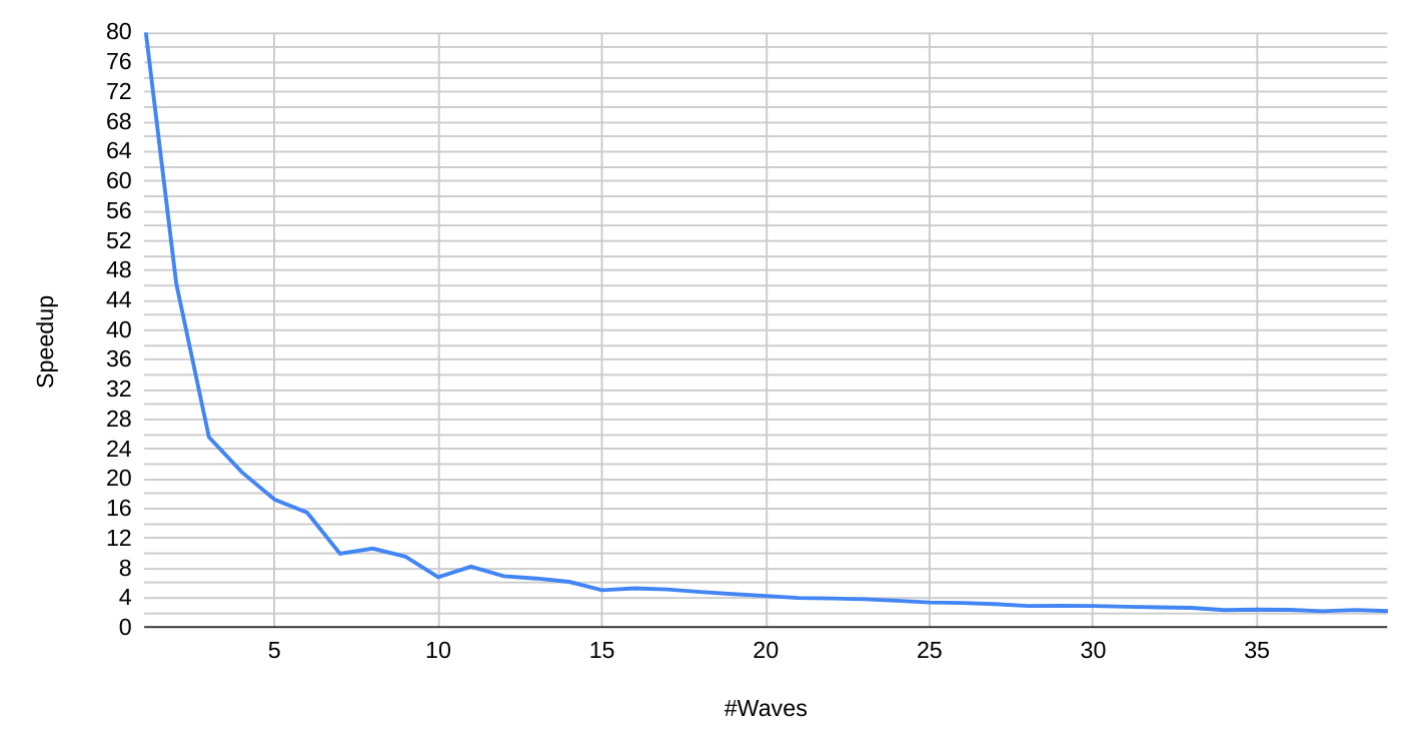
|
Just to make sure we're on the same page, can you define what you mean by "waves" in the above? These are good ideas. Specializing based on work size makes sense, as does having the LRB machinery as a shared utility between the segmented algorithms. For now, let's focus on getting LRB implemented as a utility, and start applying it to the segmented algorithms, and look into specializing for size later. |
|
Adding an update the latest version of the segmented sort code is available here: |
|
The wave hare stands for the segments count equal to the SMs count. For example, if a GPU has two SMs, four segments form two waves. This term is convenient here because it's possible to launch |
|
@senior-zero @allisonvacanti It has come to my attention that this can greatly improve a particular math function of high importance. What can need to be done to get this into the next release of CUB, which I think is 1.14? So it'll be in next release of CTK, and we can start using it. |
Hello, @mnicely! LRB part can be ready quite soon. The prototype is available here. Specialization of segmented sorting could take more time. Do you need a generalized algorithm for load balancing or optimized segmented sorting? |
|
@senior-zero Thanks for the quick reply. We need optimized seqmented sorting
|
|
Closing as #357 added a (significantly!) improved segmented sort. |
Segmented problems can suffer from workload imbalance if the distribution of the segment sizes vary. The workload imbalance becomes even more challenging when the number of segments is very large.
The attached zip file has an efficient segmented sort that is based on NVIDIA's CUB library. Most of the sorting is done using CUB's sorting functionality. The key thing that this segmented sorting algorithm offers is simple and efficient load-balancing.
lrb_sort.cuh.zip
The solution used for the segmented sort is applicable to other segmented problems.
Details of the algorithm (and performance) can be found in the following paper.
The text was updated successfully, but these errors were encountered: