-
Notifications
You must be signed in to change notification settings - Fork 475
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[Doc]Add English version of documents in examples/ (#1042)
* 第一次提交 * 补充一处漏翻译 * deleted: docs/en/quantize.md * Update one translation * Update en version * Update one translation in code * Standardize one writing * Standardize one writing * Update some en version * Fix a grammer problem * Update en version for api/vision result * Merge branch 'develop' of https://github.com/charl-u/FastDeploy into develop * Checkout the link in README in vision_results/ to the en documents * Modify a title * Add link to serving/docs/ * Finish translation of demo.md * Update english version of serving/docs/ * Update title of readme * Update some links * Modify a title * Update some links * Update en version of java android README * Modify some titles * Modify some titles * Modify some titles * modify article to document * update some english version of documents in examples * Add english version of documents in examples/visions * Sync to current branch * Add english version of documents in examples
- Loading branch information
Showing
74 changed files
with
2,312 additions
and
575 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,3 +1,4 @@ | ||
| [English](../../en/build_and_install/sophgo.md) | 简体中文 | ||
| # SOPHGO 部署库编译 | ||
|
|
||
| ## SOPHGO 环境准备 | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,30 @@ | ||
| 简体中文 | [English](README.md) | ||
| # PaddleJsConverter | ||
|
|
||
| ## Installation | ||
|
|
||
| System Requirements: | ||
|
|
||
| * paddlepaddle >= 2.0.0 | ||
| * paddlejslite >= 0.0.2 | ||
| * Python3: 3.5.1+ / 3.6 / 3.7 | ||
| * Python2: 2.7.15+ | ||
|
|
||
| #### Install PaddleJsConverter | ||
|
|
||
| <img src="https://img.shields.io/pypi/v/paddlejsconverter" alt="version"> | ||
|
|
||
| ```shell | ||
| pip install paddlejsconverter | ||
|
|
||
| # or | ||
| pip3 install paddlejsconverter | ||
| ``` | ||
|
|
||
|
|
||
| ## Usage | ||
|
|
||
| ```shell | ||
| paddlejsconverter --modelPath=user_model_path --paramPath=user_model_params_path --outputDir=model_saved_path --useGPUOpt=True | ||
| ``` | ||
| 注意:useGPUOpt 选项默认不开启,如果模型用在 gpu backend(webgl/webgpu),则开启 useGPUOpt,如果模型运行在(wasm/plain js)则不要开启。 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,80 @@ | ||
| English | [简体中文](RNN.md) | ||
| # The computation process of RNN operator | ||
|
|
||
| ## 1. Understanding of RNN | ||
|
|
||
| **RNN** is a recurrent neural network, including an input layer, a hidden layer and an output layer, which is specialized in processing sequential data. | ||
|
|
||
| 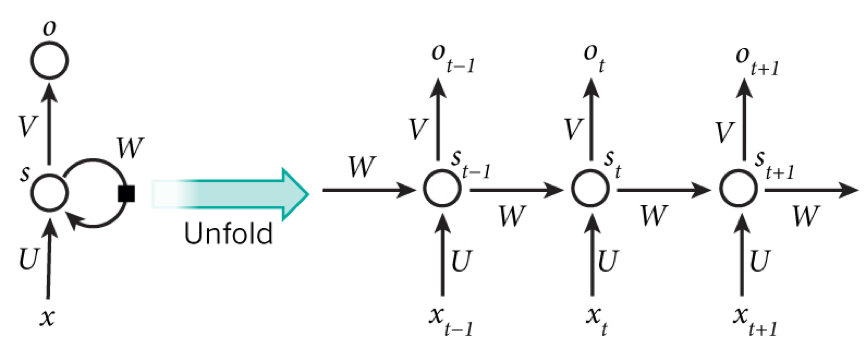 | ||
| paddle official document: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/RNN_cn.html#rnn | ||
|
|
||
| paddle source code implementation: https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/rnn_op.h#L812 | ||
|
|
||
| ## 2. How to compute RNN | ||
|
|
||
| At moment t, the input layer is , hidden layer is , output layer is . As the picture above, isn't just decided by ,it is also related to . The formula is as follows.: | ||
|
|
||
| 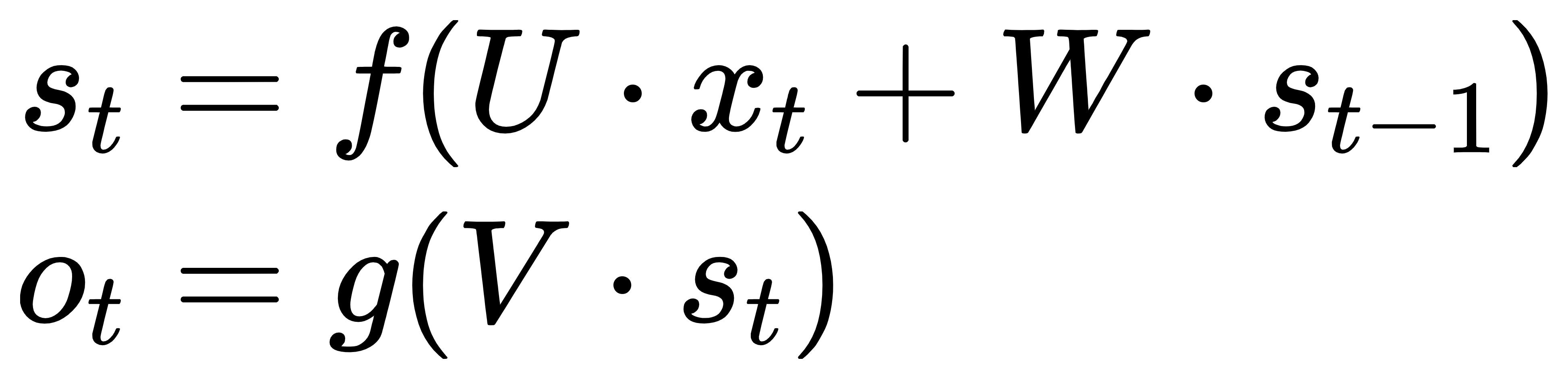 | ||
|
|
||
| ## 3. RNN operator implementation in pdjs | ||
|
|
||
| Because the gradient disappearance problem exists in RNN, and more contextual information cannot be obtained, **LSTM (Long Short Term Memory)** is used in CRNN, which is a special kind of RNN that can preserve long-term dependencies. | ||
|
|
||
| Based on the image sequence, the two directions of context are mutually useful and complementary. Since the LSTM is unidirectional, two LSTMs, one forward and one backward, are combined into a **bidirectional LSTM**. In addition, multiple layers of bidirectional LSTMs can be stacked. ch_PP-OCRv2_rec_infer recognition model is using a two-layer bidirectional LSTM structure. The calculation process is shown as follows. | ||
|
|
||
| #### Take ch_ppocr_mobile_v2.0_rec_infer model, rnn operator as an example | ||
| ```javascript | ||
| { | ||
| Attr: { | ||
| mode: 'LSTM' | ||
| // Whether bidirectional, if true, it is necessary to traverse both forward and reverse. | ||
| is_bidirec: true | ||
| // Number of hidden layers, representing the number of loops. | ||
| num_layers: 2 | ||
| } | ||
|
|
||
| Input: [ | ||
| transpose_1.tmp_0[25, 1, 288] | ||
| ] | ||
|
|
||
| PreState: [ | ||
| fill_constant_batch_size_like_0.tmp_0[4, 1, 48], | ||
| fill_constant_batch_size_like_1.tmp_0[4, 1, 48] | ||
| ] | ||
|
|
||
| WeightList: [ | ||
| lstm_cell_0.w_0[192, 288], lstm_cell_0.w_1[192, 48], | ||
| lstm_cell_1.w_0[192, 288], lstm_cell_1.w_1[192, 48], | ||
| lstm_cell_2.w_0[192, 96], lstm_cell_2.w_1[192, 48], | ||
| lstm_cell_3.w_0[192, 96], lstm_cell_3.w_1[192, 48], | ||
| lstm_cell_0.b_0[192], lstm_cell_0.b_1[192], | ||
| lstm_cell_1.b_0[192], lstm_cell_1.b_1[192], | ||
| lstm_cell_2.b_0[192], lstm_cell_2.b_1[192], | ||
| lstm_cell_3.b_0[192], lstm_cell_3.b_1[192] | ||
| ] | ||
|
|
||
| Output: [ | ||
| lstm_0.tmp_0[25, 1, 96] | ||
| ] | ||
| } | ||
| ``` | ||
|
|
||
| #### Overall computation process | ||
| 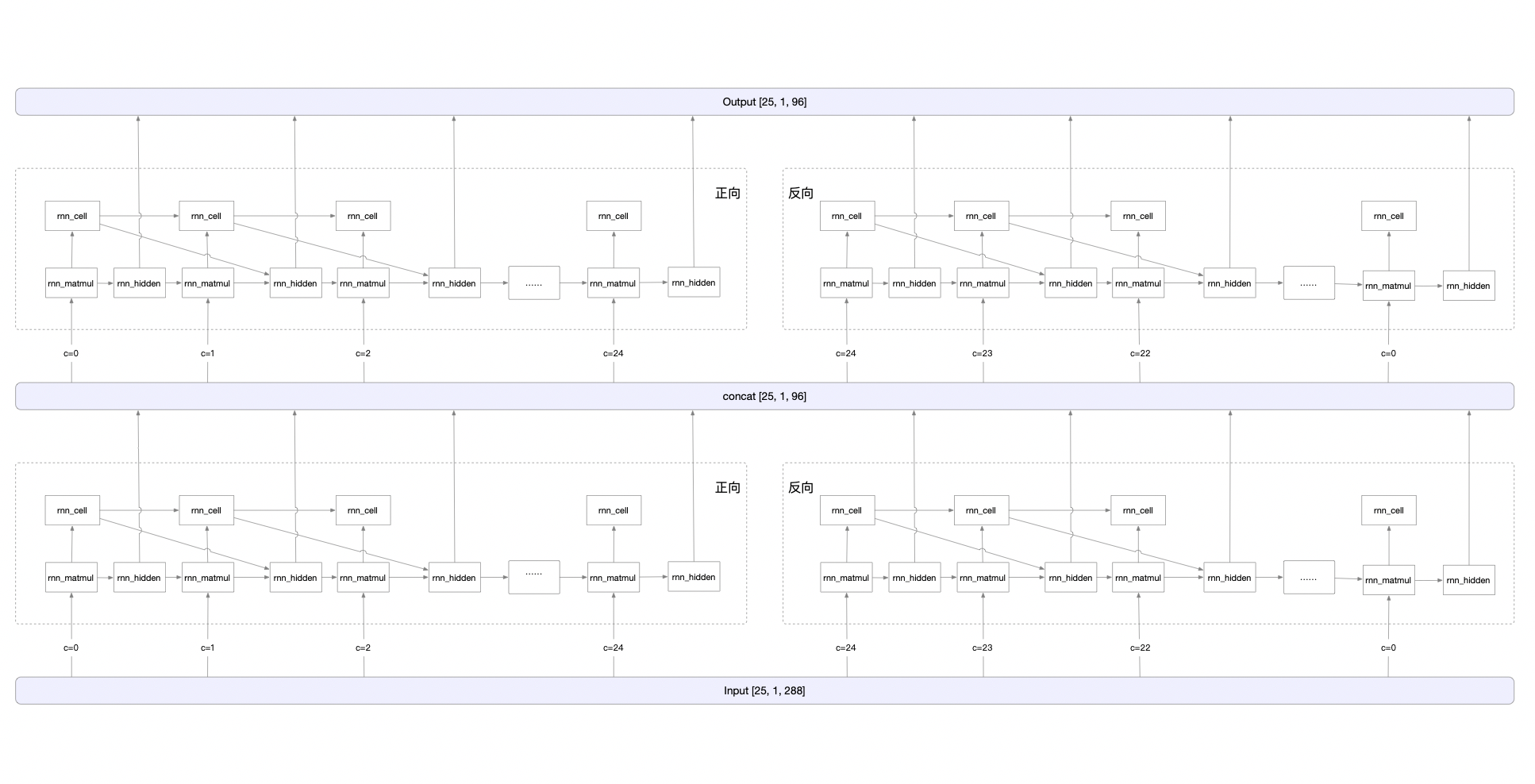 | ||
| #### Add op in rnn calculation | ||
| 1) rnn_origin | ||
| Formula: blas.MatMul(Input, WeightList_ih, blas_ih) + blas.MatMul(PreState, WeightList_hh, blas_hh) | ||
|
|
||
| 2) rnn_matmul | ||
| Formula: rnn_matmul = rnn_origin + Matmul( $ S_{t-1} $, WeightList_hh) | ||
|
|
||
| 3) rnn_cell | ||
| Method: Split the rnn_matmul op output into 4 copies, each copy performs a different activation function calculation, and finally outputs lstm_x_y.tmp_c[1, 1, 48]. x∈[0, 3], y∈[0, 24]. | ||
| For details, please refer to [rnn_cell](../paddlejs-backend-webgl/src/ops/shader/rnn/rnn_cell.ts). | ||
|
|
||
|
|
||
| 4) rnn_hidden | ||
| Split the rnn_matmul op output into 4 copies, each copy performs a different activation function calculation, and finally outputs lstm_x_y.tmp_h[1, 1, 48]. x∈[0, 3], y∈[0, 24]. | ||
| For details, please refer to [rnn_hidden](../paddlejs-backend-webgl/src/ops/shader/rnn/rnn_hidden.ts). | ||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,9 +1,10 @@ | ||
| # PaddleSpeech 流式语音合成 | ||
| English | [简体中文](README_CN.md) | ||
| # PaddleSpeech Streaming Text-to-Speech | ||
|
|
||
|
|
||
| - 本文示例的实现来自[PaddleSpeech 流式语音合成](https://github.com/PaddlePaddle/PaddleSpeech/tree/r1.2). | ||
| - The examples in this document are from [PaddleSpeech Streaming Text-to-Speech](https://github.com/PaddlePaddle/PaddleSpeech/tree/r1.2). | ||
|
|
||
| ## 详细部署文档 | ||
| ## Detailed deployment document | ||
|
|
||
| - [Python部署](python) | ||
| - [Serving部署](serving) | ||
| - [Python deployment](python) | ||
| - [Serving deployment](serving) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,10 @@ | ||
| 简体中文 | [English](README.md) | ||
| # PaddleSpeech 流式语音合成 | ||
|
|
||
|
|
||
| - 本文示例的实现来自[PaddleSpeech 流式语音合成](https://github.com/PaddlePaddle/PaddleSpeech/tree/r1.2). | ||
|
|
||
| ## 详细部署文档 | ||
|
|
||
| - [Python部署](python) | ||
| - [Serving部署](serving) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,63 +1,64 @@ | ||
| # FastDeploy Diffusion模型高性能部署 | ||
| English | [简体中文](README_CN.md) | ||
| # FastDeploy Diffusion Model High-Performance Deployment | ||
|
|
||
| 本部署示例使用⚡️`FastDeploy`在Huggingface团队[Diffusers](https://github.com/huggingface/diffusers)项目设计的`DiffusionPipeline`基础上,完成Diffusion模型的高性能部署。 | ||
| This document completes the high-performance deployment of the Diffusion model with ⚡️`FastDeploy`, based on `DiffusionPipeline` in project [Diffusers](https://github.com/huggingface/diffusers) designed by Huggingface. | ||
|
|
||
| ### 部署模型准备 | ||
| ### Preperation for Deployment | ||
|
|
||
| 本示例需要使用训练模型导出后的部署模型。有两种部署模型的获取方式: | ||
| This example needs the deployment model after exporting the training model. Here are two ways to obtain the deployment model: | ||
|
|
||
| - 模型导出方式,可参考[模型导出文档](./export.md)导出部署模型。 | ||
| - 下载部署模型。为了方便开发者快速测试本示例,我们已经将部分`Diffusion`模型预先导出,开发者只要下载模型就可以快速测试: | ||
| - Methods for model export. Please refer to [Model Export](./export_EN.md) to export deployment model. | ||
| - Download the deployment model. To facilitate developers to test the example, we have pre-exported some of the `Diffusion` models, so you can just download models and test them quickly: | ||
|
|
||
| | 模型 | Scheduler | | ||
| | Model | Scheduler | | ||
| |----------|--------------| | ||
| | [CompVis/stable-diffusion-v1-4](https://bj.bcebos.com/fastdeploy/models/stable-diffusion/CompVis/stable-diffusion-v1-4.tgz) | PNDM | | ||
| | [runwayml/stable-diffusion-v1-5](https://bj.bcebos.com/fastdeploy/models/stable-diffusion/runwayml/stable-diffusion-v1-5.tgz) | EulerAncestral | | ||
|
|
||
| ## 环境依赖 | ||
| ## Environment Dependency | ||
|
|
||
| 在示例中使用了PaddleNLP的CLIP模型的分词器,所以需要执行以下命令安装依赖。 | ||
| In the example, the word splitter in CLIP model of PaddleNLP is required, so you need to run the following line to install the dependency. | ||
|
|
||
| ```shell | ||
| pip install paddlenlp paddlepaddle-gpu | ||
| ``` | ||
|
|
||
| ### 快速体验 | ||
| ### Quick Experience | ||
|
|
||
| 我们经过部署模型准备,可以开始进行测试。下面将指定模型目录以及推理引擎后端,运行`infer.py`脚本,完成推理。 | ||
| We are ready to start testing after model deployment. Here we will specify the model directory as well as the inference engine backend, and run the `infer.py` script to complete the inference. | ||
|
|
||
| ``` | ||
| python infer.py --model_dir stable-diffusion-v1-4/ --scheduler "pndm" --backend paddle | ||
| ``` | ||
|
|
||
| 得到的图像文件为fd_astronaut_rides_horse.png。生成的图片示例如下(每次生成的图片都不相同,示例仅作参考): | ||
| The image file is fd_astronaut_rides_horse.png. An example of the generated image is as follows (the generated image is different each time, the example is for reference only): | ||
|
|
||
|  | ||
|
|
||
| 如果使用stable-diffusion-v1-5模型,则可执行以下命令完成推理: | ||
| If the stable-diffusion-v1-5 model is used, you can run these to complete the inference. | ||
|
|
||
| ``` | ||
| # GPU上推理 | ||
| # Inference on GPU | ||
| python infer.py --model_dir stable-diffusion-v1-5/ --scheduler "euler_ancestral" --backend paddle | ||
| # 在昆仑芯XPU上推理 | ||
| # Inference on KunlunXin XPU | ||
| python infer.py --model_dir stable-diffusion-v1-5/ --scheduler "euler_ancestral" --backend paddle-kunlunxin | ||
| ``` | ||
|
|
||
| #### 参数说明 | ||
| #### Parameters | ||
|
|
||
| `infer.py` 除了以上示例的命令行参数,还支持更多命令行参数的设置。以下为各命令行参数的说明。 | ||
| `infer.py` supports more command line parameters than the above example. The following is a description of each command line parameter. | ||
|
|
||
| | 参数 |参数说明 | | ||
| | Parameter |Description | | ||
| |----------|--------------| | ||
| | --model_dir | 导出后模型的目录。 | | ||
| | --model_format | 模型格式。默认为`'paddle'`,可选列表:`['paddle', 'onnx']`。 | | ||
| | --backend | 推理引擎后端。默认为`paddle`,可选列表:`['onnx_runtime', 'paddle', 'paddle-kunlunxin']`,当模型格式为`onnx`时,可选列表为`['onnx_runtime']`。 | | ||
| | --scheduler | StableDiffusion 模型的scheduler。默认为`'pndm'`。可选列表:`['pndm', 'euler_ancestral']`,StableDiffusio模型对应的scheduler可参考[ppdiffuser模型列表](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/examples/textual_inversion)。| | ||
| | --unet_model_prefix | UNet模型前缀。默认为`unet`。 | | ||
| | --vae_model_prefix | VAE模型前缀。默认为`vae_decoder`。 | | ||
| | --text_encoder_model_prefix | TextEncoder模型前缀。默认为`text_encoder`。 | | ||
| | --inference_steps | UNet模型运行的次数,默认为100。 | | ||
| | --image_path | 生成图片的路径。默认为`fd_astronaut_rides_horse.png`。 | | ||
| | --device_id | gpu设备的id。若`device_id`为-1,视为使用cpu推理。 | | ||
| | --use_fp16 | 是否使用fp16精度。默认为`False`。使用tensorrt或者paddle-tensorrt后端时可以设为`True`开启。 | | ||
| | --model_dir | Directory of the exported model. | | ||
| | --model_format | Model format. Default is `'paddle'`, optional list: `['paddle', 'onnx']`. | | ||
| | --backend | Inference engine backend. Default is`paddle`, optional list: `['onnx_runtime', 'paddle', 'paddle-kunlunxin']`, when the model format is `onnx`, optional list is`['onnx_runtime']`. | | ||
| | --scheduler | Scheduler in StableDiffusion model. Default is`'pndm'`, optional list `['pndm', 'euler_ancestral']`. The scheduler corresponding to the StableDiffusio model can be found in [ppdiffuser model list](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/examples/textual_inversion).| | ||
| | --unet_model_prefix | UNet model prefix, default is `unet`. | | ||
| | --vae_model_prefix | VAE model prefix, defalut is `vae_decoder`. | | ||
| | --text_encoder_model_prefix | TextEncoder model prefix, default is `text_encoder`. | | ||
| | --inference_steps | Running times of UNet model, default is 100. | | ||
| | --image_path | Path to the generated images, defalut is `fd_astronaut_rides_horse.png`. | | ||
| | --device_id | gpu id. If `device_id` is -1, cpu is used for inference. | | ||
| | --use_fp16 | Indicates if fp16 is used, default is `False`. Can be set to `True` when using tensorrt or paddle-tensorrt backend. | |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,64 @@ | ||
| 简体中文 | [English](README.md) | ||
| # FastDeploy Diffusion模型高性能部署 | ||
|
|
||
| 本部署示例使用⚡️`FastDeploy`在Huggingface团队[Diffusers](https://github.com/huggingface/diffusers)项目设计的`DiffusionPipeline`基础上,完成Diffusion模型的高性能部署。 | ||
|
|
||
| ### 部署模型准备 | ||
|
|
||
| 本示例需要使用训练模型导出后的部署模型。有两种部署模型的获取方式: | ||
|
|
||
| - 模型导出方式,可参考[模型导出文档](./export.md)导出部署模型。 | ||
| - 下载部署模型。为了方便开发者快速测试本示例,我们已经将部分`Diffusion`模型预先导出,开发者只要下载模型就可以快速测试: | ||
|
|
||
| | 模型 | Scheduler | | ||
| |----------|--------------| | ||
| | [CompVis/stable-diffusion-v1-4](https://bj.bcebos.com/fastdeploy/models/stable-diffusion/CompVis/stable-diffusion-v1-4.tgz) | PNDM | | ||
| | [runwayml/stable-diffusion-v1-5](https://bj.bcebos.com/fastdeploy/models/stable-diffusion/runwayml/stable-diffusion-v1-5.tgz) | EulerAncestral | | ||
|
|
||
| ## 环境依赖 | ||
|
|
||
| 在示例中使用了PaddleNLP的CLIP模型的分词器,所以需要执行以下命令安装依赖。 | ||
|
|
||
| ```shell | ||
| pip install paddlenlp paddlepaddle-gpu | ||
| ``` | ||
|
|
||
| ### 快速体验 | ||
|
|
||
| 我们经过部署模型准备,可以开始进行测试。下面将指定模型目录以及推理引擎后端,运行`infer.py`脚本,完成推理。 | ||
|
|
||
| ``` | ||
| python infer.py --model_dir stable-diffusion-v1-4/ --scheduler "pndm" --backend paddle | ||
| ``` | ||
|
|
||
| 得到的图像文件为fd_astronaut_rides_horse.png。生成的图片示例如下(每次生成的图片都不相同,示例仅作参考): | ||
|
|
||
|  | ||
|
|
||
| 如果使用stable-diffusion-v1-5模型,则可执行以下命令完成推理: | ||
|
|
||
| ``` | ||
| # GPU上推理 | ||
| python infer.py --model_dir stable-diffusion-v1-5/ --scheduler "euler_ancestral" --backend paddle | ||
| # 在昆仑芯XPU上推理 | ||
| python infer.py --model_dir stable-diffusion-v1-5/ --scheduler "euler_ancestral" --backend paddle-kunlunxin | ||
| ``` | ||
|
|
||
| #### 参数说明 | ||
|
|
||
| `infer.py` 除了以上示例的命令行参数,还支持更多命令行参数的设置。以下为各命令行参数的说明。 | ||
|
|
||
| | 参数 |参数说明 | | ||
| |----------|--------------| | ||
| | --model_dir | 导出后模型的目录。 | | ||
| | --model_format | 模型格式。默认为`'paddle'`,可选列表:`['paddle', 'onnx']`。 | | ||
| | --backend | 推理引擎后端。默认为`paddle`,可选列表:`['onnx_runtime', 'paddle', 'paddle-kunlunxin']`,当模型格式为`onnx`时,可选列表为`['onnx_runtime']`。 | | ||
| | --scheduler | StableDiffusion 模型的scheduler。默认为`'pndm'`。可选列表:`['pndm', 'euler_ancestral']`,StableDiffusio模型对应的scheduler可参考[ppdiffuser模型列表](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/examples/textual_inversion)。| | ||
| | --unet_model_prefix | UNet模型前缀。默认为`unet`。 | | ||
| | --vae_model_prefix | VAE模型前缀。默认为`vae_decoder`。 | | ||
| | --text_encoder_model_prefix | TextEncoder模型前缀。默认为`text_encoder`。 | | ||
| | --inference_steps | UNet模型运行的次数,默认为100。 | | ||
| | --image_path | 生成图片的路径。默认为`fd_astronaut_rides_horse.png`。 | | ||
| | --device_id | gpu设备的id。若`device_id`为-1,视为使用cpu推理。 | | ||
| | --use_fp16 | 是否使用fp16精度。默认为`False`。使用tensorrt或者paddle-tensorrt后端时可以设为`True`开启。 | |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,12 +1,13 @@ | ||
| # StableDiffusion C++部署示例 | ||
| English | [简体中文](README_CN.md) | ||
| # StableDiffusion C++ Deployment | ||
|
|
||
| 在部署前,需确认以下两个步骤 | ||
| Before deployment, the following two steps need to be confirmed: | ||
|
|
||
| - 1. 软硬件环境满足要求,参考[FastDeploy环境要求](../../../../docs/cn/build_and_install/download_prebuilt_libraries.md) | ||
| - 2. 根据开发环境,下载预编译部署库和samples代码,参考[FastDeploy预编译库](../../../../docs/cn/build_and_install/download_prebuilt_libraries.md) | ||
| - 1. Hardware and software environment meets the requirements. Please refer to [Environment requirements for FastDeploy](../../../../docs/en/build_and_install/download_prebuilt_libraries.md) | ||
| - 2. Download pre-compiled libraries and samples according to the development environment. Please refer to [FastDeploy pre-compiled libraries](../../../../docs/en/build_and_install/download_prebuilt_libraries.md) | ||
|
|
||
| 本目录下提供`*_infer.cc`快速完成StableDiffusion各任务的C++部署示例。 | ||
| This directory provides `*_infer.cc` to quickly complete C++ deployment examples for each task of StableDiffusion. | ||
|
|
||
| ## Inpaint任务 | ||
| ## Inpaint Task | ||
|
|
||
| StableDiffusion Inpaint任务是一个根据提示文本补全图片的任务,具体而言就是用户给定提示文本,原始图片以及原始图片的mask图片,该任务输出补全后的图片。 | ||
| The StableDiffusion Inpaint task is a task that completes the image based on the prompt text. User provides the prompt text, the original image and the mask image of the original image, and the task outputs the completed image. |
Oops, something went wrong.