{kind=link}
Realtime Analysis of German Election noting tweets
Collects, sorts, analyzes and presents tweets from german politicians regarding the election 2021.
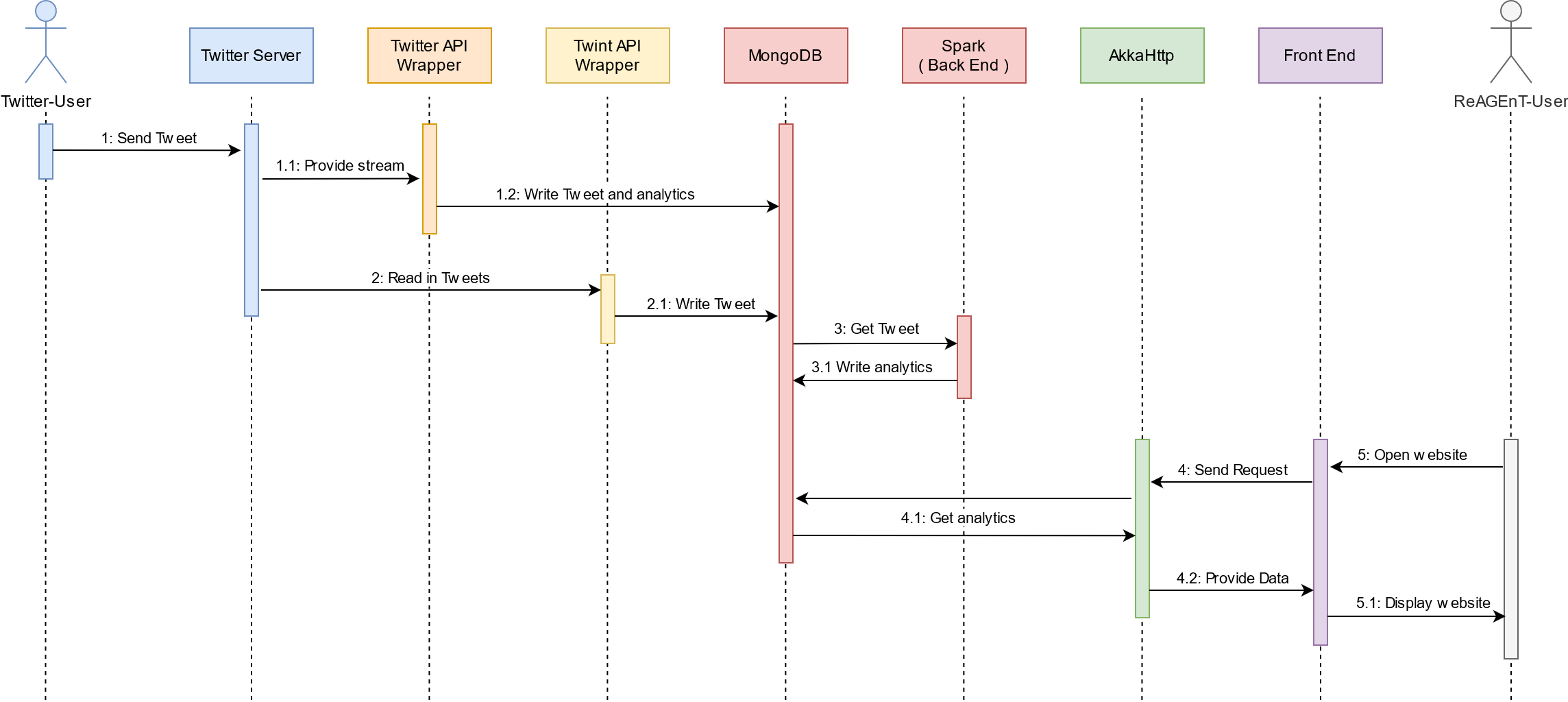
The API Wrapper is responsible for collecting tweets from the Twitter API v2 endpoint using Spark Structured Streaming. The data is sorted, analyzed and saved to Mongo DB according to rules set in main class.
Written in Scala.
Historical data from Twitter is loaded with the help of the inofficial Twint API
Written in Python.
Raw data from the Mongo DB is loaded and used to train a model with the help of the Spark Machine Learning library (MLlib).
Written in Scala.
This part is responsible for taking the raw information from the Mongo DB and computing the information for the frontend. Thereafter saving it again in the Mongo DB.
Written in Scala.
Routes Mongo DB content to the frontend.
Written in Scala.
Web representation of analyzed data.
Written in JavaScript.
Web representation of analyzed data. We are using the micro front end architecture, this project / repository acts as the container project that "contains" and loads the individual micro frontends. This container app is built with React, and it loads the micro front end with two different approaches:
- Loading the bundled JS file from the local folder (
src/wc) - Loading the bundled JS file from a remote source (in this case, from site hosted on Github Pages)
All the individual micro front ends are bundled into a single JS file and converted into a web component, so the project could be framework agnostic.
Please take a look into our Proof of Concept project for a more simplified example.
Dependencies that we used are:
- Direflow
- Reactivesearch
- Tailwindcss v2
- craco-swc
- Material UI
- Miragejs
- React DnD
- random-ext
- faker
- ESLint
- Recharts
- axios
Written in TypeScript.
Engine to search for tweets by keyword and filter them by party.
Elasticsearch provides the tweets as well as the search functionality. An Apache Kafka Producer extracts tweets via the Twitter Api in real time and inserts them into the Elasticsearch dataset.
Written in Java.