A command-line tool for processing data with functional pipelines.
nsa> cat people.json | R \
'filter (p) -> p.city is /Port/ or p.name is /^Dr\./' \
'project <[ name city creditcard ]>' \
-o table --compact
┌──────────────────┬─────────────────┬───────────────────┐
│ name │ city │ mac │
├──────────────────┼─────────────────┼───────────────────┤
│ Dr. Araceli Lang │ Yvettemouth │ 9e:ea:28:41:2a:50 │
│ Terrell Boyle │ Port Reaganfort │ c5:32:09:5a:f7:15 │
│ Libby Renner │ Port Reneeside │ 9c:63:13:31:c4:ac │
└──────────────────┴─────────────────┴───────────────────┘Brings together Ramda's curried, data-last API and LiveScript's terse and powerful syntax.
With a variety of supported input/output types and the ability pull any module from npm, ramda-cli is a potent tool for many kinds of data manipulation in command-line environment.
- Examples
- Cookbook
- Tutorial: Using ramda-cli to process and display data from GitHub API
- Essential LiveScript for ramda-cli
npm install -g ramda-clicat data.json | R [function] ...The idea is to compose functions into a pipeline of operations that when applied to given data, produces the desired output.
By default, the function is applied to a stream of JSON data read from stdin, and the output data is sent to standard out as stringified JSON.
Technically, function should be a snippet of LiveScript that evaluates into
a function. However, JavaScript function call syntax is valid LS, so if more
suitable, JavaScript can be used when writing functions.
If multiple function arguments are supplied, they are composed into a
pipeline in order from left to right, as with
R.pipe.
All Ramda's functions are available directly in the scope. See http://ramdajs.com/docs/ for a full list.
Usage: R [options] [function] ...
-f, --file read a function from a js/ls file instead of args; useful for
larger scripts
-c, --compact compact output for JSON and tables
-s, --slurp read JSON objects from stdin as one big list
-S, --unslurp unwraps a list before output so that each item is formatted and
printed separately
-i, --input-type read input from stdin as (one of: raw, csv, tsv)
-o, --output-type format output sent to stdout (one of: pretty, raw, csv, tsv, table)
-p, --pretty pretty-printed output with colors, alias to -o pretty
-r, --raw-input alias for --input-type raw
-R, --raw-output alias for --output-type raw
-C, --configure edit config in $EDITOR
-n, --no-stdin don't read input from stdin
-v, --verbose print debugging information (use -vv for even more)
--version print version
-h, --help displays help
Aside from JSON, few other types of output are supported:
Print pretty output.
With raw output type when a string value is produced, the result will be written to stdout as is without any formatting.
CSV or TSV output type can be used when pipeline evaluates to an array of objects, an array of arrays or when stdin consists of a stream of bare objects. First object's keys will determine the headers.
Print ~any shape of data as a table. If used with a list of objects, uses the first object's keys as headers. See an example below.
# Sum a list of numbers in JSON
echo [1,2,3] | R 'sum'
6
# Multiply each value by 2
echo [1,2,3] | R 'map multiply 2'
[2,4,6]
# Parentheses can be used like in JavaScript, if so preferred
echo [1,2,3] | R 'map(multiply(2))'
[2,4,6]cat people.json | R 'pluck \name' 'filter (name) -> name.0 is \B)' -o raw
Brando Jacobson
Betsy Bayer
Beverly Gleichner
Beryl LindgrenRamda functions used:
pluck,filter
Data: people.json
List versions of npm module with dates formatted with timeago
It looks for timeago installed to $HOME/node_modules.
npm view ramda --json | R \
'prop \time' 'to-pairs' \
'map -> version: it.0, time: require("timeago")(it.1)' \
-o tsv | column -t -s $'\t'
...
0.12.0 2 months ago
0.13.0 2 months ago
0.14.0 12 days agoSearch twitter for people who tweeted about ramda and pretty print the result
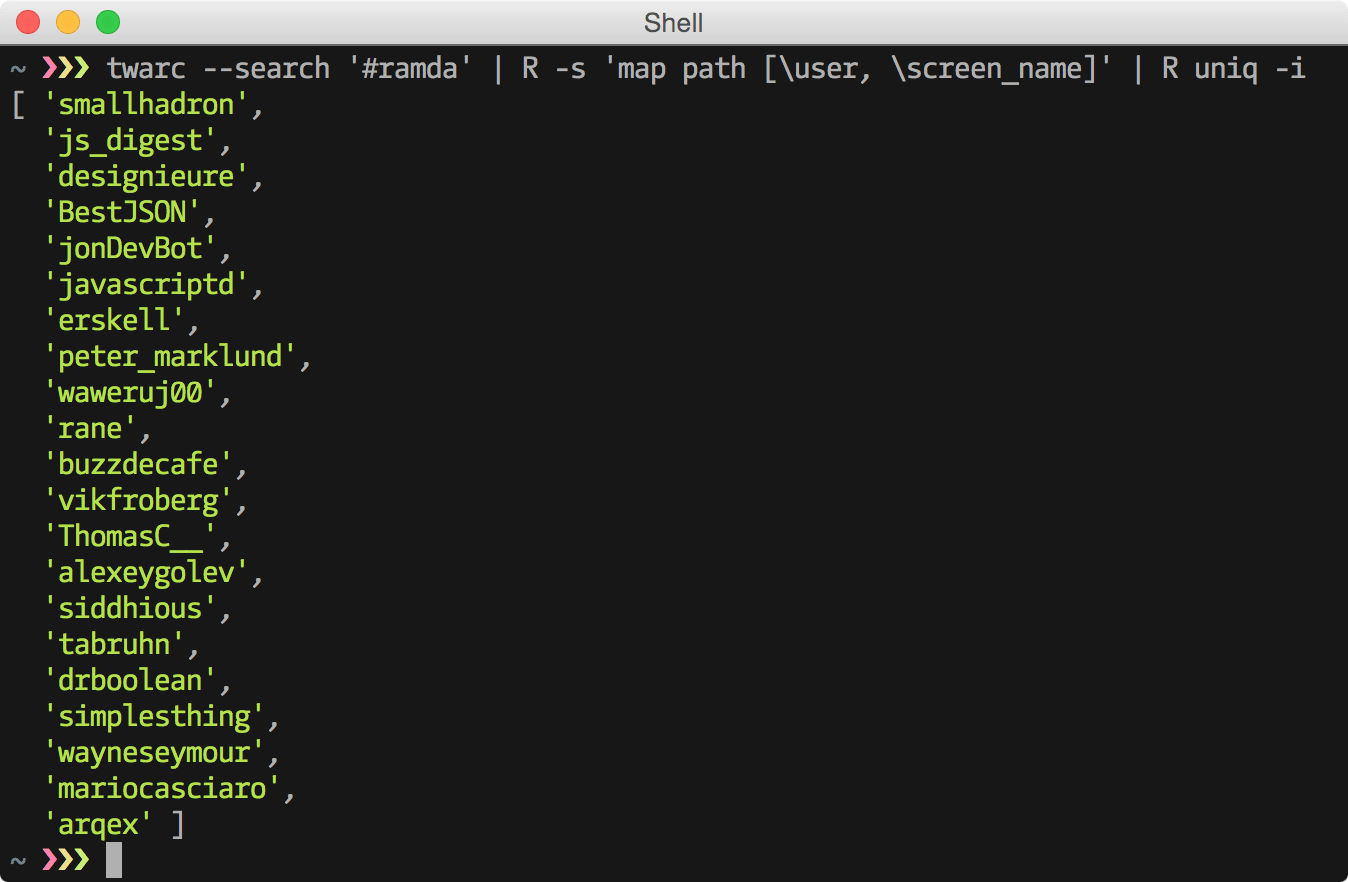{kind=link}
twarc.py --search '#ramda' | R --slurp -p 'map path [\user, \screen_name]' uniqHTTP status codes per minute for last hour:
graphite -t "summarize(stats_counts.status_codes.*, '1min', 'sum', false)" -f '-1h' -o json | \
R 'map evolve datapoints: (map head) >> require \sparkline' \
'sort-by prop \target' -o table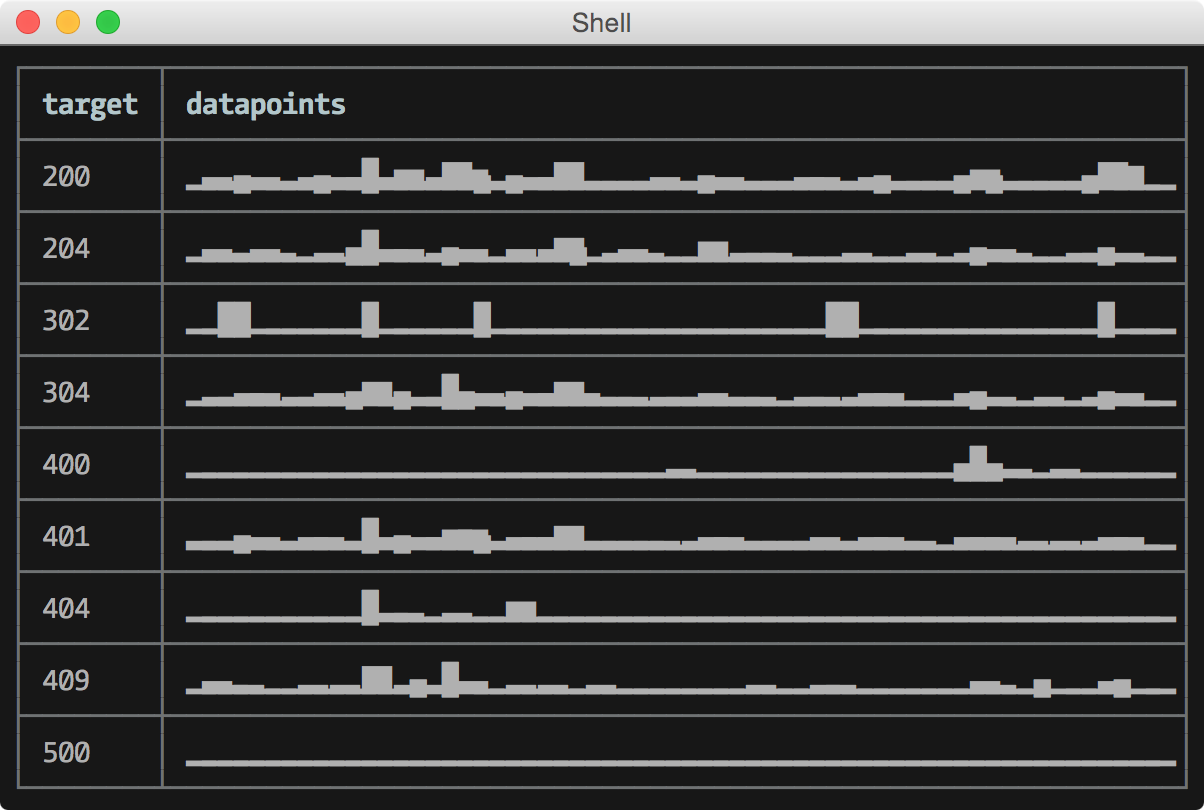
$ cat <<EOF > text
"foo bar"
"test lol"
"hello world"
EOF
$ cat text | R --compact --slurp identity
["foo bar","test lol","hello world"]Solution to the credit card JSON to CSV challenge using --output-type csv
#!/usr/bin/env bash
data_url=https://gist.githubusercontent.com/jorin-vogel/7f19ce95a9a842956358/raw/e319340c2f6691f9cc8d8cc57ed532b5093e3619/data.json
curl $data_url | R \
'filter where creditcard: (!= null)' `# filter out those who don't have credit card` \
'project [\name, \creditcard]' `# pick name and creditcard fields from all objects` \
-o csv > `date "+%Y%m%d"`.csv `# print output as csv to a file named as the current date` cat countries.json | R 'take 3' -o table
┌───────────────┬──────┐
│ name │ code │
├───────────────┼──────┤
│ Afghanistan │ AF │
├───────────────┼──────┤
│ Åland Islands │ AX │
├───────────────┼──────┤
│ Albania │ AL │
└───────────────┴──────┘Ramda functions used:
take
Data: countries.json
npm ls --json | R 'prop \dependencies' 'map-obj prop \version' -o table --compact
┌───────────────┬────────┐
│ JSONStream │ 1.0.4 │
│ treis │ 2.3.9 │
│ ramda │ 0.14.0 │
│ livescript │ 1.4.0 │
│ cli-table │ 0.3.1 │
└───────────────┴────────┘With hyperscript installed to $HOME/node_modules and
config that exports it as h.
exports.h = require('hyperscript')$ cat <<EOF > shopping.txt
milk
cheese
peanuts
EOF
$ cat shopping.txt | R \
-rR --slurp `# read raw input into a list` \
'map (h \li.item, _)' `# apply <li class="item"> into each item` \
'h \ul#list, _' `# wrap list inside <ul id="list">` \
'.outer-HTML' `# finally, grab the HTML`<ul id="list">
<li class="item">milk</li>
<li class="item">cheese</li>
<li class="item">peanuts</li>
</ul>Reason for underscores (e.g. h \ul, _) is that hyperscript API is not
curried (and can't be because it's variadic). We need to explicitly state
that this function is waiting for one more argument.
$ cat shout.js
var R = require('ramda');
module.exports = R.pipe(R.toUpper, R.add(R.__, '!'));
$ echo -n 'hello world' | R -i raw --file shout.js
"HELLO WORLD!"For more examples, see the Cookbook.
All of Ramda's functions are available, and also:
| function | signature | description |
|---|---|---|
id |
a → a |
Alias to R.identity |
treis |
treis(name?, fn) |
Observe functions' input and output values |
flat |
* → Object |
Flatten a deep structure into a shallow object |
readFile |
filePath → String |
Read a file as string |
lines |
String → [String] |
Split a string into lines |
words |
String → [String] |
Split a string into words |
unlines |
[String] → String |
Join a list of lines into a string |
unwords |
[String] → String |
Join a list of words into a string |
Path: $HOME/.config/ramda-cli.{js,ls}
The purpose of a global config file is to carry functions you might find useful to have around. The functions it exports in an object are made available.
Packages installed to $HOME/node_modules can used with require().
$ date -u +"%Y-%m-%dT%H:%M:%SZ" | R -r 'require \timeago'
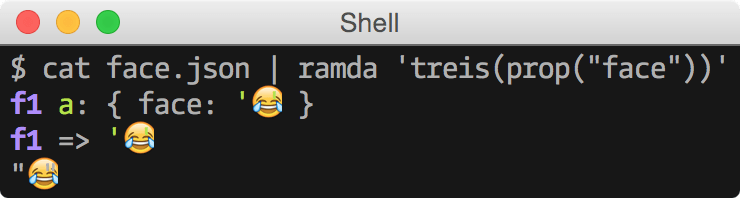
less than a minute agoYou can turn on the debug output with -v, --verbose flag.
ramda-cli 'R.sum' +0ms input code
ramda-cli 'R.sum;' +14ms compiled code
ramda-cli [Function: f1] +4ms evaluated totreis is available for debugging individual functions in the
pipeline:
LiveScript is a language which compiles to JavaScript. It has a straightforward mapping to JavaScript and allows you to write expressive code devoid of repetitive boilerplate.
- Function composition operators
.,<<,>> - Implicit access
(.length) - Operators as functions
(+ 1)
See also: Essential LiveScript for ramda-cli
--