research_computing
This resource contains teaching materials for an overview course in research computing.
The target audience is primarily college students, particularly graduate students, who conduct academic or scientific research. The information will also be useful for working professionals.
The main goal of this course is to help students improve their technical readiness for engaging in the increasingly data-centric work that they face in their degree programs, in their related research, and in their future professional and research practice. Students will become acquainted with key concepts in research computing and data management, including overviews of systems analysis techniques, data security and integrity, and database tools, among others.
At the end of this course students should be able to:
-
Analyze requirements for management of data in different situations and projects.
-
Choose appropriate technical tools and techniques to support that data management.
-
Identify hazards and pitfalls in data-related projects.
-
Identify factors that affect performance in the collection and preparation of data for analysis.
-
Describe the core technologies most frequently employed in large-scale research data management.
The files hosted in the repository consist of the presentation slides in Markdown format as well as transcripts to go with those slides. The transcripts are posted as wiki pages in ASCIIDoc format and are also offered as PDF and Epub eBooks.
Thanks to the following people who have contributed to this resource (in no particular order):
Brian High, Jim Hogan, John Yocum, Elliot Norwood, and Lianne Sheppard
Copyright © The Research Computing Team. This information is provided for educational purposes only. See LICENSE for more information. Creative Commons Attribution 4.0 International Public License.
Your research computing experience will involve using and developing information systems. We will take a quick look at the various components, types, and development models of these systems.
The primary components of an information system are hardware, software, data, and people — the most important component of all! Why? Because systems are designed and built by people for people. If people don’t use them, or they do not serve the people’s needs, then they are worthless! Today we will take a closer look at how information systems are designed to help us.
Source: Wikipedia, CC BY-SA 3.0

The physical machinery of a computer system is called its hardware. Of course, this means the computer itself, its chassis and the parts inside it, including its core integrated circuit known as the central processing unit (CPU), as well as its memory, called "RAM" or Random Access Memory, and any internal storage devices like hard disk drives (HDD) and solid state devices (SSD).
Accessories or [peripherals(http://en.wikipedia.org/wiki/Peripheral) are the devices you plug into the computer, mostly for input and output.
Networking equipment includes all of the devices that allow your computer to communicate with other systems. Examples are the network cables and the boxes they connect to, such as routers, switches, hubs, wireless access points, and modems.
Software is the name for the instructions we give to computing devices to tell them what to do. Software is "soft" because the instructions are not physical entities like hardware devices. The instructions may be stored on physical media like a hard disk or USB thumbrive, just as a cooking recipe may be written on a piece of paper or printed in a book. However, the recipe itself is just a conceptual model of how to perform a task. Likewise, a software program is essentially just a list of instructions (or a logical model that issues instructions) for the execution of a set of desired computing operations.
As you use a computer, the software instructions that are executed on your behalf by the CPU, such as programs and apps, are called application software. Applications are the programs that serve a specific purpose for a computer user or are to be used for completing certain tasks, such as exploring the Internet, editing a text document, or working with data.
Applications run within a overall software environment called the operating system (OS).
Notable examples are the familiar Microsoft Windows, OS X, iOS, Android and Linux operating systems.
An operating system also has a kernel, which is the central software program that manages the data exchange between the CPU and the other components within a computer. The kernel communicates with those components using device drivers, which are small programs that provide a software interface to the hardware. Devices that contain integrated circuits of their own may store software in firmware that allows updates through a procedure called flashing. The computing system will also contain utility software such as configuration and management tools, plus shared software libraries used by both applications and system software.
Data refers to all of the information in the system. It may be stored as raw (unprocessed) values, or may be in the form of summary tables, plots, written documents, photographs, music, videos, or just about any other form of information which can be digitized. Data can be at rest, in which case it will probably be saved in some sort of file or may just be occupying some bits of system memory. Data may also be in motion, flowing between the components within a single computer system or between nodes of a network. As the boundaries of an information system will usually extend beyond computer systems, data may also reside on scraps of paper or may only exist in a person’s mind in the form of a thought or idea, waiting to be communicated to the rest of the information system.
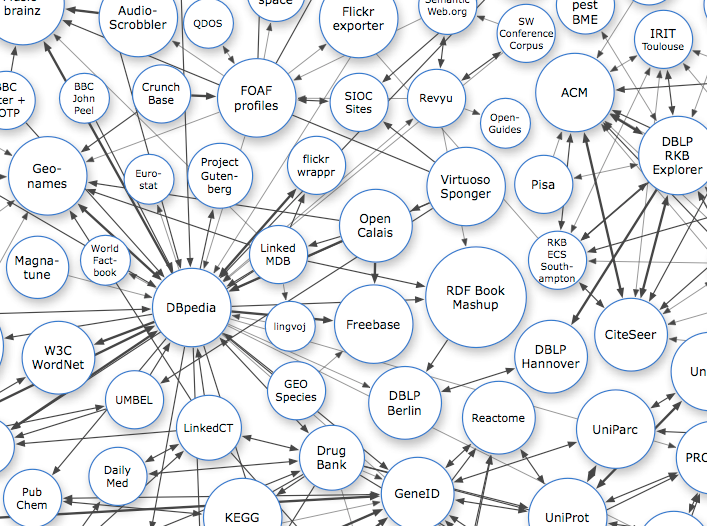
Source: Linked Data, CC BY-SA 3.0
People are an integral part of the system. We design it, build it, use it, maintain it, and adapt it to new uses. Our systems should serve us, not the other way around. Every aspect of the system should be designed to serve people’s needs optimally. But our needs vary, and so we need various types of systems.

Most of us are very familiar search information systems like web search engines, such as Google Search, but many sites use domain-specific search engines like PubMed.
Spatial information systems in the form of Geographic information system (GIS) have become increasingly important in recent years. ArcGIS has dominated this field, with the free and open QGIS gaining in popularity.
Global information systems (GLIS) are those either developed or used in a global context. Public health examples include global health databases such as the UNHCR Statistics & Operational Data Portals and the WHO’s Global Health Observatory (GHO).
Enterprise systems are comprehensive organization-wide applications used for Enterprise Resource Planning (ERP).
Expert systems support such specialty domains as diagnosis, forecasting, and delivery scheduling. They use artificial intelligence to apply knowledge and reasoning in order to solve complex problems.
Office automation systems refer to systems which support the everyday business operations of an organization. Business Process Automation (BPA) uses these systems to improve efficiency by streamlining routine activities.
Personal information systems help people manage their individual communications, calendaring, note-taking, diet, and fitness.
Source: Wikipedia, CC BY-SA 3.0
Developers undertake the software development process using several different approaches. Let’s take a look at a few of the most popular models.

Here is a short list of common development models. We have provided links from each of these to relevant Wikipedia pages. You are encouraged to read more about them. We’ll just go through the list quickly to give you a rough idea of the differences between them.
The Systems development life cycle (SDLC) is the classic model. It involves lots of up-front planning and is risk averse.
Waterfall development is another and "old school" favorite, It’s like the SDLC but does not offer any sort of feedback loop.
Prototyping is a useful technique for many models. Good when a small-scale experiment can prove an idea without risking heavy investment.
Iterative and incremental development might evoke the image of "baby steps" or the notion of "try, try, again". There is a central loop, between initial planning and final deployment, which repeats as needed. Like prototyping, it is a technique which can be used in other models.
Likewise, Spiral development is meant to address evolving requirements through cycles of repeated analysis and design, getting closer and closer to the desired product. The idea is that the entire process is repeated over and over until you are finally satisfied.
Rapid application development (RAD) focuses on development more than up-front planning.
Agile development is a more evolved form of RAD, with more of a focus on user engagement, and gaining wide popularity.
Code and fix sounds like what it is — cowboy coding — what most lone programmers do, and what might seem most familiar to you as a scientific researcher. This can be quick for easy projects, but can be very inefficient and expensive for larger projects, due to insufficient planning.
They are all useful methods, though, some more generally than others. The approach you take should depend upon your situation.
We’ll look more closely at three of these right now.
Source: Wikipedia, CC BY-SA 3.0
Since information systems are so complex, it is very helpful to follow a standard development model to make sure you take care of all of the little details without missing any.

For years, the standard development model was known as the SDLC, or Systems Development Life Cycle. It works well for large, complex, expensive projects, but can be scaled down as needed. Many of its phases are used in the other models as well. Let’s take a quick look at them.
Systems development life cycle (SDLC) phases:
-
-
There is a focus on careful planning before any design or coding takes place. The feasibility study explores your options and gaining approval from stakeholders.
-
-
-
Analysis includes a detailed study of the current system and clearly identifying requirements before designing a new system.
-
-
-
Once you have thoroughly defined the requirements, you can begin to model the new system.
-
-
-
Implementation is where the hardware assembly, software coding, testing, and deployment takes place.
-
-
-
Maintenance may sound boring, but it is essential to ensure that the project is an overall success.
-
The main idea is that systems development is a cycle — a continual process. You need to allow for maintenance, updates, and new features. The use and upkeep of the system provides feedback which goes into planning the next version.
We will spend more time on the SDLC and its early phases in a separate module.
Source: Wikipedia, CC BY-SA 3.0
A related model is the Waterfall model. It has basically same same steps as the SDLC, but visualizes them as cascading stair-steps instead of a circle.

It’s basically similar to the SDLC, but without the feedback loop. There are cascading stair-steps, where one phase leads to another and the output of one phase becomes sthe input of another. Its came from manufactoring where after-the-fact changes are expensive or impossible.
Source: Wikipedia, CC BY-SA 3.0
The Agile model is a newer, but very popular, especially among smaller teams within budding organizations. Hallmarks of this model include methods such as pair programming, test-driven development, and frequent product releases.

Smaller teams that can meet regularly, ideally face-to-face. Working in pairs, with one person coding and other helping "over the shoulder". After you identify use cases, then you write tests and then build the system to pass the tests. By developing an automated test and build system, releases can be pushed out quickly and more often.
Source: Wikipedia, CC BY-SA 3.0
Information systems vary in the openness of the their implementations, in terms of both interoperability standards and specific design details.
You can have open systems and standards, source), where the technical specifications are publicly available. Different organizations may implement them in their own way, yet still maintain interoperability with other implementations.
Or systems be closed, or proprietary, where an organization keeps the details to itself, making it more difficult for competitors to inter-operate. While this may provide a competitive advantage for the producer it contributes to what is called vendor lock-in, where a consumer becomes dependent on the vendor, unable to switch to another due to the high costs and disruption.
These interoperability aspects will include file formats, communications protocols, security and encryption.
Source: Wikipedia, CC BY-SA 3.0
All of those are important when you are collaborating, sharing data and files with others, who might be using different platforms.
By using transparent systems, you not only increase your ease of communication and collaboration, you also contribute to openness in a broader, social context.
Information transparency supports openness in:
We have provided links to several popular movements which are working to increase openness and transparency in various aspects of society. You are encouraged to spend some time learning about these trends.
So, if you want the benefits of openness in your work and more freedom to make changes, consider building your information infrastructure with open technologies.
Source: Wikipedia, CC BY-SA 3.0
As an example, we have assembled a transparent information system to create and support this course.
We have developed the course transparently, using an open content review process where students, staff and faculty look at the materials and evaluate them to determine whether or not they best meet the course goals.
We have an open content license, the Creative Commons Attribution Share-Alike CC BY-SA 4.0 International license.
We have open development where our source is freely and publicly available on GitHub).
We are using open file formats (Markdown, HTML, CSS, PNG, AsciiDoc, PDF), open source tools tools (RStudio, Git, Redmine, Canvas, Linux, Bash) and open communications protocol standards (HTTP/HTTPS).
As you take part in this course, and provide feedback which will go toward improving it, we thank you for contributing!
We hope that this brief overview of Information Systems has given you a more clear picture of the what they are and how they are built.
For more information, please read the related sections in the Computing Basics Wiki, particularly, the pages on hardware and software.
In the next module, we will take a closer look at requirements gathering and systems analysis, two of the most important topics of this course.
Investing time and money into a computer or information system without a clear course of action can be expensive and wasteful. By taking some time to fully consider the issue at hand and pursue a disciplined approach to finding a practical solution, you greatly increase your odds of success and decrease costs. We call this process Systems Analysis.
Systems analysis is an important part of an overall approach to systems development.
The life of an information system follows a cycle. The classic development model is called the Systems Development Life Cycle, or SDLC.
The Planning phase defines the primary issue (problem or goal) and performs a feasibility study. Here, you clarify the project scope, compare your best options, and come up with a plan.
The Analysis phase focusses on the issue, defined previously, and studies its role in the current (or proposed) system. The system is explored, piece by piece, in light of the project goals, to determine system requirements.
In the Design phase, a detailed model of the proposed system is created. Various components or modules address each of the requirements identified earlier.
During the Implementation phase, a working system is built from the design and put into use.
The Maintenance phase includes ongoing updates and evaluation. As changes are needed, the cycle repeats with more planning, analysis, and so on.
Source: Wikipedia, CC BY-SA 3.0
We will take a closer look at the systems analysis phase next.
Essentially, in Systems analysis we answer the question, "What will you need to reach your goal?" In other words, "What are your requirements?"
A primary goal of this course is to help you develop your skills in requirements analysis.
Systems analysis helps you clarify your project needs and plan ahead in order to obtain and allocate critical resources.
The main idea here is …
If you don’t know what you need, how can you ask for it?
After completing an initial feasibility study to "determine if creating a new or improved system is a viable solution", proposing the project, and gaining approval from stakeholders, you may then conduct a systems analysis.
Systems analysis will involve "breaking down the system in different pieces to analyze the situation, analyzing project goals, breaking down what needs to be created and attempting to engage users so that definite requirements can be defined."
Source: Wikipedia, CC BY-SA 3.0
So, what, exactly, is "Systems Analysis"?
-
"A system is a set of interacting or interdependent components"1
-
Analysis means "to take apart"2
Lonnie D. Bentley, author of Systems Analysis and Design for the Global Enterprise, writes:
Systems analysis is a problem solving technique that decomposes a system into its component pieces for the purpose of the studying how well those component parts work and interact to accomplish their purpose.3
We will accomplish this analysis by working through a series of five phases.
Notes:
-
Systems Analysis and Design for the Global Enterprise 7th ed., by Lonnie D. Bentley, as quoted by Wikipedia
Systems Analysis has its own series of phases. We will look at each of these one by one.

During Scope definition, we establish our system boundaries. In our Problem analysis phase, we identify the symptoms and causes. Our Requirements analysis determines our system goals. The Logical design phase models relationships within the system. And our Decision analysis evaluates the various alternatives.
Source: Wikipedia, CC BY-SA 3.0
So, do we mean by scope?1
Scope involves getting information required to start a project, and the features the product would need to have in order to meet its stakeholders requirements.
Put another way, project scope defines the work to be done whereas product scope is concerned with the desired features and functions.
By being careful to define scope early on, we can be more watchful for scope creep.2
Scope creep is […] the incremental expansion of the scope of a project […], while nevertheless failing to adjust the schedule and budget.
Notes:
-
Ibid.
Problem analysis is critical. When we say, problem, we can also think goal, research question, or issue. If you don’t get this right, you can waste a lot of time and money solving the wrong problem or address a non-issue.
We can summarize the key points of problem analysis (with some help from Jenette Nagy of Kansas University) as:
-
Define and clarify the problem (or issue)
-
What exactly are we trying to solve?
-
-
Determine the problem’s importance
-
How much does it matter?
-
-
Assess the feasibility of solving the problem
-
Do we have the resources we need?
-
-
Consider any negative impacts (unintended consequences)
-
What could go wrong?
-
-
Prioritize problems to solve (bottlenecks? low-hanging fruit?)
-
What are the most critical issues?
-
-
Answer: what, why, who, when, where, and how much?
-
Drill down into the problem with all kinds of questions to expose dependencies.
-
-
Find causes (especially root cause) and symptoms (effects)
-
What is really going on here?
-
There are several methods of root cause analysis, but one simple one is …
"Ask Why Five Times"
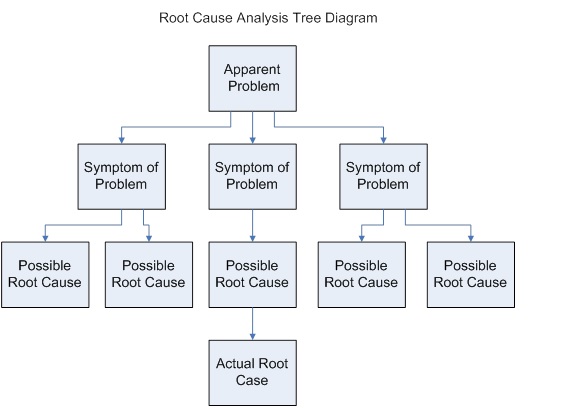
… where you keep asking "Why? But, why? But, Why?" over and over again until there is a clear root cause that you can actually do something about.
A real example is mentioned in Ask Why 5 Times, Business Analysis Guidebook/Root Cause Analysis (wikibooks.org), where the US National Park Service was able to slow the rate of deterioration of the Jefferson memorial simply by changing the lighting schedule.
This method may also be used in Requirements Analysis.
-
System and project requirements
EAR Analysis is all about listening.
Gather requirements by interviewing stakeholders. Observe how people currently do their work or use the system. Make sure the requirements are detailed, clear, unambigious, and comprehensive. Document the requirements as a list, in diagrams, or narratives.
As an example, in Spring 2014, we held a meeting with our graduate students and asked them about what sort of computing needs they had. We had a discussion, listened to what they had to say, summarized the main concerns, and documented them.
-
Further elucidate Measurable goals
By continuing to ask questions like "Why? … Why? … Why? …", get more specific until the goals become quantifiable. Measured goals are easier to meet since you can measure your progress in achieving them.
Mission objectives determine the goals. Compare the stated goals against mission objectives to produce a small set of critical, measured goals.
-
Output: Requirements specification
This document will be used in the logical design phase to model the relationships within the system. So, it should be clear and thorough. The more specific and unambiguous this specification is, the easier it will be to design the system to meet the requirements.
One way to be more clear is to organize the requirements by type.
Source: Wikipedia, CC BY-SA 3.0
You may categorize requirements according to several important types:
Operational requirements are the utility, effectiveness, and deployment needs, with repect to practical use of the system within the overall operation. These are the customer Requirements.
Functional requirements are specific things the system must do.
Non-functional requirements are specific things the system must provide.
Architectural requirements define how the system must be structured, in other words, how the components must interrelate.
Behavioral requirements describe how users and other systems will interact with the system and how the system will respond.
Performance requirements define how well the systems needs to do things, measured in terms of quantity, quality, coverage, timeliness or readiness.
While there are other ways to group requirements, these are the most significant categories.
Another way to make requirements clear is through requirements modeling. Here is an example of modeling behavioral requirements with a Use Case Diagram.
Survey Data System
The behavioral requirements are stated in role goal format.
-
Researcher uploads survey.
-
Subject takes survey.
-
Subject uploads results.
-
Researcher downloads results.
Gramatically speaking, the role is the subject and the goal is stated as a verb and its object. Each of these requirements forms the basis of a use case.
The Use Case Diagram is a standard means of showing these requirements pictorially.
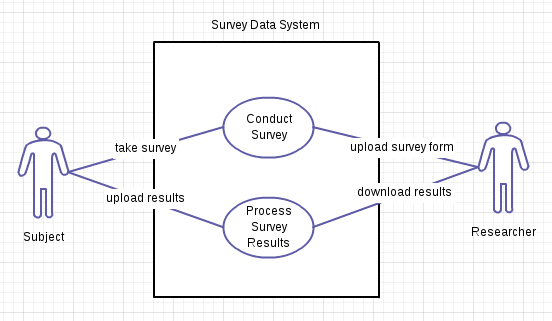
Source: Brian High, Github, Public Domain, CC0 1.0
Here, human actors are depicted as stick figures. These are the roles. The goal is the line connecting the role to a system activity or function, shown as an oval. In this example, the system is drawn as a box with the actors outside the box. The reason is that the system’s product scope was defined to be the electronic data system. The human actors interact with that system. The information flowing to and from an actor, as well as data flows within a system, will be modeled in the logical design.
Once system behaviours have been modeled from the perspective of user interaction, we can begin to model the internal workings of the system with the logical design. The logical part means that this is an abstract representation of the system. Therefore, the system is modeled in terms of abstractions such as data flows, entities, and relationships. We model how the system will satisfy function requirements such as inputs and outputs. To make the abstract more concrete, we make use of Graphical modeling techniques to produce graphics such as the Data Flow Diagram (DFD) and Entity Relationship Diagram (ERD).
Source: Wikipedia, CC BY-SA 3.0
For example, let’s consider a systems which records the playlists of musical performances at a local pub. You will want to store which artist performs which song. The relationship between an artist and a song can be shown in a simple Entity Relationship Diagram. We start with the behavioral use case written as Artist performs Song. Then, using a standard set of symbols, we can produce this diagram.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The boxes represent entities and the line connecting them is the relationship. Here, the symbols indicate that there is a one-to-many relationship. This diagram is saying that exactly one artist performs one or more songs, (or doesn’t perform any).
Since this "system" describes only solo performers, you would want to model it differently to include groups of artists that perform more than one song. You would want a many-to-many relationship as well as other entities to represent the musical groups. Since there will by many performances, you will also want an entity to represent the performances.
The value of this type of diagram is that complex relationships can be mapped to a great level of detail. In fact, they can be used to automatically generate database schemas.
Source: Bignose, Wikimedia, Public Domain
{kind=link}
Several examples of these diagrams can be found in the Systems Analysis and Design turorial.
This https://github.com/brianhigh/data-workshop/blob/master/Systems_Analysis_and_Design.md1 (PDF, HTML, MP4) provides several examples from a fictitious public health research study.
You will find several other real-world examples from actual public health research projects in that course repository.
Notes:
-
See also: Data Management, UW Canvas.
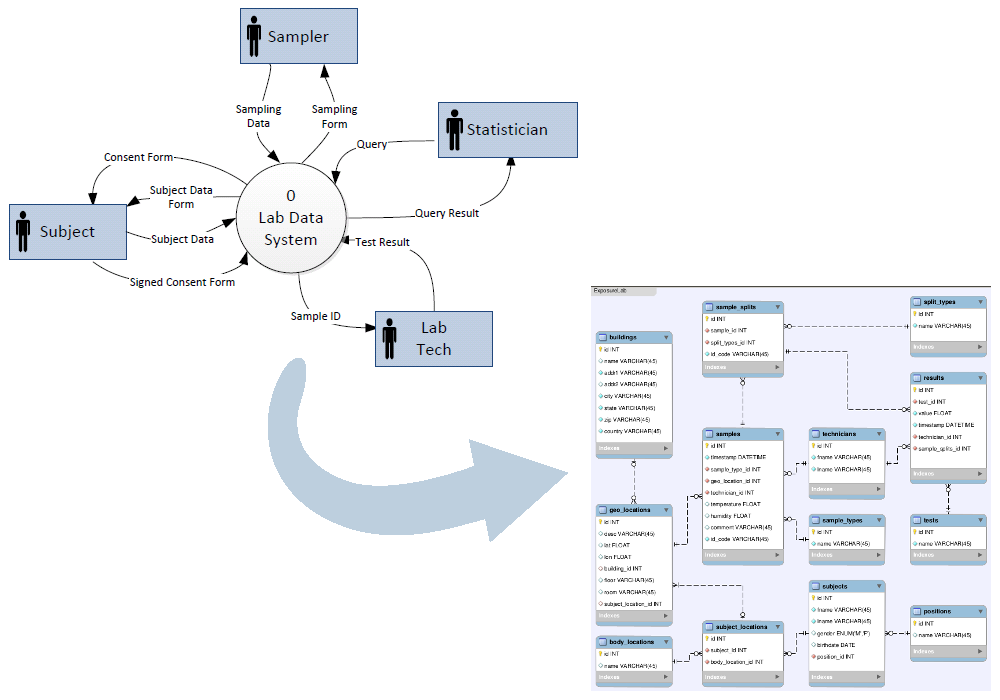
Source: Brian High, Github, Public Domain, CC0 1.0
{kind=link}
These models and diagrams will help you make a very important decision. Before you go further in the system design process, you need to decide whether to buy a system or build one. Or you may consider building a system of components, some of which you might buy and others might be custom built. You will want to come up with a few of the best alternatives and present them to your stakeholders. In your case that might be your lab manager, principal investigator, or funding agency.
Your presentation will also include a
Decision analysis to
weigh
the pros and cons of the various options against the requirements in
order to help the stakeholders with their decision. You should conclude
your analysis with a recommendation of your top choice and explain why
this choice is the most compelling. Then you will want to get a
decision, and the approval to continue, before you invest any more time
on further analysis.
The system development life cycle (SDLC) continues on to other phases, which we do not have time to cover here. However, we hope that this glimpse at the systems analysis phase has demonstrated the value of this approach in gathering and clarifying requirements that can be used to design and build an information system.
Source: Wikipedia, CC BY-SA 3.0
The technology world suffers from excessive use of buzzwords (words associated with hype, or "buzz"). Someone coins a term to describe a looming problem or seemingly magical solution. The term or phrase gains momentum with media exposure, and soon you see it everywhere.
Yet, often, people are unsure about what the term actually means or if it really matters. Relentless exposure to the ill-defined hype results in the modern malady known as buzzword fatigue. We will help clarify a few of them by peering through the clouds.
The notion of "the cloud" in computing comes from the use of a cloud symbol in network diagrams. The cloud symbol represents the "rest of the network" or the part of the network lying outside of your organization or your network diagram. Usually, this "outside" means the Internet. So, cloud computing is using servers outside of your organization, often over the Internet. As you may realize, this is not really that new, but more of a increasing trend.
You now have several competing services to choose from that present vast computing resources as a "commodity", like electricity. Computing resources may be rented on an as-needed basis to scale to meet varying demand. You only pay for the resources you use. You can even run your own virtual machine in the cloud, through the wonders of virtualization, a buzzword with its own family of buzzwords.
So, the attraction is not having to buy, house, and maintain hardware, networking, and in some cases, software. The potential downsides all relate to "lack of control".
-
Security: You have to trust the cloud service provider with your data.
-
Support: You have to go through the cloud service provider if something isn’t working the way you expect it to work.
-
Availability: You have to depend on your network connection to the cloud service, in terms of both reliability and performance.
Some people consider "the cloud" as just another name for "the network" or "not my computer". In any case, the notion of cloud computing involves some degree of "outsourcing" of computing resources and accessing those resources through the network.
Big Data is a term applied to very large amounts of data. Search online and you will find many different ways to define this. For our purposes, we will use the broad definition of: a collection of data so large that its largeness creates significant processing problems, but can yield value not found in smaller data sets.
Very large data sets are enabled by very low cost storage. For example, instead of sampling every hour or even every minute, you can sample every second because you have the space to store all of the resultant data.
Data mining is looking for patterns in a very large data set. Imagine trying to find the "needles in a haystack" of huge volumes of data. Much of this is enabled by very low cost, parallel computing.
The limiting factor here becomes the network because you can only move so much data in a given time frame. Here you may turn to cloud computing for massively parallel processing power.
Data science is a term generally used to refer to statistical data analysis and the presentation of results, often visually. In particular, some people use "data science" to mean the analysis of big data using techniques such as data mining to produce stunning visualizations. The publishing of such data products is termed data journalism. Of course, the analysis may make use of cloud computing in terms of cloud storage and processing.
This page was copied from the Computing Basics Wiki. Copyright © The Computing Basics Team. This information is provided for educational purposes only. See LICENSE for more information. Creative Commons Attribution 4.0 International Public License.