Duolikun Danier, Mehmet Aygün, Changjian Li, Hakan Bilen, Oisin Mac Aodha
University of Edinburgh



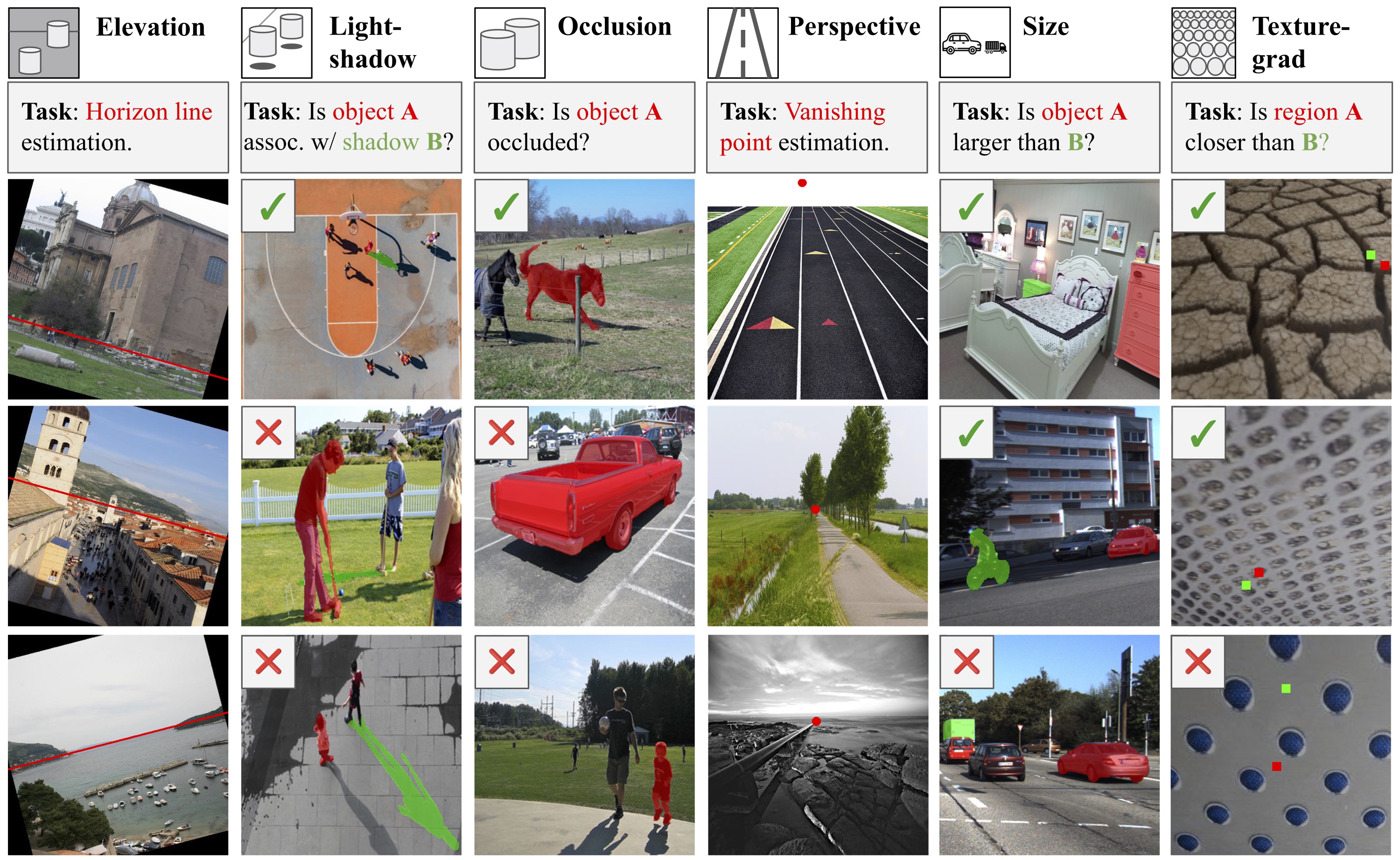
TL;DR: We developed a benchmark, DepthCues, to evaluate human-like monocular depth cues in large vision models, showing their emergence in more recent larger models.
- Environment Setup
- Downloading Data
- Probing on DepthCues
- Fine-tuning on DepthCues
- Acknowledgements
- BibTeX
To install the conda environment, run
conda env create -f environment.yaml
Note: when cloning this repo also remember to clone the submodules.
Download the (including images and annotations) from here, following the instructions provided on the page. The data folders should look like:
<your data dir>/
└── elevation_v1/
└── images/
└── train_data.pkl
└── val_data.pkl
└── test_data.pkl
└── lightshadow_v1/
└── images/
└── train_annotations.pkl
└── val_annotations.pkl
└── test_annotations.pkl
└── occlusion_v4/
└── images_BSDS/
└── images_COCO/
└── train_data.pkl
└── val_data.pkl
└── test_data.pkl
└── perspective_v1/
└── images/
└── train_val_test_split.json
└── size_v2/
└── images_indoor/
└── images_outdoor/
└── train_data_indoor.pkl
└── train_data_outdoor.pkl
└── val_data_indoor.pkl
└── val_data_outdoor.pkl
└── test_data_indoor.pkl
└── test_data_outdoor.pkl
└── texturegrad_v1/
└── images/
└── train_data.pkl
└── val_data.pkl
└── test_data.pkl
Follow the instructions here to download and pre-process the dataset.
Download the dataset from here, and our annotation files from here.
The configs used to probe all 20 vision models on all tasks are provided in configs. Each config specifies
- the task (data, loss, metric, probe training parameters),
- the vision backbone (model and its data transform)
- feature to evaluate (feature type, layer), where layer
$\in [0,$ num layers of backbone$)$ . - the probe model, whose input dimension depends on backbone and feature type, and output dimension depends on the task.
The configs provided correspond to those used to probe the best layers of the models on each task. For example, this config probes the 11th (which is the final) layer of DINOv2-b14 on the elevation task, using an attentive probe that has a two-dimensional output (corresponding to the two regression targets defining the horizon line).
Note: you need to change the data dirs in the configs.
For most of the models, the model backbone classes will download the checkpoints (on the first run) and loads them directly. For DepthAnythingv2, please download the checkpoint (the "base" version) from the official repo and save it to submodules/depth_anything_v2/checkpoints/depth_anything_v2_vitb.pth
To train the probe in this setting, run
python run_probe.py -b configs/elevation/dinov2-b14.yaml -n <run_name> --gpu_id 0
where run_name is an optional name given to this run. This will create a log folder logs/elevation_v1/dinov2-b14/patch_attn/<run_name>/, in which the config will be written, and training results of the probe will be saved. Random seeds can be specified via -s argument. For the paper, we used the random seeds 23, 1, 2, 3, 4.
If you would like to customize the probing config, instead of creating a new config, it's also possible to pass in the configs via command line arguments, and these will overwrite what's specified in the config. For example, to probe the first layer of DINOv2 on elevation using concatenated class and patch tokens, while also specifying a different training data dir, you can run
python python run_probe.py -b configs/elevation/dinov2-b14.yaml -n <run_name> --gpu_id 0 --feature_extractor_config.params.layer=0 --feature_extractor_config.params.feat_type=cls-patch --data_config.train.params.data_path=<path/to/elevation_v1>
To test the trained probe, run (omit run_name if not specified above).
python run_probe.py -b logs/elevation_v1/dinov2-b14/patch_attn/<run_name>/config.yaml -t --gpu_id 0
We also provide configs used for the fine-tuning experiments. To fine-tune DINOv2 on DepthCues, run
python run_finetune.py -b configs/finetune/dinov2_lora/all_cues.yaml --gpu_id 0 -n <run_name>
This will create a log folder logs_finetune/finetune/dinov2lora-b14/all_cues/<run_name>/, where the fine-tuning config and model checkpoints will be saved.
The fine-tuned model can then be probed as described above. We also provide the config files used to probe the fine-tuned models on NYUv2 and DIW depth estimation. For example, if you used the provided fine-tuning config to fine-tune DINOv2, then this config can be used directly to probe the fine-tuned model on NYUv2. Note that you may need to update the checkpoint location if you specified run_name when fine-tuning.
This repository is adapted from VPT and Probe3D. We thank the authors for open-sourcing their code.
If you find our work helpful, please consider citing:
@article{danier2024depthcues,
title = {DepthCues: Evaluating Monocular Depth Perception in Large Vision Models},
author = {Danier, Duolikun and Aygün, Mehmet and Li, Changjian and Bilen, Hakan and Mac Aodha, Oisin},
journal = {CVPR},
year = {2025},
}