-
Notifications
You must be signed in to change notification settings - Fork 327
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
ec4f548
commit 7df6bae
Showing
3 changed files
with
252 additions
and
2 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,221 @@ | ||
| <div align="center"> | ||
|
|
||
| [中文简体](../../README.md) | [English](../en/README_EN.md) | **Português (Brasil)** | ||
|
|
||
| </div> | ||
|
|
||
| --- | ||
|
|
||
| <div align="center"> | ||
|
|
||
| [👑 Apoie o projeto](https://github.com/jianchang512/pyvideotrans/blob/main/docs/pt-BR/About_pt-BR.md) | [Discord](https://discord.gg/SyT6GEwkJS) | ||
|
|
||
| </div> | ||
|
|
||
| --- | ||
|
|
||
|
|
||
| # Ferramenta de Transcrição de Fala para Texto (stt) | ||
|
|
||
| Transcreva localmente seus áudios e vídeos com esta ferramenta offline. Baseada no modelo open source fast-whisper, ela converte a fala humana em texto, exportando em formatos json, srt com timestamps e texto puro. Após implantada, substitui com precisão similar serviços de reconhecimento de fala online como OpenAI ou Baidu. | ||
|
|
||
| **Recursos:** | ||
|
|
||
| * **Totalmente offline:** Implante em redes internas. | ||
| * **Modelos flexíveis:** O fast-whisper oferece versões base/small/medium/large-v3. A qualidade aumenta do base para large-v3, mas exige mais recursos. Baixe e descompacte outros modelos na pasta `models`. | ||
| * **Aceleração CUDA:** Se tiver uma GPU Nvidia e o ambiente CUDA configurado, use a aceleração CUDA automaticamente. | ||
|
|
||
| ## 📢 **Patrocinador** | ||
|
|
||
| [](https://302.ai/) | ||
|
|
||
| **302.AI: A Plataforma de IA Sob Demanda** | ||
|
|
||
| A 302.AI é a plataforma que reúne as melhores IAs do mundo em um só lugar, com pagamento sob demanda e sem mensalidades. Experimente diversas ferramentas de IA sem barreiras de entrada! | ||
|
|
||
| **Benefícios:** | ||
|
|
||
| * **Funcionalidades completas:** Chat de IA, geração de imagens e vídeos, processamento de imagens e muito mais. | ||
| * **Fácil de usar:** Robôs, ferramentas e APIs para atender a todos os níveis de usuário. | ||
| * **Pagamento sob demanda:** Sem planos mensais, sem barreiras para produtos, pague apenas pelo que usar. Seu saldo nunca expira! | ||
| * **Separação de administradores e usuários:** Especialistas em IA configuram tudo para você, simplificando o uso. | ||
|
|
||
| **🎁 Bônus Exclusivo:** | ||
|
|
||
| **[Clique para se registrar](https://302.ai)** e ganhe 1 PTC (1 PTC = 1 dólar americano, cerca de 7 yuans) imediatamente. Além disso, ganhe 5 PTC por dia experimentando a plataforma através do link. | ||
|
|
||
| **Junte-se à 302.AI e explore o mundo da inteligência artificial sem limites!** | ||
|
|
||
|
|
||
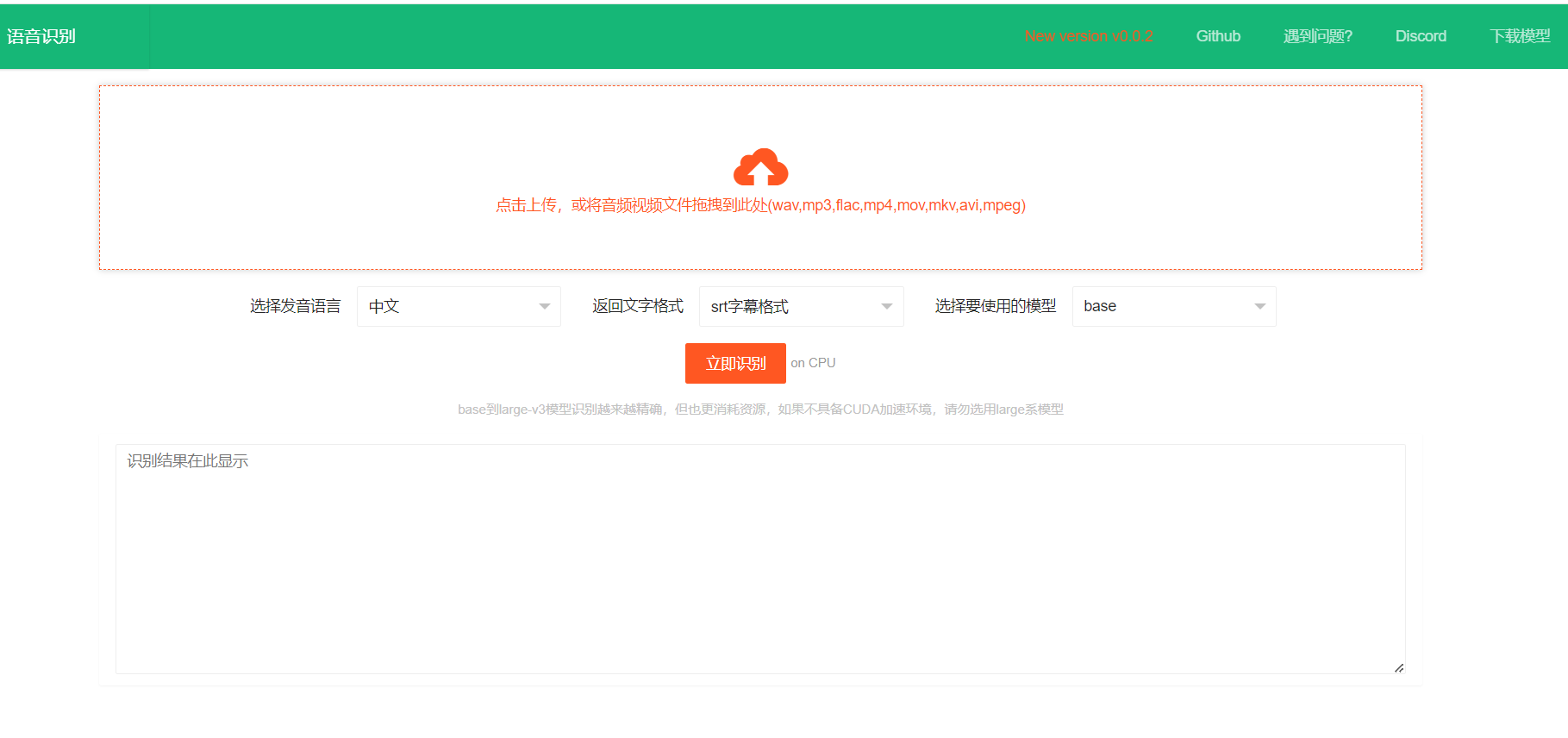
| ## Demonstração | ||
|
|
||
| https://github.com/jianchang512/stt/assets/3378335/d716acb6-c20c-4174-9620-f574a7ff095d | ||
|
|
||
|  | ||
|
|
||
|
|
||
| # Como Usar a Versão Pré-compilada (Windows) e Implantar o Código Fonte (Linux, Mac e Windows) | ||
|
|
||
| ## Versão Pré-compilada (Windows) | ||
|
|
||
| 1. **Baixe os arquivos:** Acesse a [página de lançamentos](https://github.com/jianchang512/stt/releases) e baixe os arquivos pré-compilados. | ||
| 2. **Descompacte:** Extraia os arquivos em um local de sua preferência (ex: `E:/stt`). | ||
| 3. **Execute:** Dê um duplo clique em `start.exe` e aguarde a abertura automática da janela do navegador. | ||
| 4. **Utilize a interface:** | ||
| * Clique na área de upload da página. | ||
| * Selecione o arquivo de áudio ou vídeo desejado (ou arraste-o para a área). | ||
| * Escolha o idioma da fala, o formato de saída do texto e o modelo. | ||
| * Clique em "Iniciar Reconhecimento". | ||
| * O resultado será exibido na caixa de texto inferior no formato escolhido. | ||
| 5. **Aceleração CUDA (opcional):** Se o seu computador possui uma GPU Nvidia e o ambiente CUDA está configurado corretamente, a aceleração CUDA será utilizada automaticamente. | ||
|
|
||
| ## Implantação do Código Fonte (Linux, Mac e Windows) | ||
|
|
||
| **Requisitos:** | ||
|
|
||
| * Python 3.9, 3.10 ou 3.11 | ||
|
|
||
| **Passos:** | ||
|
|
||
| 1. **Crie um diretório:** Crie um diretório vazio (ex: `E:/stt`). | ||
| 2. **Clone o repositório:** Abra o terminal (ou prompt de comando) neste diretório e execute: | ||
| ```bash | ||
| git clone https://github.com/jianchang512/stt.git | ||
| ``` | ||
| 3. **Crie um ambiente virtual:** | ||
| ```bash | ||
| python -m venv venv | ||
| ``` | ||
| 4. **Ative o ambiente virtual:** | ||
| * **Windows:** `%cd%/venv/scripts/activate` | ||
| * **Linux/Mac:** `source ./venv/bin/activate` | ||
| 5. **Instale as dependências:** | ||
| ```bash | ||
| pip install -r requirements.txt | ||
| ``` | ||
| * Em caso de erro de conflito de versão, execute: | ||
| ```bash | ||
| pip install -r requirements.txt --no-deps | ||
| ``` | ||
| * Para suporte à aceleração CUDA: | ||
| ```bash | ||
| pip uninstall -y torch | ||
| pip install torch --index-url [https://download.pytorch.org/whl/cu121](https://download.pytorch.org/whl/cu121) | ||
| ``` | ||
| 6. **Instale o FFmpeg:** | ||
| * **Windows:** Descompacte `ffmpeg.7z` e coloque `ffmpeg.exe` e `ffprobe.exe` no diretório do projeto. | ||
| * **Linux/Mac:** Consulte as instruções de instalação do FFmpeg para sua distribuição. | ||
| 7. **Baixe os modelos:** | ||
| * **Método 01:** | ||
| Baixe o [pacote de modelos compactado](https://github.com/jianchang512/stt/releases/tag/0.0) e coloque as pastas descompactadas na pasta `models` no diretório raiz do projeto. | ||
| * **Método 02:** | ||
| Use esta [tabela de modelos fast-whisper](https://github.com/jianchang512/pyvideotrans/blob/main/docs/pt-BR/Download-do-Modelo.md#modelos-faster-whisper) para baixar os modelos diretamente. | ||
| 8. **Execute:** | ||
| ```bash | ||
| python start.py | ||
| ``` | ||
| Aguarde a abertura automática da janela do navegador. | ||
|
|
||
| # Interface da API | ||
|
|
||
| * **Endereço:** `http://127.0.0.1:9977/api` | ||
| * **Método:** POST | ||
| * **Parâmetros:** | ||
| * `language` (código do idioma): | ||
| * Chinês: `zh` | ||
| * Inglês: `en` | ||
| * Francês: `fr` | ||
| * Alemão: `de` | ||
| * Japonês: `ja` | ||
| * Coreano: `ko` | ||
| * Russo: `ru` | ||
| * Espanhol: `es` | ||
| * Tailandês: `th` | ||
| * Italiano: `it` | ||
| * Português: `pt` | ||
| * Vietnamita: `vi` | ||
| * Árabe: `ar` | ||
| * Turco: `tr` | ||
| * `model` (nome do modelo): | ||
| * `base`: corresponde a `models/models--Systran--faster-whisper-base` | ||
| * `small`: corresponde a `models/models--Systran--faster-whisper-small` | ||
| * `medium`: corresponde a `models/models--Systran--faster-whisper-medium` | ||
| * `large-v3`: corresponde a `models/models--Systran--faster-whisper-large-v3` | ||
| * `response_format` (formato de legenda): `text`, `json` ou `srt` | ||
| * `file` (arquivo de áudio ou vídeo) | ||
|
|
||
| **Exemplo de Requisição (Python):** | ||
|
|
||
| ```python | ||
| import requests | ||
| # Endereço da API | ||
| url = "http://127.0.0.1:9977/api" | ||
| # Parâmetros da requisição | ||
| files = {"file": open("C:/Users/c1/Videos/2.wav", "rb")} | ||
| data = {"language": "zh", "model": "base", "response_format": "json"} | ||
| # Faz a requisição POST | ||
| response = requests.post(url, timeout=600, data=data, files=files) | ||
| # Imprime a resposta em formato JSON | ||
| print(response.json()) | ||
| # Interpretação da resposta: | ||
| # - code == 0: sucesso | ||
| # - code != 0: falha | ||
| # - msg == "sucesso": reconhecimento bem-sucedido | ||
| # - msg != "sucesso": motivo da falha | ||
| # - data: texto retornado após o reconhecimento (se houver) | ||
| ``` | ||
|
|
||
| ## Suporte à Aceleração CUDA | ||
|
|
||
| **Instalação de Ferramentas CUDA:** Para detalhes sobre o processo de instalação, consulte este [guia detalhado](https://juejin.cn/post/7318704408727519270). | ||
|
|
||
| Se o seu computador possui uma placa gráfica Nvidia, siga estes passos: | ||
|
|
||
| 1. **Atualize o driver da placa gráfica** para a versão mais recente. | ||
| 2. **Instale o CUDA Toolkit** e o **cudnn for CUDA11.x** correspondentes: | ||
| * [CUDA Toolkit](https://developer.nvidia.com/cuda-downloads) | ||
| * [cudnn for CUDA11.x](https://developer.nvidia.com/rdp/cudnn-archive) | ||
| 3. **Verifique a instalação:** | ||
| * Pressione `Win + R`, digite `cmd` e pressione Enter. | ||
| * Na janela de comando, digite `nvcc --version` e confirme se as informações da versão são exibidas (similar à imagem abaixo). | ||
|  | ||
| * Digite `nvidia-smi` e verifique se as informações de saída incluem o número da versão CUDA (similar à imagem abaixo). | ||
| * Execute `python testcuda.py`. Se exibir uma mensagem de sucesso, a instalação está correta. Caso contrário, revise e reinstale cuidadosamente. | ||
| 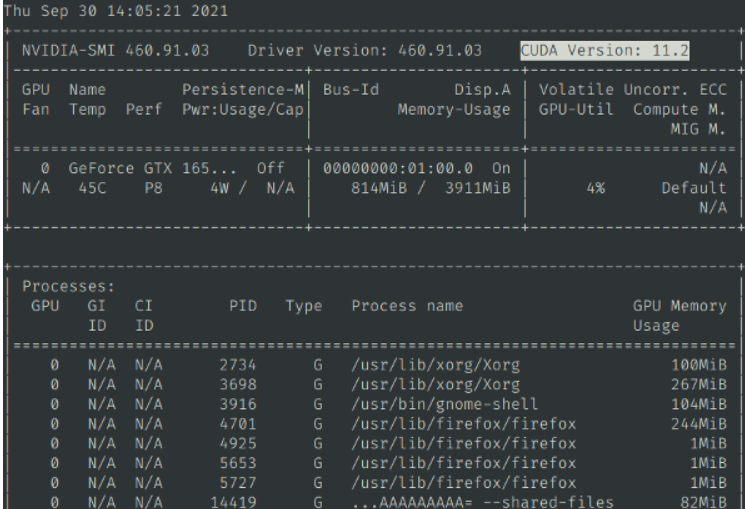 | ||
|
|
||
| **Habilitando a Aceleração CUDA:** | ||
|
|
||
| Por padrão, a CPU é usada para cálculos. Se você confirmou que está usando uma placa gráfica Nvidia e o ambiente CUDA está configurado corretamente, altere `devtype=cpu` para `devtype=cuda` no arquivo `set.ini` e reinicie o programa para utilizar a aceleração CUDA. | ||
|
|
||
| ## Observações Importantes | ||
|
|
||
| 1. **Modelos e Requisitos:** Se você não possui uma placa gráfica Nvidia ou o ambiente CUDA não está configurado corretamente, evite usar os modelos large/large-v3, pois eles podem consumir muita memória e travar o sistema. | ||
| 2. **Exibição de Caracteres:** Em alguns casos, o texto em chinês pode ser exibido em caracteres tradicionais. | ||
| 3. **Erro "cublasxx.dll não existe":** Baixe o cuBLAS neste link: [cuBLAS Download](https://github.com/jianchang512/stt/releases/download/0.0/cuBLAS_win.7z). Descompacte o arquivo e copie os arquivos DLL para `C:/Windows/System32`. | ||
| 4. **Mensagem de Aviso no Console:** Se o console exibir a mensagem "[W:onnxruntime:Default, onnxruntime_pybind_state.cc:1983 onnxruntime::python::CreateInferencePybindStateModule] Init provider bridge failed.", ignore-a, pois não afeta o uso do programa. | ||
| 5. **Falha na Execução com CUDA Habilitado:** | ||
| * **Possível Causa:** Se o CUDA estiver habilitado, mas o cudnn não foi instalado e configurado manualmente, pode ocorrer falha na execução. | ||
| * **Solução:** Instale a versão do cudnn que corresponde à sua versão do CUDA. Consulte o guia detalhado para instruções: [Guia de Instalação](https://juejin.cn/post/7318704408727519270). | ||
| * **Memória de Vídeo Insuficiente:** Se o problema persistir após a instalação do cudnn, a memória de vídeo da GPU pode ser insuficiente. Nesse caso, tente usar o modelo medium e evite o modelo large-v3, especialmente se a memória de vídeo for inferior a 8GB e o vídeo tiver mais de 20MB. | ||
|
|
||
| Lembre-se de que este guia fornece informações básicas e você pode precisar consultar recursos adicionais para solucionar problemas específicos. | ||
|
|
||
| # Projetos Relacionados | ||
|
|
||
| * [Tradução e Dublagem de Vídeo](https://github.com/jianchang512/pyvideotrans) | ||
| * [Clonagem de Voz](https://github.com/jianchang512/clone-voice) | ||
| * [Separação de Voz e Música](https://github.com/jianchang512/vocal-separate) | ||
|
|
||
| # Agradecimentos | ||
|
|
||
| Este projeto utiliza: | ||
|
|
||
| 1. https://github.com/SYSTRAN/faster-whisper | ||
| 2. https://github.com/pallets/flask | ||
| 3. https://ffmpeg.org/ | ||
| 4. https://layui.dev |