Rust version in here
Unix philosophy
Rule of Generation: Developers should avoid writing code by hand and instead write abstract high-level programs that generate code. This rule aims to reduce human errors and save time.
Cassandra walker is and ORM and query builder, for Cassandra,
cassandra-walker is command-line tool to generate idiomatic Golang code for Cassandra keyspaces (databases).
with pointing cassandra-walker to Cassandra cluster, cassandra-walker find tables in each keyspaces and for each tables create golang types, and idiomatic go codes.
This tools makes working with Cassandra very easy, it works great with IDEs, catch most of bugs at compile time, makes code base much more scalable and maintainable.
Create, Update, Delete for a Row:
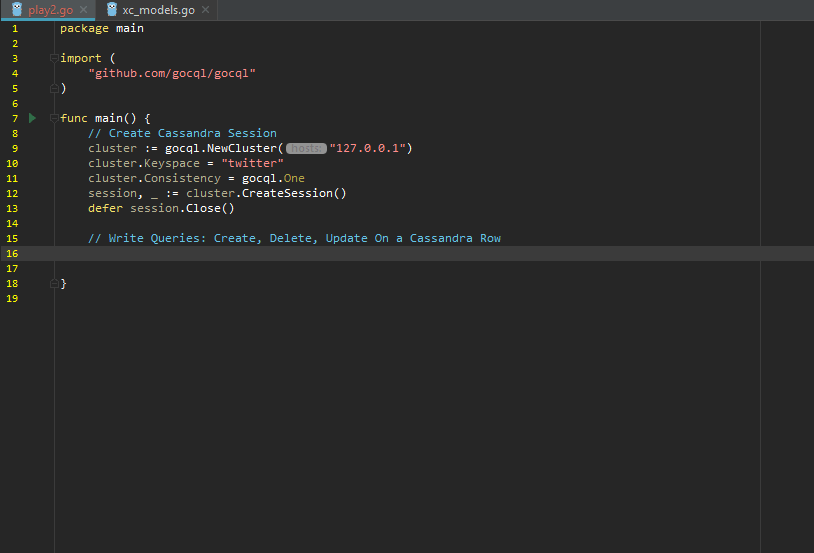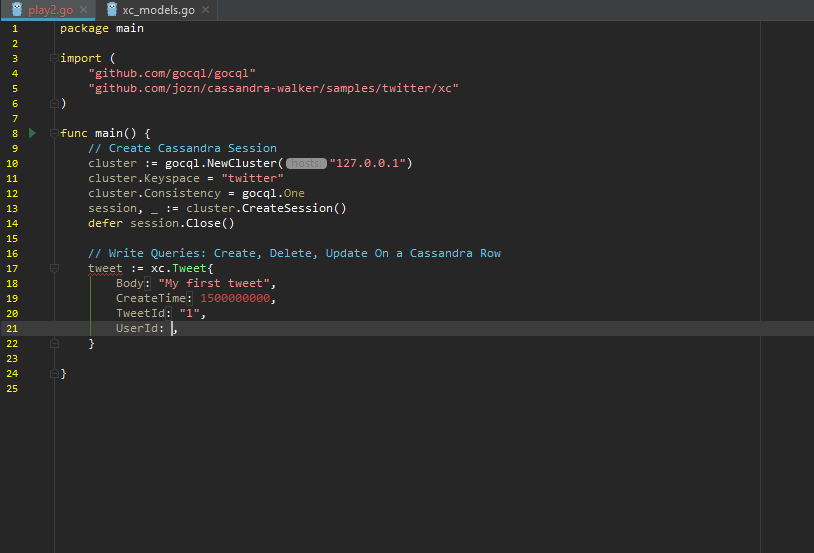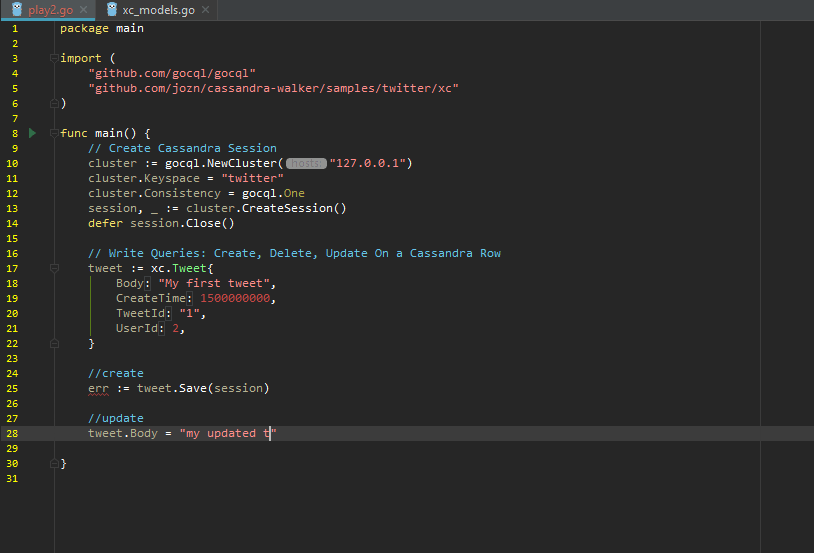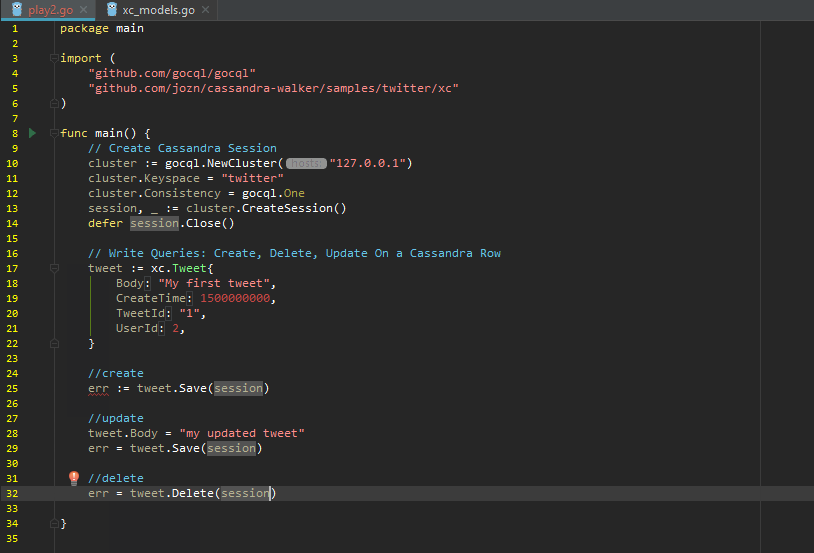
Building query against Cassandra:

Install cassandra-walker with:
go get -u github.com/jozn/cassandra-walker
Then point to cassandra node to genrate code for a keyspace (ex twitter):
cassandra-walker twitter
This will produce xc folder in current directory, and puts generated golang codes in this folder.
Use cassandra-walker -h to see parameter options.
Usage: cassandra-walker [--host HOST] [--port PORT] [--verbose] [--dir DIR] [--package PACKAGE] [--minimize] [KEYSPACES [KEYSPACES ...]]
Positional arguments:
KEYSPACES cassandra keyspaces to build
Options:
--host HOST, -c HOST cassandra cluster address (default 127.0.0.1)
--port PORT, -p PORT cassandra port (default 9042)
--verbose, -v verbosity Log
--dir DIR, -d DIR output of generated codes (default './')
--package PACKAGE package of go
--minimize, -m minimize docs
--help, -h display this help and exit
Lets see how to use this tool. We will follow twitter sample in sample directory
Assume you have this cassandra keyspace:
CREATE KEYSPACE twitter
WITH REPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};
CREATE TABLE twitter.tweet (
user_id bigint,
tweet_id varchar,
body varchar,
create_time int,
PRIMARY KEY (user_id,tweet_id)
);
CREATE TABLE twitter.user (
user_id int,
user_name varchar,
full_name varchar,
created_time bigint,
PRIMARY KEY (user_id)
);Run the following command:
cassandra-walker twitter --host 127.0.01 --port 9042
This will generates codes in xc directory.
See the result in godoc or in go files.
package xc
type Tweet struct {
Body string // body regular
CreateTime int // create_time regular
TweetId string // tweet_id clustering
UserId int // user_id partition_key
_exists, _deleted bool
}
/*
:= &xc.Tweet {
Body: "",
CreateTime: 0,
TweetId: "",
UserId: 0,
*/
type User struct {
CreatedTime int // created_time regular
FullName string // full_name regular
UserId int // user_id partition_key
UserName string // user_name regular
_exists, _deleted bool
}
/*
:= &xc.User {
CreatedTime: 0,
FullName: "",
UserId: 0,
UserName: "",
*/Now we have in type-safe can build queries, look at this simple script:
package main
import (
"github.com/gocql/gocql"
"github.com/jozn/cassandra-walker/samples/twitter/xc"
)
func main() {
// create cassandra session
cluster := gocql.NewCluster("127.0.0.1")
cluster.Keyspace = "twitter"
cluster.Consistency = gocql.One
session, _ := cluster.CreateSession()
defer session.Close()
// Create
tweet1 := xc.Tweet{
Body: "Hello World",
CreateTime: 1566000000,
TweetId: "1",
UserId: 1,
}
err := tweet1.Save(session)
// Delete one object
tweet1.Delete(session)
//////////////// For Selector
tweets, err := xc.NewTweet_Selector().UserId_Eq(1).Limit(5).GetRows(session) // returns and array of tweets ( []*tweet ,err )
tweet, err := xc.NewTweet_Selector().UserId_Eq(1).Limit(5).GetRows(session) // returns a single tweet ( *tweet ,err )
//can use clustering columns too
tweets, err = xc.NewTweet_Selector().UserId_Eq(1).And_TweetId_In("1", "25", "68").GetRows(session)
//can select just some columns, it will returns *[]Tweet, with just selected columns sets
tweets, err = xc.NewTweet_Selector().Select_UserId().Select_Body().UserId_Eq(1).And_TweetId_In("1", "25", "68").Limit(12).GetRows(session)
//for when need to use filtering
tweets, err = xc.NewTweet_Selector().UserId_LT_Filtering(100).Limit(10).AllowFiltering().GetRows(session)
//////////////// For Updater
err = xc.NewTweet_Updater().
Body("new tweet text").UserId_Eq(1).And_TweetId_In("1", "2", "3").Update(session)
//////////////// For Deleter
err = xc.NewTweet_Deleter().UserId_Eq(1).And_TweetId_In("1", "2", "3").Delete(session)
err = xc.NewTweet_Deleter().UserId_Eq(1).Delete(session)
_ = err
_ = tweets
_ = tweet
}
/* log output - this is produced CQL queries to cassandra:
2018/09/18 22:35:54 CQL: [insert into tweeter.tweet (body,create_time,tweet_id,user_id) values (?,?,?,?) [Hello World 1566000000 1 1]]
2018/09/18 22:35:54 CQL: [DELETE FROM tweeter.tweet WHERE user_id = ? And tweet_id = ? [1 1]]
2018/09/18 22:35:54 CQL: [SELECT * FROM tweeter.tweet WHERE user_id = ? LIMIT 5 [1]]
2018/09/18 22:35:54 CQL: [SELECT * FROM tweeter.tweet WHERE user_id = ? LIMIT 5 [1]]
2018/09/18 22:35:54 CQL: [SELECT * FROM tweeter.tweet WHERE user_id = ? And tweet_id IN (?,?,?) [1 1 25 68]]
2018/09/18 22:35:54 CQL: [SELECT user_id, body FROM tweeter.tweet WHERE user_id = ? And tweet_id IN (?,?,?) LIMIT 12 [1 1 25 68]]
2018/09/18 22:35:54 CQL: [SELECT * FROM tweeter.tweet WHERE user_id < ? LIMIT 10 ALLOW FILTERING [100]]
2018/09/18 22:35:54 CQL: [UPDATE tweeter.tweet SET body = ? WHERE user_id = ? And tweet_id IN (?,?,?) [new tweet text 1 1 2 3]]
2018/09/18 22:35:54 CQL: [DELETE FROM tweeter.tweet WHERE user_id = ? And tweet_id IN (?,?,?) [1 1 2 3]]
2018/09/18 22:35:54 CQL: [DELETE FROM tweeter.tweet WHERE user_id = ? [1]]
*/- Add twitter sample play code.
- Add docs for logging , and better docs for
*_Selector(),*_Updaterr()and*_Deleter(). - Add for Batching.
- Add
AllowFilteringto Deleter - Modify
.Save(...)and add.SaveCompact(...) - Do final cleanups ( remove double cql whitespaces, some unused codes, ... )
Similar projects for SQL databases.