Bulk Data Services
Caution: this page documents a capability of the 5.3.0 release that could have backward incompatibilities before stabilizing in a future release.
The MarkLogic Java API makes it straightforward to run jobs on dataflow frameworks that delegate tasks for bulk ingest, egress, or reprocessing to Data Service endpoints.
Executing a bulk IO endpoint involves the following roles:
-
connector developer – implements a MarkLogic connector that integrates the Java API with a dataflow framework.
-
endpoint developer – implements a Data Service endpoint on the MarkLogic appserver to process batches of data to complete work on behalf of a job.
-
job definer – configures the framework and MarkLogic connector to delegate work to the endpoint.
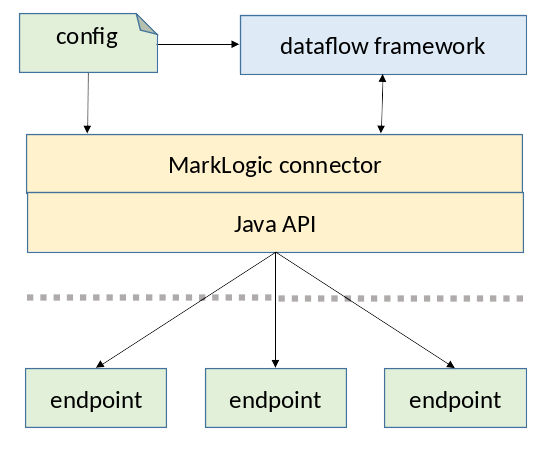
The MarkLogic connector can read configuration to specify which endpoint to call, how to call it, and what work to complete as part of a job managed by the dataflow framework. The MarkLogic Java API calls the endpoint repeatedly as needed to complete the work assigned by the dataflow framework.
By determining the interaction with the endpoint through configuration, the configuration-driven connector doesn't have to be modified to work with different endpoints or to work with endpoints in different ways.
The MarkLogic connector may partition the work among caller instances for an endpoint. For example, where an endpoint exports records, the connector might create a separate instance of the caller for each forest in the database such that each caller iterates over a query independently and concurrently for a different forest under the control of the dataflow framework.
The following basic examples show how a MarkLogic connector would configure an endpoint caller and mediate the interaction between the dataflow framework and the caller.
An example that configures a caller for ingesting a stream of records:
public void inputRecords(DatabaseClient db, String apidef, Stream<String> records) {
BulkInputCaller<String> loader =
InputCaller.on(db, new StringHandle(apidef), new StringHandle())
.bulkCaller();
records.forEach(loader::accept);
loader.awaitCompletion();
}
An example that configures a caller for sending records to a consumer lambda, sending constant values to the endpoint on each request (where the constants might, for instance, provide a serialized cts.query that specifies the set of records to be exported):
public void outputRecords(
DatabaseClient db, String apidef, String recordSetdef, Consumer<InputStream> recordConsumer
) {
OutputCaller<InputStream> OutputCaller =
OutputCaller.on(db, new StringHandle(apidef), new InputStreamHandle())
BulkOutputCaller<InputStream> unloader =
OutputCaller.bulkCaller(
OutputCaller.newCallContext()
.withEndpointConstants(new StringHandle(recordSetdef))
);
unloader.setOutputListener(recordConsumer);
unloader.awaitCompletion();
}
In both input and output cases, the functions of the connector implement a generic integration with the dataflow framework. The endpoint is specified by configuring the connector. Without interpretation by the connector, values passed through to the endpoint on each request parameterize the endpoint to perform the work.
Note: Where the input parameter or output return value has the anyDocument
data type, the onHandles() factory method should be used instead of the on()
factory method. In addition, input or output documents should be sent and received
with instances of the BufferableContentHandle subclass passed to the onHandles()
factory method. When passing the handle instance for each input document,
set the format (possibly using the withFormat() fluent setter) to indicate
the format of the input document (typically Format.JSON or Format.XML).
A bulk Data Service endpoint implements IO by taking documents as input and / or providing documents as output. The IO supported by the endpoint determines the role of the endpoint within the dataflow for the job:
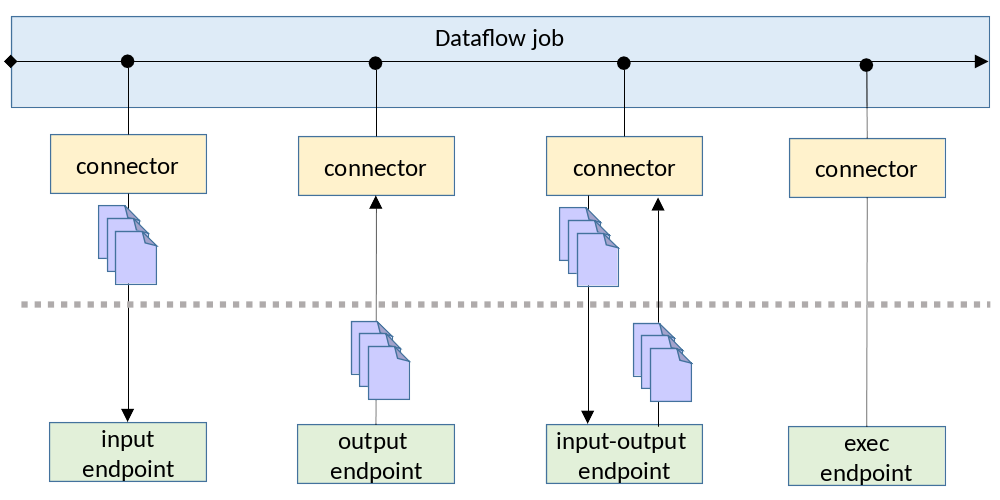
An endpoint may
- Take documents as input
- Return documents as output
- Both take documents as input and return documents as output
- Neither take documents as input nor return documents as output
Visibility into whether an endpoint takes input and / or provides output makes it possible for the MarkLogic connector to call the endpoint correctly as part of a job executed by the dataflow framework.
In addition to accepting document input and / or responding with document output, an endpoint can let the job definer control its behavior by means of a CallContext instance constructed by the newCallContext() factory method.
The CallContext supports the following fields:
| Field | Purpose |
|---|---|
| endpointConstants | Parameterizes the endpoint with immutable properties. |
| endpointState | Provides the endpoint with mutable properties maintained on the client between calls. |
| session | Creates or recreates an in-memory property cache on the enode. |
The job definer supplies the endpoint constants and initial state in the configuration, which the connector uses when constructing the bulk caller. The endpoint constants and initial state must specify properties expected by the endpoint. That is, the job definer is responsible for providing endpoint constants and initial state that are correct for the configured endpoint.
The following illustration shows the transmittal of documents and control parameters during repeated calls to an IO Data Service endpoint by a bulk caller of the Java API:
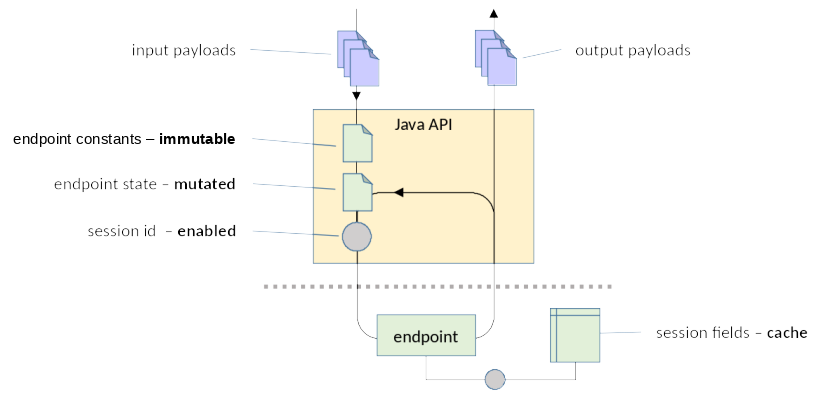
Analogy to Java: From the connector perspective, the fields of the CallContext resemble the following Java mechanisms:
- endpointConstants has a purpose similar to final fields in a Java object.
- endpointState has a purpose similar to mutable fields in a Java object.
- session has a purpose similar to weak references.
The endpoint constants field supplies the properties that remain the same over the series of calls to the endpoint during one execution of the job. Examples of potential endpoint constant properties include:
- collections or permissions for all ingested records
- provenance for all ingested records
- the batch size for exported records
- the name of the forest with the documents exported by this instance of a job task
- the JSON serialization of a cts.query to match the documents for the exported records
- the timestamp for a point-in-time query for exported records
- query criteria for a query executed by the endpoint to match records for reprocessing
Initialized from the configuration of the connector, the endpoint state properties are mutated by the endpoint itself. On each call, the Java API sends the current endpoint state and receives the endpoint state for the next request in the response.
As in RESTful architectures, the state of the endpoint is maintained on the client between calls. Because the endpoint state is sent in the call, load balancers can submit the request to any available enode, exploiting enode elasticity as well as recovering seamlessly from failover.
Examples of potential mutable properties include:
- running totals on the number of records rejected and ingested
- the offset to the first record in the current batch of exported records
- query criteria to match the current batch of exported records
- the last key from the previous batch for taking batches of records in sorted key order
In the response, the endpoint state must precede any output documents and must have the same format as the output documents. For instance, if the endpoint returns JSON output documents, the endpoint must return the endpoint state as JSON before the output documents.
Note that the endpoint state is not returned to the dataflow framework. Use output documents to return data for the job.
When the declaration for the endpoint specifies a session parameter, the
Java API generates a session ID and sends it in requests. The endpoint can use
the session ID by calling xdmp.*SessionField() / xdmp:*-session-field() builtin
functions to cache data in memory on the enode where the data is expensive to produce.
Because sessions can time out, the endpoint may only use session fields for data that can be reconstructed. The endpoint can use the endpoint state for properties that must be retained but cannot be reconstructed.
Note that sessions require host affinity. That is, the load balancer uses the same enode for the entire series of calls to the endpoint unless the enode fails over. As a result, endpoints should use sessions only when an enode cache is necessary.
Ordinarily, the dataflow framework itself provides concurrency (often distributed across multiple processes or even nodes). For instance, Spark manages a distributed cluster of Spark worker nodes, each of which can make independent calls to an endpoint.
In such robust environments, the connector should leave concurrency provisions - along with other aspects of managing the job - to the dataflow framework.
Connectors for simple, single-process environments - such as a command-line runner - may need to implement concurrency. In such environments, the connector can construct a bulk caller that makes use of a thread pool.
The call to the bulkCaller() factory can either specify a thread count argument after the CallContext argument or can pass in a CallContext array that specifies a separate context for each thread.
A CallContext array can be especially useful when partitioning the work. For instance, each CallContext can provide different endpoint constants that specify a different forest so the requests in different threads operate on different forests and thus don't need to coordinate.
When configuring a bulk caller to use multiple threads, the connector must specify listeners:
- For an OutputCaller.BulkOutputCaller or InputOutputCaller.BulkInputOutputCaller, the connector must specify a success listener to receive the output.
- For all bulk callers, the connector must specify a failure listener to receive any errors and to provide the error disposition.
When configuring a BulkOutputCaller to make concurrent calls in multiple threads, the connector cannot use the OutputCaller.BulkOutputCaller.next() method to pull data from the server.
The setErrorListener() setter method configures the bulk caller with a Java function (typically, a lambda) that implements a processError() method taking the error and the number of retries for this call so far and returning the error disposition.
The error disposition indicates whether to retry the call, skip the call, or stop the job by returning the IOEndpoint.BulkIOEndpointCaller.ErrorDisposition enumeration.
The arguments to the error listener include:
- The number of times the request has been retried
- The error thrown by the most recent failure
- The CallContext for the request
- For input and input-output callers, an array of BufferableHandles with the input for the request
Each endpoint provides a main module and a *.api declaration of the signature
of the main module including the input and / or output documents and the
control parameters. The declaration is installed with the main module
in the modules database for the appserver. The declaration is also provided
by the job definer in the job configuration so the MarkLogic connector can
initialize the caller provided by the Java API (as shown in the input and
output examples earlier).
All of the control parameters are optional and must be deleted from the declaration if not used by the endpoint. In particular, an endpoint must not declare an endpointState parameter if it doesn't return an document that serializes the endpointState.
In addition to its use for bulk IO endpoints, the *.api declaration
can be used to generate Java interfaces for data operation endpoints callable
by business logic on the middle tier of an appserver. The *.api declaration
for the two use cases differs in one property.
-
For a bulk IO endpoint, the
*.apideclaration has anendpointproperty specifying the full path of the main module in the modules database. -
For a data operation endpoint, the
*.apideclaration has afunctionNameproperty specifying the name of the main module. Code generation requires a separateservice.jsondeclaration with anendpointDirectoryproperty specifying the directory containing the main module.
Note: An *.api declaration may have both the endpoint and
functionName properties so the same endpoint can be called either
by a bulk caller or by a generated class.
The signature for an endpoint that produces output:
{
"endpoint": "OUTPUT_CALLER_PATH",
"params": [
{"name":"session", "datatype":"session", "multiple":false, "nullable":true},
{"name":"endpointState", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true},
{"name":"endpointConstants", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true}
],
"return": {"datatype":"DOCUMENT_TYPE", "multiple":true, "nullable":true}
}
The signature for an endpoint that takes input:
{
"endpoint": "INPUT_CALLER_PATH",
"params": [
{"name":"session", "datatype":"session", "multiple":false, "nullable":true},
{"name":"endpointState", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true},
{"name":"endpointConstants", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true},
{"name":"input", "datatype":"DOCUMENT_TYPE", "multiple":true, "nullable":true}
],
"return": {"datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true}
}
The signature for an endpoint that both takes input and produces output:
{
"endpoint": "INPUT_OUTPUT_CALLER_PATH",
"params": [
{"name":"session", "datatype":"session", "multiple":false, "nullable":true},
{"name":"endpointState", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true},
{"name":"endpointConstants", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true},
{"name":"input", "datatype":"DOCUMENT_TYPE", "multiple":true, "nullable":true}
],
"return": {"datatype":"DOCUMENT_TYPE", "multiple":true, "nullable":true}
}
The signature for an exec caller that neither takes input nor produces output:
{
"endpoint": "EXEC_CALLER_PATH",
"params": [
{"name":"session", "datatype":"session", "multiple":false, "nullable":true},
{"name":"endpointState", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true},
{"name":"endpointConstants", "datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true}
],
"return": {"datatype":"DOCUMENT_TYPE", "multiple":false, "nullable":true}
}
Note: An unstable earlier release used the workUnit name
for the endpointContants parameter. The older name is deprecated. Support
for the workUnit parameter will be removed soon.
The Java API minimizes the need for initialization in the MarkLogic connector by taking
as much configuration of the caller from the *.api declaration for the endpoint as
possible. The endpoint declaration can specify a $bulk annotation for supplemental
configuration of the caller.
In particular, the declaration for an input or input-output caller can specify the batch size for input documents as in the following sketch:
{"endpoint":"INPUT_CALLER_PATH",
...
"$bulk":{
"inputBatchSize":500
}}
The input batch size defaults to 100.
The specific implementation of any connector will, of course, depend on the dataflow framework.
In general, a connector should have the following characteristics:
- Take both the declaration of the endpoint to be called and the endpoint constants and initial endpoint state data structures for the endpoint from configuration.
- Construct an InputCaller, OutputCaller, InputOutputCaller, or ExecCaller as appropriate for the role of the endpoint within the job, passing the endpoint declaration.
- Initialize the endpoint with the configured endpoint constants and initial endpoint state, if provided by the configuration.
- Construct a bulk caller for the endpoint by calling the bulkCaller() factory method.
- Call the methods of the bulk caller to accept batches of input from the dataflow framework and / or consume batches of output in the dataflow framework.
The job definer is responsible for specifying and configuring an endpoint consistent with the IO role of the endpoint within the defined dataflow job. If the endpoint declaration or implementation isn't consistent with its IO role, the Java API throws an exception. The connector must expose the exception so the job definer can fix the configuration.
Often, a job will require awareness of the MarkLogic cluster. For instance, an egress job might query each forest independently. In such cases, a connector can depend on an endpoint specific to the framework for processing the configuration. For instance, a Spark connector might pass the job configuration to a Spark initialization endpoint that returns a list of property maps for constructing the tasks for the job.
In most cases, the connector should avoid building in awareness of the behaviors of any endpoint. This approach makes it possible to use different endpoints for different purposes and to innovate on jobs that meet special requirements.
To implement a new endpoint, an enode developer performs the following tasks:
- Determine the document IO, name, and modules database directory for the endpoint.
- Copy and save the appropriate signature as the
*.apideclaration for the endpoint. - Edit the
*.apideclaration - Change the
endpointproperty to specify the full path of the endpoint within the modules database. - Delete any of the optional
session,endpointConstants, orendpointStatecontrol parameters that are not needed. - Change every
DOCUMENT_TYPEdatatype placeholder to an appropriate document data type (either binaryDocument, jsonDocument, textDocument, or xmlDocument). - Implement a SJS, MJS, or XQY main module that expects parameters and returns output consistent with the
edited
*.apisignature. - Load the main module and
*.apifiles into the modules database at the path specified by theendpointproperty. Endpoint directories can also provide SJS or XQuery libraries in the usual way to maximize reuse across endpoints.
An IO endpoint that takes an endpoint state must return the modified endpoint state prior to any output to receive the modified endpoint state in the next request.
An output IO endpoint must return null to signal completion of the work.
The MarkLogic Java API provides predefined interfaces for single calls as well as bulk calls for each of the IO endpoint signatures. An IO endpoint developer can thus use the Java API to test an endpoint without having to generate client interfaces for calling the endpoint.
The *.api file for an endpoint can provide endpoint-specific request monitoring declarations in the usual way.
The endpoint developer must provide the *.api file to the job definer for configuration of jobs
that call the endpoint. In addition, the endpoint developer should document how to initialize
the endpoint including the endpoint constants and initial endpoint state.
The specific configuration of a job and connector will, of course, depend on the dataflow framework, the connector, and the endpoints.
In general, a job definer provides the following:
- The configuration for the connector such as the connection parameters for the MarkLogic server.
- The
*.apifiles to identify each endpoint that should complete work on behalf of the job. - Any portion of the endpoint constants and initial endpoint state required by an endpoint that the connector doesn't obtain by calling an initialization endpoint.