Fix bridge connection reset due to invalid packets #2275
Conversation
Add drop of conntrack INVALID packets in input such that invalid packets due to TCP window overflow do not cause a connection reset. Due to some netfilter/conntrack limitations, invalid packets are never treated as NAT'ed but reassigned to the host and considered martians. This causes a RST response from the host and resets the connection. As soon as NAT is setup, for bridge networks for instance, invalid packets have to be dropped in input. The implementation adds a generic DOCKER-INPUT chain prefilled with a rule for dropping invalid packets and a return rule. As soon as some bridge network is setup, the DOCKER-INPUT chain call is inserted in the filter table INPUT chain. Fixes moby#1090. Signed-off-by: Christophe Guillon <[email protected]>
531bb7c to
fc8f042
Compare
There was a problem hiding this comment.
@guillon thanks for addressing this issue
IMHO https://github.com/docker/libnetwork/blob/83e2bc1e11f2faa907737f96f55a45ba2634ded3/iptables/iptables.go#L202
would be a right place to add the invalid rule only for the specified interface in the FORWARD chain
Can you please add test cases as well in
https://github.com/docker/libnetwork/blob/master/drivers/bridge/setup_ip_tables_test.go
Unfortunately, invalid packets, including benign out-of-window packets must be treated (actually dropped) in the input rule, before the FORWARD chain is processed. Otherwise, netfilter will reset connection before passing the packet to the FORWARD chain.
Yes, I will allocate some time as soon as possible to add tests. |
|
@guillon I have not tried this out, but |
|
Seems odd, but I will verify this again, thanks for the pointer. |
|
I can confirm that adding the rules in the FORWARD chain does not work. |
|
@guillon if you can share your reproduction steps, I'd be happy to take a stab at it as well |
Should we open a ticket for that in the kubernetes issue tracker? |
|
@arkodg I have forked a testbench for the kubernetes issue which I modified to exhibit the issue solved by this pull request. Get it at : https://github.com/guillon/k8s-issue-74839 |
|
@thaJeztah I still have to exhibit the problem under kubernetes, in order to sort things out, I'm working on it... |
|
Actually, when installing kubernetes on some physical Ubuntu hosts as described in https://vitux.com/install-and-deploy-kubernetes-on-ubuntu/, the kubernetes networking does not use NAT, hence I can't reproduce the issue over kubernetes. |
|
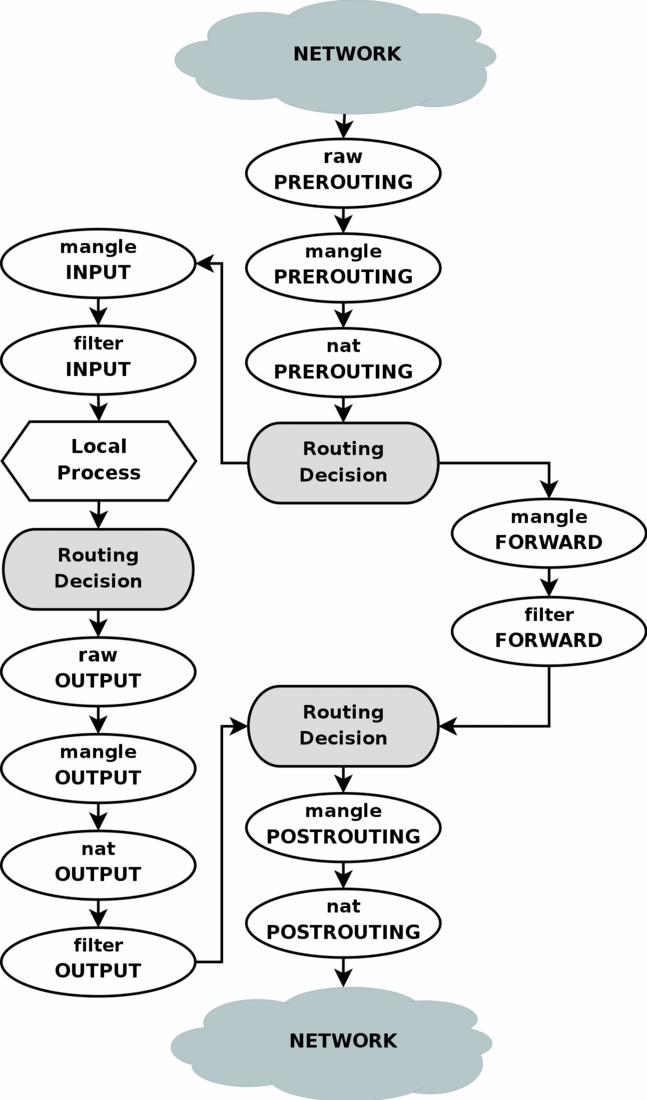
@guillon awesome work with the repro steps and the comments, was able to recreate this issue very easily I observed that these My hunch is that for some reason which is why adding this rule did the trick I verified the above using rules such as and I'm hesitant to add these rules to the INPUT chain because you cannot even filter it on the |
|
Indeed the filtering can't be done on docker0, all invalid packets in conntrack need to be dropped. The first routing decision in your diagram is that an invalid packet in prerouting is routed to the host as fallback and DNAT is abandonned, Note that since last year all our services (swarms + bare docker clients) are working perfectly with the fix. Don't remember if I mentionned it, but the overflow window error is typical in WAN setups due to WAN optimizations at the WAN routers level (packets deduplication in particular and also some aggressive packet streaming optimization strategies). The use case which revealed this issue was dockerized clients downloading from a distant artifacts database service, where WAN deduplication is quite effective. I have made at that time also a test over a WAN where I can also produce this by "artificially" making a client very slow, actually a bare |
|
Thanks for describing the background, in this case is there any way to capture packets on both ends and determine if the WAN router and host are abiding by the TCP Congestion Control RFCs or not Dropping these packets might solve your issue, but it still masks the problem because TCP is supposed to handle this case and the workaround causes more retransmissions on the network eating up the bandwidth |
|
I'm afraid I can't tell whether the WAN routers behave correctly, I'm not expert enough. Actually it happens that the WAN is loaded, the routers are being updated or [badly] tuned by the IT departement or other events over which I have no control. In the facts, when the networks behaves incorrectly, containerized services fail, while bare services remain functional. This has been reported multiple times in other contexts and even in IaaS vendors setups when we follow cross references from the issue #1090. What I've seen recommended is that as soon as setting up NAT tables, INVALID packets should be dropped. I agree that invalid packets can be created by bogus WAN routers, but I think we shouldn't care. This seems to be a surprising flaw in the design of the iptables conntrack module, I couldn't really find an explanation for this weird behavior which makes NAT less stable when INVALID packet are not dropped explicitly. |
|
Would it be possible to raise this issue with the conntreck folks, and see if this behavior is intentional or not before we consider adding such a rule |
|
This is still an issue, and still something that needs to be fixed, is there any other place to subscribe for potential changes and or fixes? |
|
Did someone take the time to discuss this with the conntrack people? Reading the discussion above, that's what's currently stalling this PR |
|
Is there any progress in this PR? There seems to be a widespread way to add the above as a workaround, as shown in the link below. I don't know if it's bad network equipment manner or a libnetwork issue, but I think it would be in the community's best interest to provide solution or conclusion. https://imbstack.com/2020/05/03/debugging-docker-connection-resets.html |
|
Any plan to merge this fix? as it has been outstanding for more than 4 years, and ppl are wasting tons of time in tracing down such issues. |
Add drop of conntrack INVALID packets in input
such that invalid packets due to TCP window overflow do
not cause a connection reset.
Due to some netfilter/conntrack limitations, invalid packets
are never treated as NAT'ed but reassigned to the
host and considered martians.
This causes a RST response from the host and resets the connection.
As soon as NAT is setup, for bridge networks for instance,
invalid packets have to be dropped in input.
The implementation adds a generic DOCKER-INPUT chain prefilled
with a rule for dropping invalid packets and a return rule.
As soon as some bridge network is setup, the DOCKER-INPUT
chain call is inserted in the filter table INPUT chain.
Fixes #1090.
Signed-off-by: Christophe Guillon [email protected]