-
Notifications
You must be signed in to change notification settings - Fork 4
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge branch 'master' of github.com:nournia/ai-proposals
- Loading branch information
Showing
2 changed files
with
51 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,3 +1,33 @@ | ||
| <div dir=rtl> | ||
|
|
||
| # تجزیه وابستگی متن | ||
| یکی از پیشنیازهای اصلی برای حل بسیاری از مسائل موجود در حوزه پردازش زبان طبیعی، وجود تحلیل نحوی از جملات زبان است. برای رسیدن به این هدف دو رویکرد متفاوت وجود دارد: | ||
| * [دستور زایشی](http://fa.wikipedia.org/wiki/دستور_زایشی): ابتدا جمله را به دو بخش نهاد و گزاره تقسیم میشود و در ادامه به صورت بازگشتی کار تقسیم را تا رسیدن به واژههای جمله ادامه میدهد. | ||
|
|
||
| 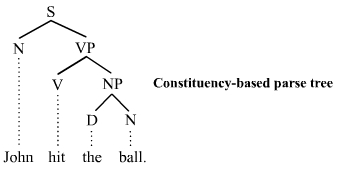 | ||
| * [دستور وابستگی](http://fa.wikipedia.org/wiki/دستور_وابستگی):وظیفه تجزیه جمله را از فعل اصلی جمله آغاز می کند و در گام اول وابستههای مستقیم فعل و در ادامه به صورت بازگشتی وابستههای سطح بعدی را تا تحلیل کامل جمله ادامه میدهد. | ||
|
|
||
| 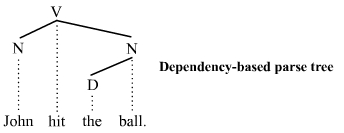 | ||
|
|
||
| تجزیه وابستگی برای تحلیل زبانهایی مثل فارسی که ترتیب واژگان در آنها ثابت نیستند بهتر است. یکی از الگوریتمهای تجزیه وابستگی که بر روی زبان فارسی دقت بالایی دارد و در عین حال پیادهسازی آن ساده است الگوریتم [کاوینگتون](http://www.stanford.edu/~mjkay/covington.pdf) است. تلاشهایی برای بهبود این الگوریتم نیز صورت گرفته است مثل [+](http://acl.ldc.upenn.edu/eacl2006/main/papers/04_1_nivre_29.pdf) و [+](http://acl.ldc.upenn.edu/D/D07/D07-1125.pdf). | ||
|
|
||
| در این پژوهش از شما خواسته شده است که الگوریتم کاوینگتون را پیادهسازی کرده و تلاش کنید دقت آن را بر روی زبان فارسی بهبود بخشید. | ||
|
|
||
| ## مقدمه | ||
|
|
||
| ## کارهای مرتبط | ||
|
|
||
| ## آزمایشها | ||
|
|
||
| ## مراجع | ||
| + Kübler, S., McDonald, R., & Nivre, J. "Dependency parsing", Synthesis Lectures on Human Language Technologies, Vol. 1, pp. 1–127, 2009. | ||
| + [م. خلاش، "بررسی روشهای تجزيه در دستور وابستگی"، سمينار کارشناسی ارشد ، دانشگاه علم و صعت ايران، 1390.](http://nlp.iust.ac.ir/downloads/articles/A%20Survey%20on%20Dependency%20Parsing.pdf) | ||
| + [م. خلاش، "ساز و کاری برای کشف تأثير ويژگیهای مختلف ساختواژی و صرفی بر روی تجزية وابستگی زبان فارسی"، پایاننامه کارشناسی اشد، دانشکده مهندسی کامپيوتر، دانشگاه علم و صنعت، 1391.](http://nlp.iust.ac.ir/downloads/articles/Dependency%20Parsing.pdf) | ||
| + [Khallash, M., Hadian, A., & Minaei-Bidgoli, B. "An Empirical Study on the Effect of Morphological and Lexical Features in Persian Dependency Parsing". In Proceedings of the Fourth Workshop on Statistical Parsing of Morphologically Rich Languages, pp. 97–107, 2013.](http://www.aclweb.org/anthology/W/W13/W13-4912.pd) | ||
|
|
||
| ## لینکهای مفید | ||
| + [پردازش زبان فارسی در پایتون](http://www.sobhe.ir/hazm) | ||
| + [پیکره درختی وابستگی فارسی اوپسالا](http://dadegan.ir/catalog/updt) | ||
| + [پیکره وابستگی نحوی زبان فارسی (دادگان)](http://dadegan.ir/catalog/perdt) | ||
| + [سامانه جستجو در دادگان](http://search.dadegan.ir) | ||
| + [پیادهسازی الگوریتم کاوینگتون](http://www.ai.uga.edu/mc/pronto/) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,3 +1,24 @@ | ||
| <div dir=rtl> | ||
|
|
||
| # مشخص کردن برچسب اجزای سخن | ||
| یکی از خصوصیاتی که به عنوان ورودی در اکثر وظایف پردازش زبان طبیعی استفاده میشود، برچسب اجزای سخن است. برای این منظور یک مجموعه تگ (tagset) مانند شکل زیر انتخاب میشود و به هر واژه در متن یک برچسب اختصاص داده خواهد شد. | ||
|
|
||
|  | ||
|
|
||
| ## مقدمه | ||
|
|
||
| ## کارهای مرتبط | ||
|
|
||
| ## آزمایشها | ||
|
|
||
| ## مراجع | ||
| + [Seraji, Mojgan. "A statistical part-of-speech tagger for Persian." Proceedings of the 18th Nordic Conference of Computational Linguistics NODALIDA 2011. 2011.](http://uu.diva-portal.org/smash/get/diva2:421097/FULLTEXT02) ([دریافت مدل](http://stp.lingfil.uu.se/~mojgan/tagper.html)) | ||
| + [Mohseni, Mahdi, and Behrouz Minaei-Bidgoli. "A Persian Part-Of-Speech Tagger Based on Morphological Analysis." LREC. 2010.](http://www.lrec-conf.org/proceedings/lrec2010/pdf/107_Paper.pdf) | ||
| + [Shamsfard, Mehrnoush, and Hakimeh Fadaei. "A Hybrid Morphology-Based POS Tagger for Persian." LREC. 2008.](http://www.lrec-conf.org/proceedings/lrec2008/pdf/875_paper.pdf) | ||
| + [Azimizadeh, Ali, Mohammad Mehdi Arab, and Saeid Rahati Quchani. "Persian part of speech tagger based on Hidden Markov Model." 9th International Conference on the Statistical Analysis of Textual Data. 2008.](http://lexicometrica.univ-paris3.fr/jadt/jadt2008/pdf/azimizadeh-arab-quchani.pdf) | ||
|
|
||
| ## لینکهای مفید | ||
| + [پردازش زبان فارسی در پایتون](http://www.sobhe.ir/hazm) | ||
| + [برچسبگذاری خودکار اجزای واژگانی کلام، پروژه درس هوش مصنوعی، دانشگاه علم و صنعت، 1388](http://bayanbox.ir/id/7261204785026299944?download) | ||
| + [برچسبگذاری بر اساس مقوله دستوری، پروژه درس هوش مصنوعی، دانشگاه علم و صنعت، 1388](http://bayanbox.ir/id/7069998416872188020?download) | ||
| + [پیکره بیجنخان](http://ece.ut.ac.ir/dbrg/bijankhan/) |