This project is a simple application designed to help developers get familiarized with Retrieval-Augmented Generation (RAG) and Spring AI. It demonstrates how to build the skeleton of a RAG application using Spring Boot, Spring AI, and a vector store for document retrieval.
It's important to note that this project is NOT a complete RAG solution as it lacks the "Generation" component typically provided by Large Language Models (LLMs). Instead, this application focuses on the "Retrieval" aspect, functioning more as a knowledge retrieval or data lookup system. Nevertheless, it remains highly valuable for learning about and experimenting with vector embeddings, semantic search, multilingual lookup, metadata handling, and vector database indexing techniques. These fundamental concepts are essential building blocks for developing more comprehensive RAG systems.
- Spring Boot: Backend framework for building Java applications.
- Spring AI: Library for integrating AI capabilities into Spring applications.
- PGvector: Vector database for storing and querying vector embeddings.
- Vue.js: Frontend framework for building user interfaces.
- Local Ollama Installation: Required and expected to be already running on port 11434. Ollama is a tool for managing and deploying machine learning models locally.
Retrieval-Augmented Generation (RAG) is a technique that combines document retrieval with text generation. It retrieves relevant documents from a vector store based on a query and then uses these documents to generate a response. This approach enhances the quality and relevance of generated text by grounding it in real-world information.
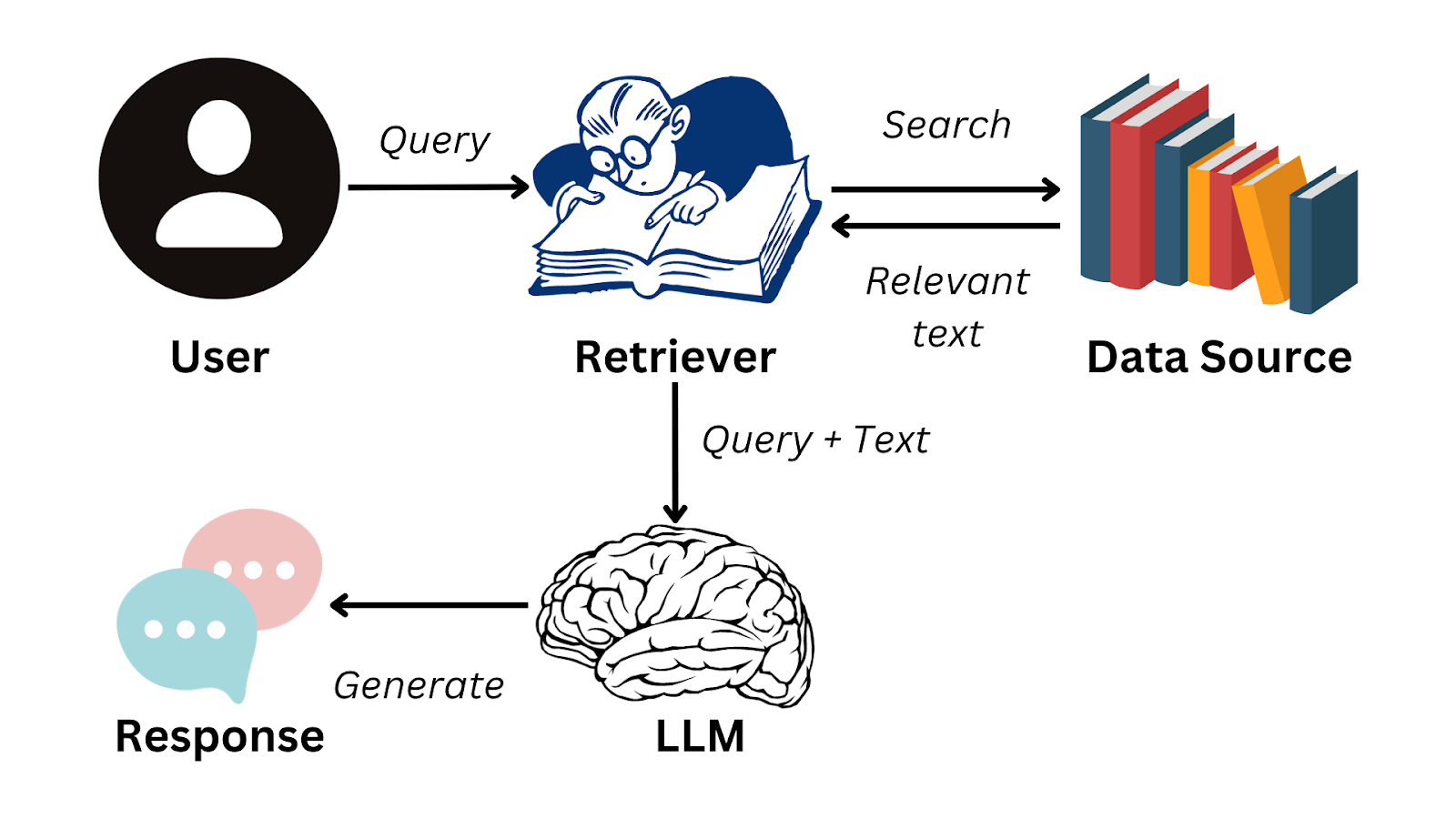
RAG is useful because it can augment the existing knowledge an LLM has (which is limited and frozen in time). For example, one could embed and then index a company's FAQ (which are very specific and unknown to the LLM) and then use those documents to generate answers for a user's query.
- Document Preparation: Company embeds and indexes its documents (e.g., FAQ about its internal processes like refund and return policies)
- User Interaction: User asks a question about the company process (e.g., "How do I return a product and get a refund?")
- Retrieval: System generates the embedding for that query and retrieves similar documents from the vector store. A similarity threshold can be used to supress noise.
- Generation: These retrieved documents are then fed to an LLM that generates a final answer using a prompt like this:
You are a customer support assistant for company XYZ.
User asked this: "I want to get a refund."
Using ONLY the following documents from our knowledge base, answer the user providing accurate information. If the documents are not helping with that question (unrelated), just say "I cannot help you with that."
Documents:
- To get a refund you need to ...
- Return the product to address 123 Dummy Street and ...
- Inform your bank account to receive the ...
The embedding model is responsible for taking a piece of text and converting it to a vector (an array) of floating-point numbers. This resulting vector retains the semantic characteristics of the original text, hence allowing it to be compared with embeddings of other texts using a metric known as cosine similarity.
Embedding models use neural networks to transform text into high-dimensional vector spaces where semantically similar concepts are positioned closer together. These vectors capture the meaning, context, and relationships between words and concepts, allowing machines to understand semantic similarity rather than just lexical matching.
The closer a vector "A" is to a vector "B", the more similar their original content is. This enables semantic search where queries can find relevant documents even if they don't share the exact same keywords.
Bellow we have a chart with 2 axes (Y representing royalty and X representing gender). A "Queen" would be high on both the royalty and female dimensions. A "King" would be high on royalty but low on the female dimension.

The difference between a King and a Queen is not on the royalty axis, but on the gender axis, which can be conceptualized as:
King = Queen - Female + Male
or conversely:
Queen = King - Male + Female
Now imagine if we had a 3-dimensional chart with royalty, gender, and age axes. A "princess" would be close to a queen because both are royal and female, but they differ on the age dimension, with the princess being younger.
Likewise, a prince is close to a princess in the sense that they share common characteristics for royalty and age, but differ on the gender axis.
Now imagine what 768 or 1536 dimensions can represent in terms of capturing semantic relationships...
In this project, we use the granite embedding model, which generates vectors of 768 dimensions. This dimensionality provides a good balance between representational power and computational efficiency. It can be executed locally by Ollama using only the CPU (having a GPU makes it faster, but it is not required).
Key characteristics of our embedding approach:
-
Vector Dimensionality: 768 dimensions provide sufficient semantic expressiveness while remaining manageable for storage and computation.
-
Multilingual Support: The model supports multiple languages, allowing queries in different languages to find semantically relevant documents regardless of the language they were written in.
-
Normalization: Vectors are normalized to unit length, ensuring that similarity comparisons focus on direction rather than magnitude.
-
Contextual Understanding: Unlike simpler word-based embeddings, our model captures contextual information, meaning the same word in different contexts can have different vector representations.
Different embedding models offer various tradeoffs between accuracy, speed, and resource requirements:
-
Small models (like our 278M parameter Granite model) are faster but may have less nuanced understanding.
-
Larger models (like OpenAI's text-embedding-ada-002 with 1.5B parameters) can capture more subtle semantic relationships but require more computational resources.
The choice of embedding model significantly impacts both the quality of search results and the system's performance characteristics.
Vector stores are specialized databases designed to store and query vector embeddings. They are used in RAG applications to efficiently retrieve documents that are semantically similar to a given query. In this project, we use PGvector, a PostgreSQL extension for vector similarity search.
To set up the project, follow these steps:
-
Clone the repository:
git clone https://github.com/raonigabriel/simple-rag.git cd simple-rag -
Start the services using Docker Compose:
docker-compose up -d
-
Run the Spring Boot application:
./mvnw spring-boot:run
-
Access the application: Open your browser and navigate to
http://localhost:8080.
The frontend of this application is very simple and is built using Vue.js. It provides a basic interface for entering search queries and displaying the search results.
To use the application, enter a search query in the provided input field and click the search button. Here are some sample queries you can try:
- "powerful male"
- "queen"
- "king"
- "princess"
- "pope"
- "boat"
- "talk"
- Semantic search is NOT keyword search. Try a more complex query, e.g., "Statue of the Lionheart in London".
- Search for "Bio". Take a look at the first result. Can you explain why it appears first? (It's probably related to "Amazon", "biome", "environment" - take a look here).
- Search for "Amazon". Take a look at the first result. Can you explain why it appears first?
- Search for "Bio" again. Take a look at the second result. Can you explain why it ranks second?
- Search for "transportation on water". Do you get results related boats and ships even though those exact keywords aren't used in your query? This demonstrates how semantic search understands concepts, not just keywords.
- Search for "vela branca tremulando" with at least 6 results (top-k). What are the first 3 results? What is the 6th result?
Hint: "vela" is a word in Portuguese that has 3 very different meanings, that depend on the context:
- It means "Candle" (that white wax item used when there's no electricity or during religious ceremonies)
- It means "Sail" (the white fabric used on boats to propel them forward using wind power)
- It means "Spark plug" (the device used in internal combustion engines to ignite the fuel mixture)
Here are some suggested enhancements you could implement to extend this project:
- Add an index to the metadata column (JSONB) on the locale attribute to speed up filtering.
- Enhance document metadata by adding more attributes like a created_at timestamp, and use these for advanced filtering.
- Experiment with document ingestion by using the ETL Pipeline to process a PDF file, such as the Tesla Q4 2023 Report available here.
- Add a minimum threshold value parameter for search results to filter out low-relevance matches, allowing users to control the quality of returned documents based on similarity scores.