Short Paper
In this demonstration, we present SQLFlow, an end-to-end machine learning system that operates at various databases, machine learning frameworks, and clouds. SQLFlow provides access to worldwide machine learning models via an extremely easy-to-use interface. Although artificial intelligence has made great progress in recent years, related technologies impose a steep learning curve for data scientists and machine learning practitioners. This greatly hinders the widespread application of AI. We've observed this problem and bridge the gap with the aid of the simplicity of SQL. SQLFlow extends the SQL syntax to enable model training, inference, and explanation, hence empowering users to leverage all the strength of the AI community, even though they have little knowledge about programming and machine learning. SQLFlow has already played a huge role in easing the daily work of machine learning engineers and data scientists in Ant Financial and DiDi. In this demo, we show that SQLFlow helps inexperienced or novice users reduce the learning curve in training machine learning models significantly. In addition, we show that SQLFlow gives users deep insight into data through its explanation functionalities effortlessly.
In recent years, machine learning (ML), especially deep neural networks (DNN), have made great progress in academia, and significantly advanced many real-world applications in the industry. Those applications are typically based on TensorFlow, PyTorch or other ML frameworks as XGBoost. Database is also an important part of such applications, usually as a persistent storage for the training dataset and business data. Classically, the current experience of development ML-based applications requires a team of data engineers, data scientists, business analysts, ML engineers as well as a proliferation of advanced programming languages and tools like C/C++, Python, SQL, SAS, SASS, Julia, R. For example, a typical recommendation system requires data engineers to save user data into databases in SQL, ML engineers need to generate training data from databases and train and tune a ML model with Python or C/C++, data scientists and business analysts have to analyze the influence of the model using Python, SQL, or R. Actually, it is tremendously labor-intensive and time-consuming to implement an ML-based application. The steep learning curve of ML frameworks requires expertise. The fragmentation of the tooling and development environment brings additional difficulties in engineering to do ML model training/tuning.
How about enabling engineers with only SQL skills to develop advanced ML-based applications? This requires delivering an end-to-end solution that meshes the most widely used data processing language SQL with ML capabilities. The solution should be compatible with many SQL engines, instead of a specific version or type. It should support sophisticated machine learning models, including DNNs and Gradient Boosting Decision Trees (GBDT).
There have been corresponding works in progress in the industry. Several SQL dialects provide extensions to support machine learning capabilities. Microsoft SQL Server has the machine learning service that runs machine learning programs in R or Python as an external script. Teradata SQL provides a RESTful service, which is callable from the extended SQL SELECT syntax. Google BigQuery ML enables machine learning in SQL by introducing the CREATE MODEL statement. However, Microsoft SQL Server requires the users to be capable of writing machine learning programs in R or Python. The syntax of Teradata SQL couples the deployment of the service with the algorithm. Currently, BigQuery ML only supports training simple models like logistic regression. Obviously, none of these existing methods meet the requirements of an end-to-end solution mentioned above. Moreover, they are all proprietary software bundled with corresponding cloud computing products. This makes them unavailable for most of the users.
In this demo, as the first major step in our insight into the demands of such solutions, we deliver SQLFlow (https://github.com/sql-machine-learning/sqlflow), the first end-to-end machine learning system that combines databases and ML frameworks. There're several significant features that make SQLFlow different from the above works. Some might question the applicability of SQL for the complex tasks of ML applications, we argue that SQL is one of the most widely accepted languages in the data world, is very easy to learn, and has enough expression ability to train, inference, and explain ML models.
First of all, SQLFlow is open source software that is accessible to users all over the world. SQLFlow slightly extends the SQL syntax to enable model training, inference, and explanation, hence easy to use for both ML experts and newcomers. There are only three kinds of new syntax in SQLFlow. To train, predict, or explain an ML model, a user only needs to write something like SELECT * FROM train_data TO TRAIN/PREDICT/EXPLAIN some_model. This is easy to learn, understand, use and maintain. SQLFlow supports most of the popular databases and ML frameworks rather than binds to a fixed deployment.
Secondly, because the extended syntax is based on standard SQL, SQLFlow is extensible to new databases and ML frameworks. SQLFlow is also very flexible in that it is friendly to both ML experts and inexperienced practitioners. SQLFlow allows the former to configure and run cutting-edge ML algorithms including feature engineering and hyperparameter tuning while keeping the ease of use for the latter because it's fully integrated with automated machine learning (AutoML) toolkits for hyperparameter optimization and neural architecture search. We noticed there has been research on developing speech-driven interfaces for regular SQL. Because SQL has an unambiguous context-free grammar, it can be more precise to recognize SQL from acoustic signals, therefore SQLFlow can integrate automatic speech recognition engines like SpeakQL, hence empowering users even with little knowledge to SQL, ML, and programming, to the ability of AI community. This is another advantage of using SQL for ML tasks.
Furthermore, SQLFlow has a model zoo that collects model definitions as well as previously-trained models from all the users. SQLFlow model zoo supports both public and on-premises deployments, this enables users to share and exchange models from all over the world. SQLFlow model zoo also integrates TensorFlow Hub to leverage the existing wisdom of the deep learning community. The AutoML subsystem of SQLFlow can benefits from the model zoo as the previously-trained models may speed up the hyperparameter optimization process.
At last, SQLFlow has built-in a Kubernetes-native deep learning framework called ElasticDL (https://github.com/sql-machine-learning/elasticdl) that supports fault-tolerance and elastic scheduling and is a solution to large scale ML applications. Because SQLFlow itself is a Kubernetes-native software too, SQLFlow is available to most of the users, from individual developers with MySQL and XGBoost to multinational giant with large scale distributed databases and TensorFlow.
In terms of practical value, the possible applications of SQLFlow include a) small team mobile apps for training user interest models; b) banks or financial companies for analyzing business data; c) ML experts for rapid model verification and deployment. In fact, SQLFlow has successfully deployed in the recommendation systems of Alipay and core business analysis system of DiDi for different production environments, with on-premises model zoos. Both of the deployments reduced the engineers' workload greatly.
We designed SQLFlow as a cross compiler with a Kubernetes-native runtime. The design gives SQLFlow the flexibility to be adapted to new databases, new ML frameworks, and containerized environments. In general, as a compiler, SQLFlow depends on the toolchain of the platforms to create executables (typically python files or Docker images). However, SQLFlow also has a standalone running mode to ease prototyping. The system architecture of SQLFlow looks similar to a typical compiler and is depicted in Figure 1. The components include a user interface layer, the frontend and backend of the compiler, and the SQLFlow runtime.

Figure 1: The system Architecture of SQLFlow. The dotted boxes illustrate an example of the compilation dataflow of a training statement.
User Interface. This component is the entry point for SQLFlow. A user inputs the extended syntax SQL into the system through speech with the help of the speech recognition submodule or typing with the help of the auto-complete submodule. After execution, the component displays the result of the queries. For normal queries, the result displayed is exactly the same as the database backends. For model training queries, the metrics of the best possible models are displayed. For model explanation queries, the component displays figures that describe the law implicit in the data using the ML models. Although SQLFlow only provides a console line interface and Jupyter notebook as the default user interface, it's convenient to customize SQLFlow with a full-featured IDE. In fact, SQLFlow already supports several cloud IDEs, such as Alibaba Cloud Dataworks and the IDEs of the private clouds in Ant Finance and DiDi.
Frontend. This component keeps normal queries intact and converts extended SQLs into intermediate representations. The SQLFlow parser can recognize the standard part of an extended query, so the intermediate representations are neutral to any databases or ML frameworks. Semantic analysis is the most import submodule of the frontend. Besides semantic verification such as checking the existence of the selected fields, the semantic submodule automatically deduces all the necessary information from the extended query to train a model. As a result, the users need not specify the shapes/types/names for features, the range of hyperparameters search, or the neural architecture of DNNs. If the users are not satisfied with the deduced hyperparameters and neural architectures, the frontend allows them to specify those attributes manually and pass the specified attributes to the intermediate representations.
Backend. This component generates executables from the intermediate representations, based on the target ML frameworks and databases. A typical SQLFlow executable is a python program that executes in the SQLFlow runtime. The SQLFlow backend requires all the supported databases and ML frameworks expose a unified interface. Currently, the available ML frameworks in SQLFlow include ElasticDL, TensorFlow, XGBoost and Alibaba Cloud PAI, the available databases are Hive, MySQL and Alibaba Maxcompute. New ML frameworks and databases can be easily adapted with a compatible interface. The backend also generates code for saving and restoring the ML models, hence the models can be deployed for online inference or for transfer learning. The backend supports ML model explanation via SHAP and TensorFlow, an explainer should have a conformed interface too.
Runtime. This component manages the execution of SQLFlow programs. There are several submodules in the SQLFlow runtime.
- Containerization and the Workflow Framework are the pedestal of the SQLFlow runtime, they support run SQLFlow programs natively on a Kubernetes cluster. They are depended on by all the other submodules.
- ML Framework, DB Driver and Explainer. The runtime encapsulates ML frameworks, model explainers, and databases into python modules with the interface required by the backend. As the built-in ML engine, ElasticDL is a part of the ML frameworks submodule.
- Optimization is an AutoML system that optimizes model performance automatically. It collects hyperparameters settings from the previously-trained models in the SQLFlow model zoo and performs hyperparameter searching and neural architecture searching.
- Auth. The submodule keeps sessions of SQLFlow users for authentication and authorization, which is essential for deploying SQLFlow on clouds.
- Visualization generates training metrics or model explanation figures that are feedback to and shown by the user interface.
As mentioned earlier, the main focus of SQLFlow is to bridge SQL and ML, thus simplifying the learning curve of ML technologies for inexperienced users. We will demonstrate this through several steps that follow the principle of gradual improvement. Our demo SQLFlow deployment will run on MySQL. Two laptops would be available at the demo.
Datasets. In the demonstration, we plan to show the typical use case of SQLFlow on three common ML datasets. The Iris flower dataset (https://www.kaggle.com/arshid/iris-flower-dataset) is a tiny classification dataset that is good for the introduction of ML basics. The Titanic dataset (https://www.kaggle.com/c/titanic) is a more challenging classification task. The Boston housing dataset (https://www.kaggle.com/c/boston-housing) is an interesting regression problem. We plan to show the data schema to the audience to make sure the datasets are fully understood. In the following parts, we will focus on demonstrating how SQLFlow combined the convenience of SQL and the flexibility and power of ML.
Model Training. Once familiarized with the datasets, the audience would be shown an example training statement. The audience could play around with the Iris dataset and the training statement to get familiar with the SQLFlow extended syntax and the SQLFlow environment. In this step, the training statement would be simple and have around 10 tokens, for example, the statement "SELECT * FROM iris.train TO TRAIN AutoDNNClassifier LABEL class INTO sqlflow_models.dnn_model" trains a supervised DNN model for the Iris dataset. The participant could try different classifiers to get a better result (typically get a loss of less than 0.4). After getting an ideal training result of the Iris dataset, the user will then choose Titanic or Boston housing to try training a real-world ML model.
Model Tuning. ML experts usually try to get better training results by manually tuning the hyperparameters of the ML models. The simple training statement above is optimized by the AutoML mechanism of SQLFlow, hence becoming a good baseline to be started with. We would show the audience several principles for tuning hyperparameters (learning rate e. g.). In order to improve the model performance on the Boston or Titanic dataset, the user would try to organize complex training statements with more than 20 tokens to tune the hyperparameters of the ML model. Typically they can get at least a slightly better result than the simple statement.
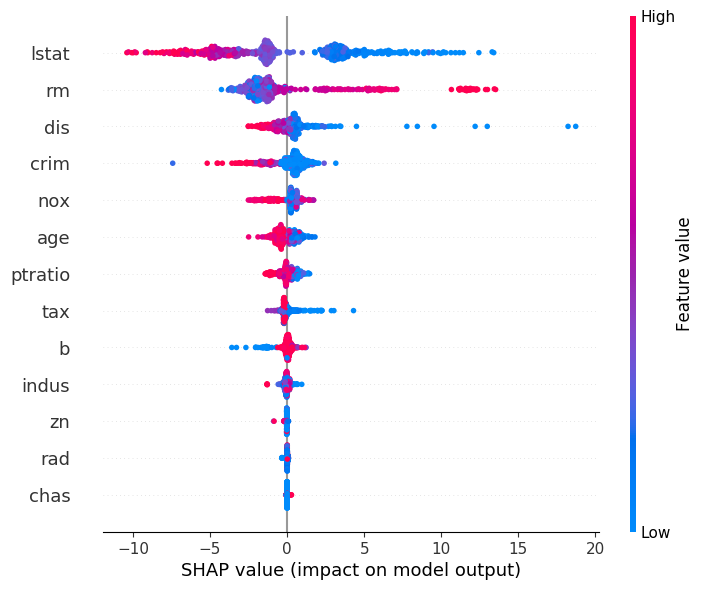
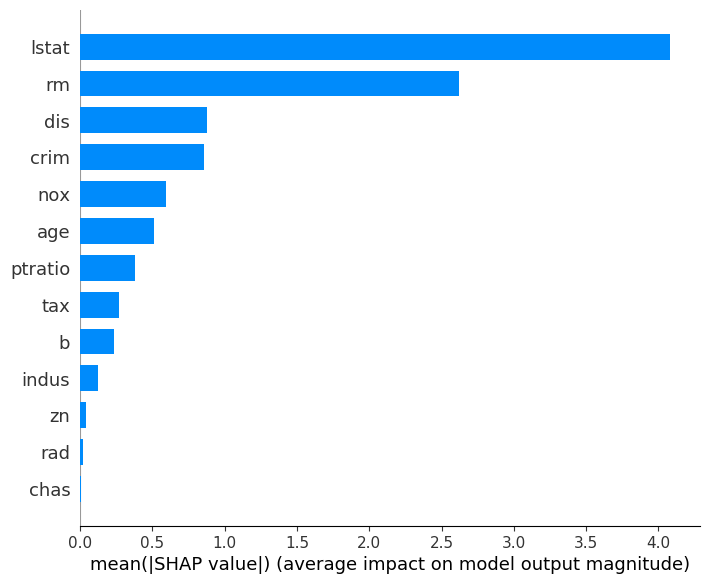
Model Explanation. The ML models have already played critical roles in critical areas like travel safety, health care, and the financial industry. It's necessary for ML practitioners or data scientists in these areas to figure out how and why the models make the decisions to make sure the models are working as expected. Now that the users have got decent model metrics for the datasets, they would have the same requirement of interpreting the models. Participants would use the SQLFlow explainer to explain the model they've trained. The explaining statements are always less than 10 tokens thus rather easy to grasp. In this demo, SQLFlow would generate explanation figures that include a histogram that depicts the importance of different fields in the datasets to the target field, a scatter plot or a violin plot that describes the distribution of the impacts each feature has on the model output. In general, SQLFlow explainer would generate figures with very clear meaning for a well-trained model. Typical explanation figures for a decent model for the Boston dataset would look similar to Figure 2.
[1] D. Chandarana et al. 2017. SpeakQL: Towards Speech-driven Multimodal Querying. HILDA (2017)
[2] S. M. Lundberg and S.-I. Lee. 2017. A unified approach to interpreting model predictions. NIPS (2017)