Usage

To load a file as a document corpus, each document in a file should be in a new line (eg. CSV format). If your goal is classification, each document should have a label in the label column.
Connect the widgets as shown on the image below.

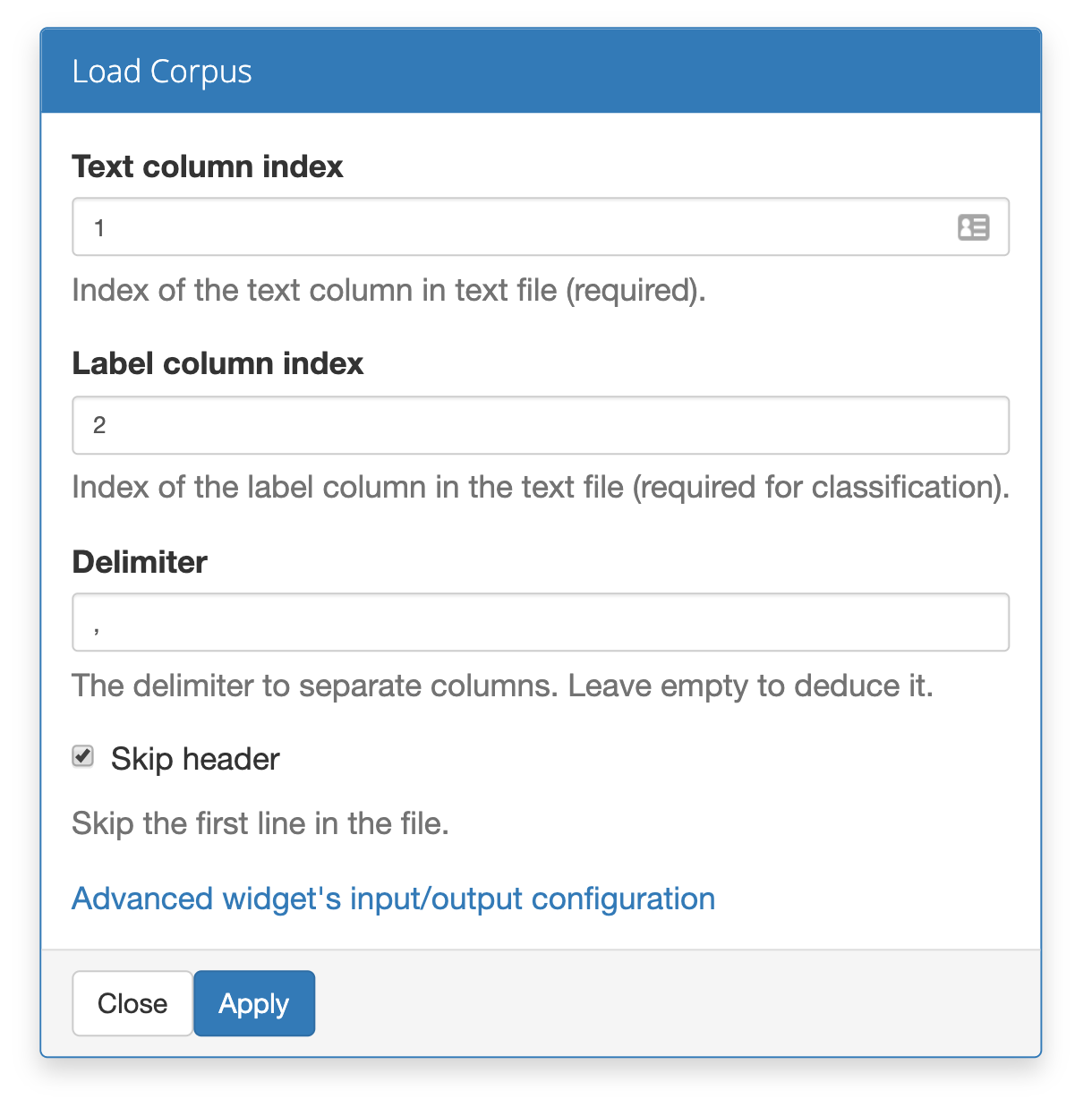
In Load Corpus widget set the text and label indices (counting starts with 1). If your document contains a header you can skip it by marking skip header checkbox.
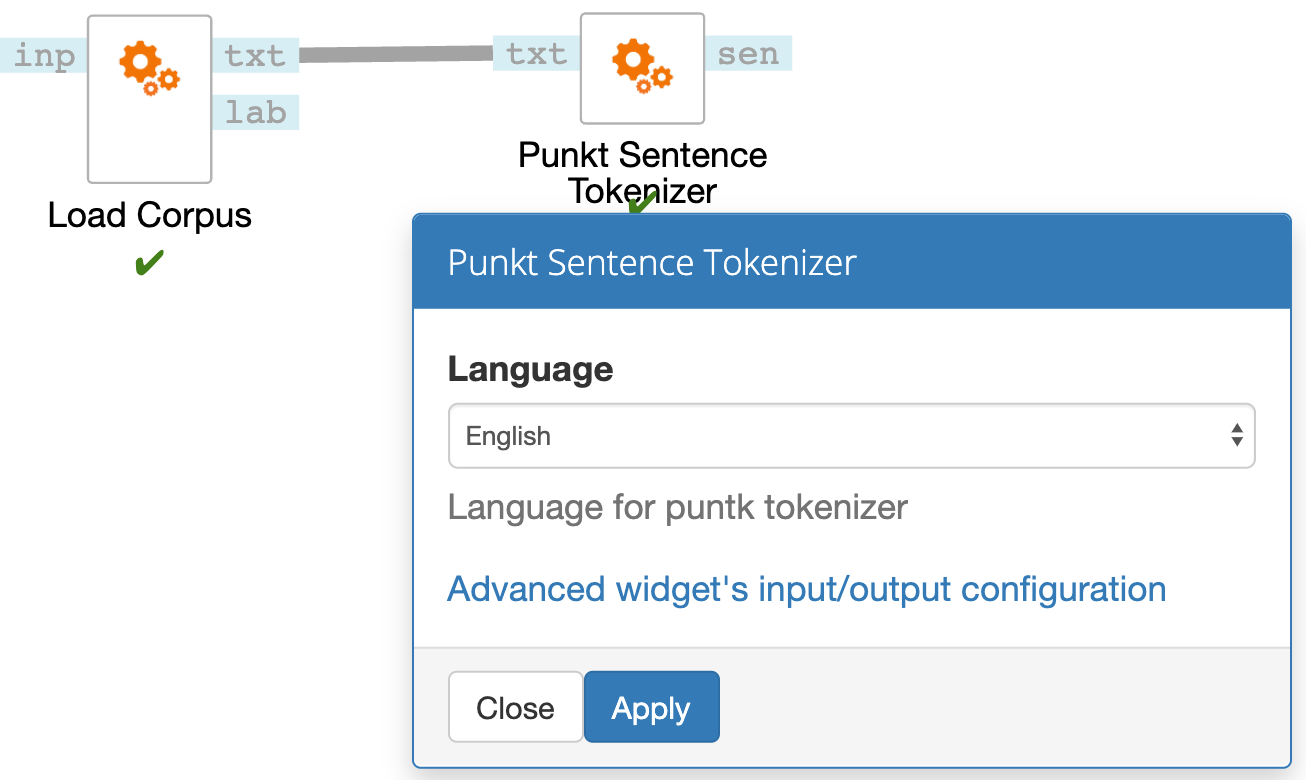
Documents need to be tokenized to words to calculate word embeddings or to sentences to calculate sentence embeddings.
Connect the TokTok Word Tokenizer with Load Corpus to split document to words or Punkt Sentence tokenizer to tokenize it to sentences (on the image below). Punkt Sentence tokenizer has also support for multiple languages.
Tokenization is not necessary for embeddings widgets that takes txt on the input.
Word tokens can be additionally filtered by using the Token Filtering widget (on the image below).

By default, filtering is done on tokens that can be seen in the image below.
You can also specify a custom token to filter out from the document corpus.
Each token needs to be separated by a new line.

To calculate Text Embeddings, select the embeddings method (ELMo in this example) and connect the widgets as in the image below.
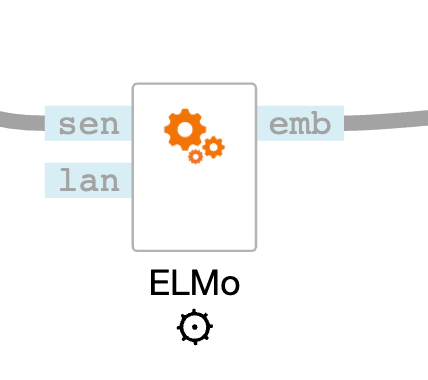
Elmo has Language and Aggregation Method parameters. Language select box lists supported languages for embeddings method. Not all embeddings method support the same languages, some of them are multilingual (BERT). Aggregation method specifies how words or sentences embeddings are combined to a document embedding. Sum and average are available.

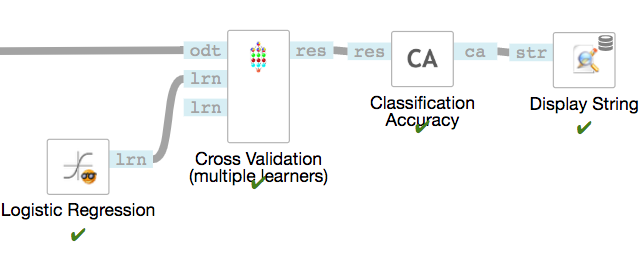
To evaluate or compare the performance of text embeddings methods, you have multiple options. On the image below, we show how to use Cross Validation with Logistic Regression to calculate Classification Accuracy of the model on a given dataset.