-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
6 changed files
with
246 additions
and
226 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,207 @@ | ||
| #! https://zhuanlan.zhihu.com/p/589106222 | ||
|
|
||
| # 一文解释 Diffusion Model (二) SDE 理论推导 | ||
|
|
||
| > 为了和文献一致,这里采用$s_\theta(\boldsymbol{x},t)$来表示神经网络的预测值,而不是$f_\theta(\boldsymbol{x},t)$。为了简化符号,用$\nabla\log p_\theta(\boldsymbol{x})$ 表示 $\nabla_{\boldsymbol{x}} \log p_\theta(\boldsymbol{x})$。同时你需要知道 $p(\boldsymbol{x};\theta)$ 等价于 $p_\theta(\boldsymbol{x})$。 | ||
|
|
||
|
|
||
| 一开始不要步子迈那么大,我们先从一些熟悉的东西开始。在[DDPM](https://zhuanlan.zhihu.com/p/565901160)中我们有一些结论: | ||
| $$ | ||
| \text{前向过程 } \quad \boldsymbol{x}_t \sim q(\boldsymbol{x}_t | \boldsymbol{x}_{0})=\mathcal{N}(\boldsymbol{x}_t ; \sqrt{\bar{\alpha}_t} \boldsymbol{x}_0 , (1- \bar{\alpha}_t)\mathbf{I})) \tag{1} | ||
| $$ | ||
| 根据 Tweedie's Formula,对于一个高斯变量 $z \sim \mathcal{N}(z; \mu_z, \Sigma_z)$,有如下结论: | ||
| $$ | ||
| \mu_z = z + \Sigma_z \nabla \log p(z) \tag{2} | ||
| $$ | ||
| 我们套用到式(1)中,那么有: | ||
| $$ | ||
| \sqrt{\bar{\alpha}_t} \boldsymbol{x}_0 = \boldsymbol{x}_t + (1- \bar{\alpha}_t)\nabla \log p(\boldsymbol{x}_t) \tag{3} | ||
| $$ | ||
| 式(1)展开来写就是 $\boldsymbol{x}_t =\sqrt{ \bar{\alpha}_t} \boldsymbol{x}_0 + \sqrt{1- \bar{\alpha}_t}{\boldsymbol{\varepsilon}}_t$ ,因此做一下 $\boldsymbol{x}_0$ 的等价变化: | ||
| $$ | ||
| \boldsymbol{x}_0 = \frac{\boldsymbol{x}_t + (1- \bar{\alpha}_t)\nabla \log p(\boldsymbol{x}_t)}{\sqrt{\bar{\alpha}_t}} = \frac{\boldsymbol{x}_t-\sqrt{1-\bar{\alpha}_t} \boldsymbol{\varepsilon}_t}{\sqrt{\bar{\alpha}_t}} \\ | ||
| \Rightarrow \nabla \log p(\boldsymbol{x}_t) = -\frac{\boldsymbol{\varepsilon}_t}{\sqrt{1-\bar{\alpha}_t}} \tag{4} | ||
| $$ | ||
| 同样的,我们在DDPM中推导优化目标的时候,是需要先建模出 $\boldsymbol{\mu}_q$,然后再用一个神经网络来学习近似它,回忆当时推导的结论是: | ||
| $$ | ||
| \boldsymbol{\mu}_q = \frac{1}{\sqrt{\alpha_t}} \boldsymbol{x}_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t} \sqrt{\alpha_t}} \boldsymbol{\varepsilon}_t \tag{5} | ||
| $$ | ||
| 我们只需要用式(4)替换 $\boldsymbol{\varepsilon}_t$ 即可以得到一个新的建模方式: | ||
| $$ | ||
| \boldsymbol{\mu}_q = \frac{1}{\sqrt{\alpha_t}} \boldsymbol{x}_t+\frac{1-\alpha_t}{ \sqrt{\alpha_t}} \color{red}{\nabla \log p(\boldsymbol{x}_t)} \tag{6} | ||
| $$ | ||
| 类似的,我们可以将逆向估计过程建模成: | ||
| $$ | ||
| \boldsymbol{\mu}_\theta = \frac{1}{\sqrt{\alpha_t}} \boldsymbol{x}_t+\frac{1-\alpha_t}{ \sqrt{\alpha_t}} \color{red}{s_\theta(\boldsymbol{x}_t, t)} \tag{7} | ||
| $$ | ||
| 重新推导优化目标: | ||
| $$ | ||
| \begin{aligned} | ||
| & \underset{\theta}{\arg \min } D_{\mathrm{KL}}\left(q\left(\boldsymbol{x}_{t-1} | \boldsymbol{x}_t, \boldsymbol{x}_0\right) \| p_{\theta}\left(\boldsymbol{x}_{t-1} | \boldsymbol{x}_t\right)\right) \\ | ||
| =& \underset{\theta}{\arg \min } \frac{1}{2 \sigma_q^2(t)}\left[\left\|\boldsymbol{\mu}_{\theta}-\boldsymbol{\mu}_q\right\|_2^2\right] \\ | ||
| =&\underset{\theta}{\arg \min } \frac{1}{2 \sigma_q^2(t)} \left[\left\|\frac{1-\alpha_t}{\sqrt{\alpha_t}}s_{\theta}\left(\boldsymbol{x}_t, t\right)-\frac{1-\alpha_t}{\sqrt{\alpha_t}}\nabla \log p\left(\boldsymbol{x}_t\right)\right\|_2^2\right] \\ | ||
| =&\underset{\theta}{\arg \min } \frac{1}{2 \sigma_q^2(t)} \frac{\left(1-\alpha_t\right)^2}{\alpha_t}\left[\left\|s_{\theta}\left(\boldsymbol{x}_t, t\right)-\nabla \log p\left(\boldsymbol{x}_t\right)\right\|_2^2\right] | ||
| \end{aligned} \tag{8} | ||
| $$ | ||
|
|
||
| --- | ||
|
|
||
| **到这里是不是就发现,借由一个Tweedie定理引入了一个新的梯度变量后,好像不一样了,但又好像一样。带着一些疑问我们继续往下看。现在我们可以给出一些新的名称,$\nabla \log p(\boldsymbol{x}_t)$ 被称为 score function,接下来我们将介绍 Score-based Generative Model。** | ||
|
|
||
| --- | ||
|
|
||
| 还是回到数据分布 $p(\boldsymbol{x})$ 的估计问题上来,任意一个概率分布,我们可以用一个更加通用的形式来表示: | ||
| $$ | ||
| p_\theta(\boldsymbol{x}) = \frac{1}{Z(\theta)}e^{-f_\theta(\boldsymbol{x})} \tag{9} | ||
| $$ | ||
| 这来源于能量模型 (Energy-Based Models)。$Z(\theta)=\int e^{-f_{\theta}(\boldsymbol{x})} d \boldsymbol{x}$ 代表一个归一化常数,来确保p.d.f积分 $\int p_{\theta}(\boldsymbol{x}) d \boldsymbol{x}$ 等于1。通常的估计方法是最大似然估计(MLE),但就不得不去先考虑分母,因为它是不知道的。如何消除这个归一化项 $Z(\theta)$ 的影响?就有如下几类:(这篇文章要介绍的是第三种方法) | ||
|
|
||
| - Flow 限制 Z=1。 | ||
| - VAE|GAN 没有消除Z,直接硬去用一些Measure测度方法估计,VAE找到一个距离的证据下界,GAN直接用网络去学距离度量。 | ||
| - Score-based 直接消掉Z,对p求对数梯度。 | ||
|
|
||
|
|
||
|
|
||
| 我们对式(9)求对数梯度: | ||
| $$ | ||
| \begin{aligned} | ||
| \nabla \log p_\theta(\boldsymbol{x}) | ||
| &= -\nabla f_\theta(\boldsymbol{x}) - \nabla\log Z(\theta) \quad ...(Z(\theta) \text{和} \boldsymbol{x} \text{无关}) \\ | ||
| &= -\nabla f_\theta(\boldsymbol{x}) | ||
| \end{aligned} \tag{10} | ||
| $$ | ||
| 而优化过程可以直接用一个神经网络 $s_\theta(\boldsymbol{x})$ 来近似,从真实数据 $p(\boldsymbol{x})$ 中采样一个变量,然后求对数梯度,就提供了一个优化方向: | ||
| $$ | ||
| \mathbb{E}_{p(\boldsymbol{x})} \left[\|s_\theta(\boldsymbol{x}) - \nabla \log p(\boldsymbol{x})\|^2_2\right] \tag{11} | ||
| $$ | ||
| 这里停一下,好好感受一下,数据空间的每个点都被赋予了一个分数向量 (score vector),从初始点开始不断迭代,最终能到达目标数据所在的区域,如下图所示。 | ||
|
|
||
|  | ||
|
|
||
| 诶,怎么结果都出来了,我还不知道怎样一步一步迭代更新的呢?这里其实也是要说明为什么这个score function那么重要,我们那么关心?是因为一旦我们知道了这个score(p(x)对输入x的梯度),我们就可以使用朗之万动力学(Langevin dynamics)采样数据,过程是 | ||
|
|
||
| $$ | ||
| \boldsymbol{x}_{t+1} \leftarrow \boldsymbol{x}_t+\delta \nabla \log p(\boldsymbol{x}_t)+\sqrt{2 \delta} \boldsymbol{\varepsilon}_t, \quad t=0,1, \cdots, T \tag{12} | ||
| $$ | ||
| 其中 $\boldsymbol{x}_0$ 是随机初始点;$\delta$ 是一个比例系数;$\boldsymbol{\varepsilon}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$ 是是一个扰动项,避免采样结果崩塌到一个固定点。当 $\delta$ 足够小,$T$ 足够大的时候,最终的 $\boldsymbol{x}_T$ 就是真实数据。 | ||
|
|
||
|
|
||
|
|
||
| 这里再停一下,式(11)能优化吗?因为需要知道真实数据的score function,这显然是无法获知的。但还好,其他学者早已研究出如何在不知道真值的情况进行优化,这类方法统称为“score matching”,常见的方法有[denoising score matching](https://www.iro.umontreal.ca/~vincentp/Publications/smdae_techreport.pdf) | [sliced score matching](https://arxiv.org/abs/1905.07088)。尽管如此,可以求解了,但依然会面临一个问题: | ||
|
|
||
| - 低密度区域的样本太少,估计就会不准确,甚至某些采样点的概率可能为0,那么取对数就没有意义了,也就是说训练效果会不好。 | ||
|
|
||
| 如何解决呢? | ||
|
|
||
| - 加入高斯噪声,就减少了零概率的出现,使得低密度区域也有了更多的样本。 | ||
|
|
||
| 而这里如何确定噪声的大小就成了问题的关键,目前提出的是加一系列不同尺度的噪声,然后分步训练每一尺度的score matching网络,具体过程是先引入一系列噪声 $\{\sigma_t\}_{t=1}^T$,然后就可以得到对应的噪声扰动后的分布: | ||
| $$ | ||
| p_{\sigma_t}\left(\boldsymbol{x}_t\right)=\int p(\boldsymbol{x}) \mathcal{N}\left(\boldsymbol{x}_t ; \boldsymbol{x}, \sigma_t^2 \mathbf{I}\right) d \boldsymbol{x} \tag{13} | ||
| $$ | ||
| 这里用一个原图来帮助理解,我们要训练的是图中的箭头 (大小和方向),随着 $\sigma_1 < \sigma_2 < \sigma_3$ 增大,学到的箭头越来越细腻。 | ||
|
|
||
| 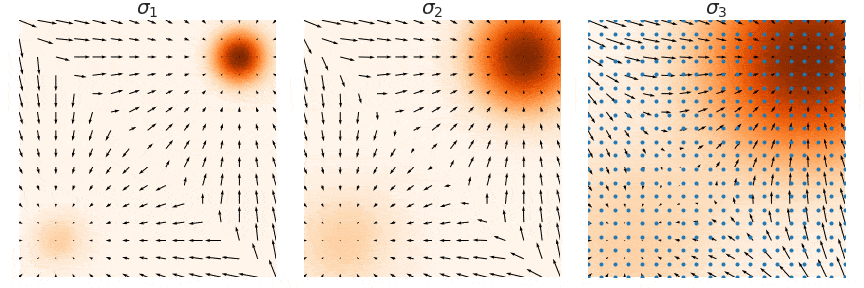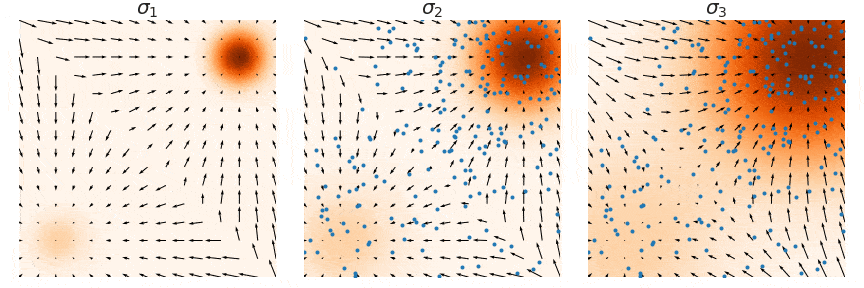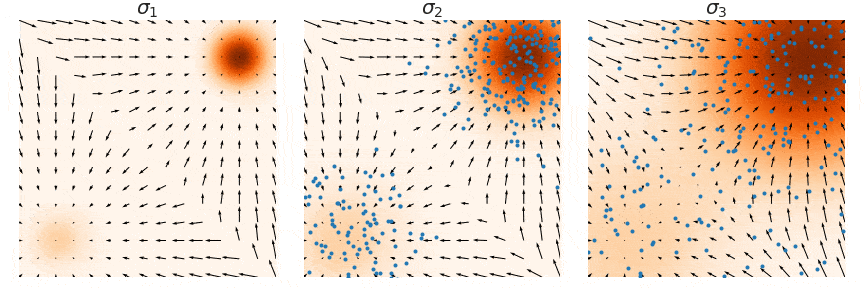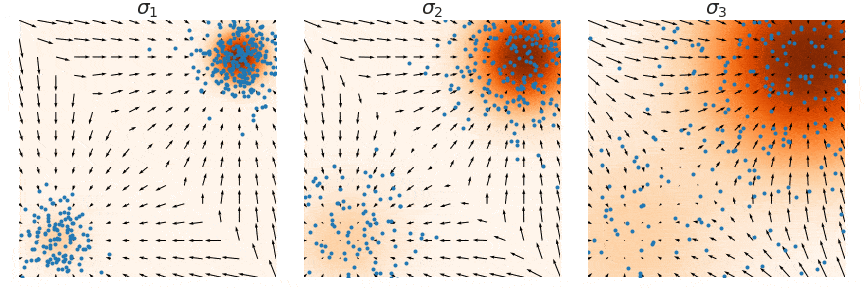 | ||
|
|
||
| 然后式(11)就可以改写成: | ||
| $$ | ||
| \underset{\boldsymbol{\theta}}{\arg \min } \sum_{t=1}^T \lambda(t) \mathbb{E}_{p_{\sigma_t}\left(\boldsymbol{x}\right)}\left[\left\|s_{\theta}(\boldsymbol{x}, t)-\nabla \log p_{\sigma_t}\left(\boldsymbol{x}\right)\right\|_2^2\right] \tag{14} | ||
| $$ | ||
| 其中 $\lambda(t)$ 是一个关于 $t$ 的权重向量,也就是实现了前面说的分不同噪声尺度训练。在这种设定下,朗之万动力学采样也是分尺度来做,只不过是逆着来,从 $t=T$ 到 $t=T-1$,最后到 $t=1$。直觉上高噪声提供了低密度区域较好的引导,低噪声提供了高密度区域较好的引导,这样使得整个采样过程更加稳定。 | ||
|
|
||
| **从这个角度有没有帮助你更好地理解Diffusion Model为什么如此有效呢?为什么需要扩散过程,为什么需要分层加噪声?** | ||
|
|
||
| --- | ||
|
|
||
| 接下来要介绍的是,如果把上述有限步 $T$ 拓展到无限步会怎么样?因为经过实验验证,$T$ 越大,可以得到更准确的似然估计,以及质量更好的结果。而这样我们对数据进行连续时间的扰动就可以被建模成一个随机微分方程 (stochastic differential equation, SDE)。 | ||
|
|
||
| 下面的动图演示将不再是一个一个离散的加噪声过程,而是连续加噪声的过程。 | ||
|
|
||
| 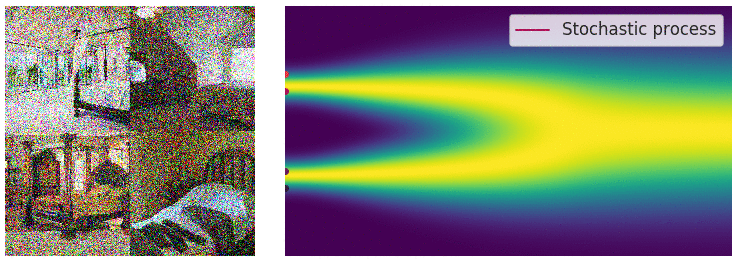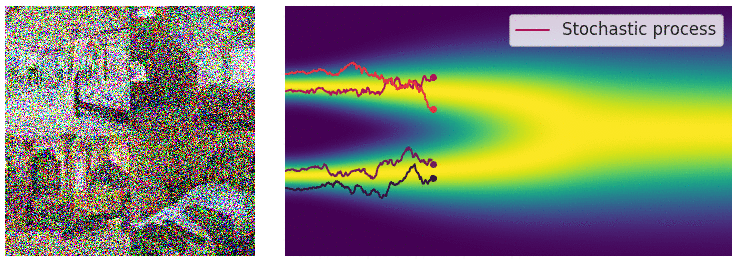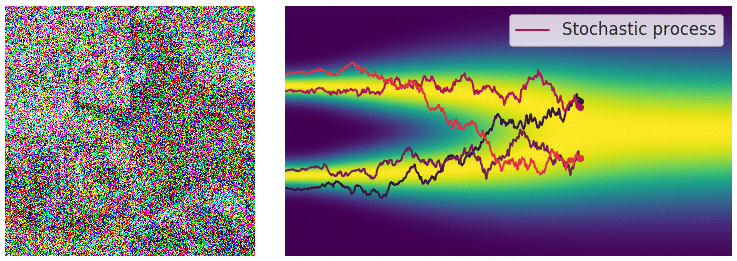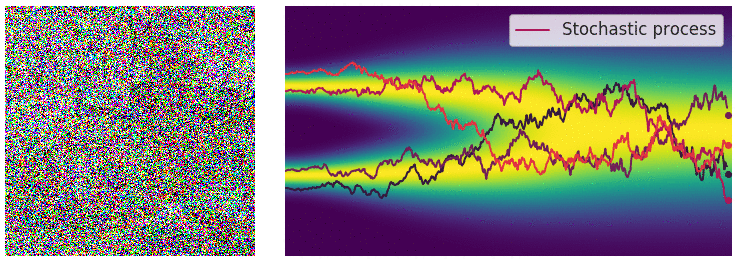 | ||
|
|
||
| SDE的形式有很多种,宋飏博士在论文中给出的一种形式 (可以算作是**Diffusion-Type SDE**,要求系数只与时间t和当前时刻取值$x$有关) 是: | ||
| $$ | ||
| \mathrm{d} \boldsymbol{x} = f(\boldsymbol{x},t) \mathrm{d} t + g(t) \mathrm{d} \boldsymbol{w} \tag{15} | ||
| $$ | ||
| 其中 $f(\cdot)$ 被称为 漂移系数 (drift coefficient),$g(t)$ 被称为 扩散系数 (diffusion coefficient),$\boldsymbol{w}$ 是一个标准的布朗运动,$\mathrm{d}\boldsymbol{w}$ 就可以被看成是一个白噪声。这个随机微分方程的解就是一组连续的随机变量 $\{\boldsymbol{x}(t)\}_{t\in[0, T]}$,这里 $t$ 就是把上面的离散形式 ($1, 2, \dots, T$) 连续化,同时用 $p_t(\boldsymbol{x})$ 表示 $\boldsymbol{x}(t)$ 的概率密度函数,这也和前面的 $p_{\sigma_t}\left(\boldsymbol{x}_t\right)$ 能对应上,$p_0(\boldsymbol{x})=p(\boldsymbol{x})$ 是原数据分布,$p_T(\boldsymbol{x})=\mathcal{N}(\mathbf{0}, \mathbf{I})$ 是加噪声扰动到最后变成了白噪声。 | ||
|
|
||
| 我们来看DDPM和SDE的联系,在上一篇文章中我们得到过前向过程的传递公式 (这里得用 $\beta$ 的形式,同时为了和下面公式中的 $t$ 区分,这里改写为下标 $i$): | ||
| $$ | ||
| \boldsymbol{x}_i = \sqrt{1-\beta_i} \boldsymbol{x}_{i-1} + \sqrt{\beta_i} \boldsymbol{\varepsilon}_{i-1}, \quad \boldsymbol{\varepsilon}_{i-1} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \tag{16} | ||
| $$ | ||
| 这是一个离散过程,如何连续化得到SDE呢?$\boldsymbol{x}_{i-1}$ 到 $\boldsymbol{x}_{i}$ 是稀疏相邻的两个变量过程,我们可以让稀疏的分布变稠密一点,对变量索引除以 $T$ ($T$ 趋向于无穷大),这样变量索引就从 $i \in \{0, 1,\dots, T\}$ 变成了 $t \in \{0, \frac{1}{T}, \dots, \frac{T-1}{T}, 1\}$,如下图所示: | ||
|
|
||
|  | ||
|
|
||
| 接着我们做一些变换: | ||
| $$ | ||
| \boldsymbol{x}_{i-1} \rightarrow \boldsymbol{x}^\prime(t), \ \boldsymbol{\varepsilon}_{i-1} \rightarrow \boldsymbol{\varepsilon}^\prime(t),\ \boldsymbol{x}_{i} \rightarrow \boldsymbol{x}^\prime(t+\frac{1}{T}), \ \beta_i \rightarrow \frac{1}{T}\beta^\prime(t+\frac{1}{T}) | ||
| $$ | ||
|
|
||
| > 上述变换里,只有最后一个 $\beta_i$ 有一个 $N$ 倍的放缩,这是为了后面能配凑出 $\Delta t$。 | ||
| 此刻的 $\Delta t = \frac{1}{T}$,那么我们现在就可以改写式(16):(其实加不加 $^\prime$ 都一样) | ||
|
|
||
| $$ | ||
| \begin{aligned} | ||
| \boldsymbol{x}^\prime(t+\frac{1}{T}) &= \sqrt{1-\frac{1}{T}\beta^\prime(t+\frac{1}{T})}\boldsymbol{x}^\prime(t) + \sqrt{\frac{1}{T}\beta^\prime(t+\frac{1}{T})} \boldsymbol{\varepsilon}^\prime(t) \\ | ||
| \boldsymbol{x}(t + \Delta t) &= \sqrt{1-\beta(t + \Delta t)\Delta t} \boldsymbol{x}(t) + \sqrt{\beta(t + \Delta t)\Delta t} \boldsymbol{\varepsilon}(t) | ||
| \end{aligned} \tag{17} | ||
| $$ | ||
|
|
||
| 借助一阶泰勒展开的结论 $\sqrt{1-x} \approx 1 - \frac{x}{2}$,式(17)就可以写成: | ||
| $$ | ||
| \begin{aligned} | ||
| \boldsymbol{x}(t + \Delta t) &\approx \left[1-\frac{\beta(t + \Delta t)\Delta t}{2}\right] \boldsymbol{x}(t) + \sqrt{\beta(t + \Delta t)\Delta t} \boldsymbol{\varepsilon}(t) \\ | ||
| \boldsymbol{x}(t + \Delta t) - \boldsymbol{x}(t) &\approx -\frac{\beta(t + \Delta t)\Delta t}{2}\boldsymbol{x}(t) + \sqrt{\beta(t + \Delta t)\Delta t} \boldsymbol{\varepsilon}(t) \\ | ||
| \mathrm{d} \boldsymbol{x}(t) &\approx -\frac{\beta(t)\Delta t}{2}\boldsymbol{x}(t) + \sqrt{\beta(t)\Delta t} \boldsymbol{\varepsilon}(t) \\ | ||
| \mathrm{d} \boldsymbol{x}(t) &\approx -\frac{\beta(t)\boldsymbol{x}(t)}{2}\mathrm{d} t + \sqrt{\beta(t)} \sqrt{\mathrm{d} t} \boldsymbol{\varepsilon}(t) | ||
| \end{aligned} \tag{18} | ||
| $$ | ||
| 这样我们就推导出了形如式(15)的结果: | ||
| $$ | ||
| \mathrm{d} \boldsymbol{x} = -\frac{\beta(t)\boldsymbol{x}}{2} \mathrm{d} t + \sqrt{\beta(t)} \mathrm{d} \boldsymbol{w} \tag{19} | ||
| $$ | ||
| **前面离散过程里,我们采用朗之万动力学采样生成新样本。那这里我们推导了正向过程的SDE,要想生成样本,需要的是逆向过程,Reverse SDE有没有呢?有!一个SDE的逆向过程依旧是一个SDE,表达式为:** | ||
| $$ | ||
| \mathrm{d} \boldsymbol{x}=\left[f(\boldsymbol{x}, t)-g(t)^2 \color{red}{\nabla \log p_t(\boldsymbol{x})}\right] \mathrm{d} t+g(t) \mathrm{d} w \tag{20} | ||
| $$ | ||
| 求解上面这个方程就能得到一个 score-based generative model。红色标记部分是不是就是前面我们讲到的score function,也就是说的确我们的任务就是要估计这个score function,和前面一致地训练一个网络来近似 $f_\theta(\boldsymbol{x},t) \approx \nabla \log p_t(\boldsymbol{x})$。重写一下连续过程下的式(11): | ||
| $$ | ||
| \underset{\boldsymbol{\theta}}{\arg \min } \ \mathbb{E}_{t\in U(0,T)} \mathbb{E}_{p_{t}\left(\boldsymbol{x}\right)} \left[\lambda(t) \left\|s_{\theta}(\boldsymbol{x}, t)-\nabla \log p_{t}\left(\boldsymbol{x}\right)\right\|_2^2\right] \tag{21} | ||
| $$ | ||
| 这个目标函数的求解依旧采用前面提及到的“score matching”方法。逆向过程用一个示意图来展示 | ||
|
|
||
| 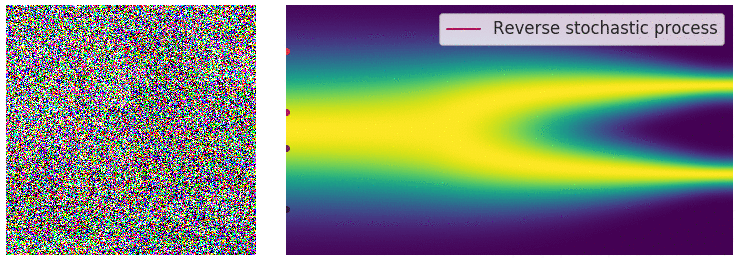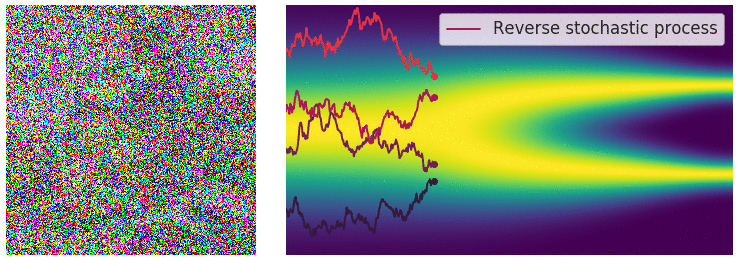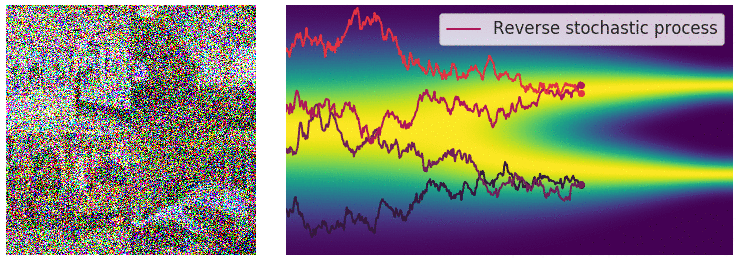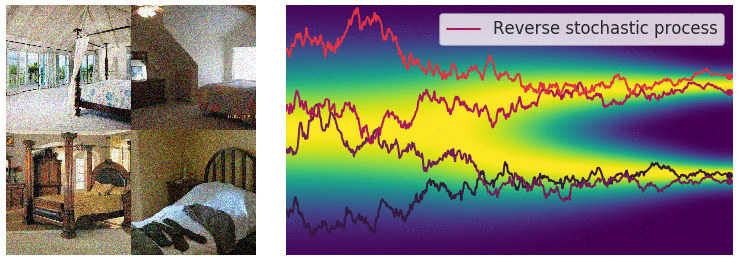 | ||
|
|
||
| 而关于常微分方程 (ordinary differential equation (ODE)),在原论文中展示了从SDE到ODE的转换,一方面我们可以借助更多的ODE求解器来帮助快速求解 (ODE因为没有随机性,因此可以用更大的步长来求解),同时能帮助我们计算更准确的对数似然。式(20)对应的ODE展示如下: | ||
| $$ | ||
| \mathrm{d} \boldsymbol{x}=\left[\mathbf{f}(\boldsymbol{x}, t)-\frac{1}{2}g(t)^2 \nabla \log p_t(\boldsymbol{x})\right] \mathrm{d} t \tag{22} | ||
| $$ | ||
| 以及展示一个SDE|ODE正向和逆向过程的示意图,ODE是白线表示,显得更加稳定,同时他们俩得到的分布是一样的。 | ||
|
|
||
| 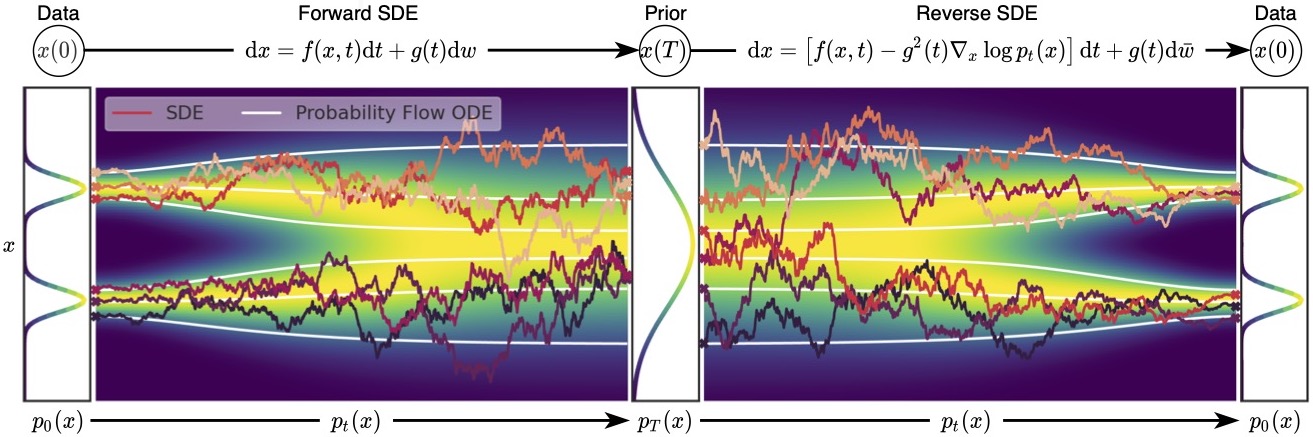 | ||
|
|
||
| 从DDPM的角度不好推出条件概率的形式,也就不好表示可控生成 (conditional generation)。从SDE的角度将能很好地解决这个麻烦。借由贝叶斯定理: | ||
| $$ | ||
| p(\boldsymbol{x} \mid \boldsymbol{y})=\frac{p(\boldsymbol{x}) p(\boldsymbol{y} \mid \boldsymbol{x})}{p(\boldsymbol{y})} \tag{23} | ||
| $$ | ||
| 两边同时对 求偏导得到: | ||
| $$ | ||
| \nabla \log p(\boldsymbol{x} \mid \boldsymbol{y})=\nabla \log p(\boldsymbol{x})+\nabla \log p(\boldsymbol{y} \mid \boldsymbol{x}) \tag{24} | ||
| $$ | ||
| 后两项我们都是可以估计的score function,因此我们可以通过Langevin-MCMC生成 。 | ||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
| 参考 | ||
|
|
||
| https://yang-song.net/blog/2021/score/ | ||
|
|
||
| https://zhuanlan.zhihu.com/p/576779879 | ||
|
|
||
| [Understanding Diffusion Models: A Unified Perspective](https://arxiv.org/abs/2208.11970) | ||
|
|
This file was deleted.
Oops, something went wrong.
Oops, something went wrong.